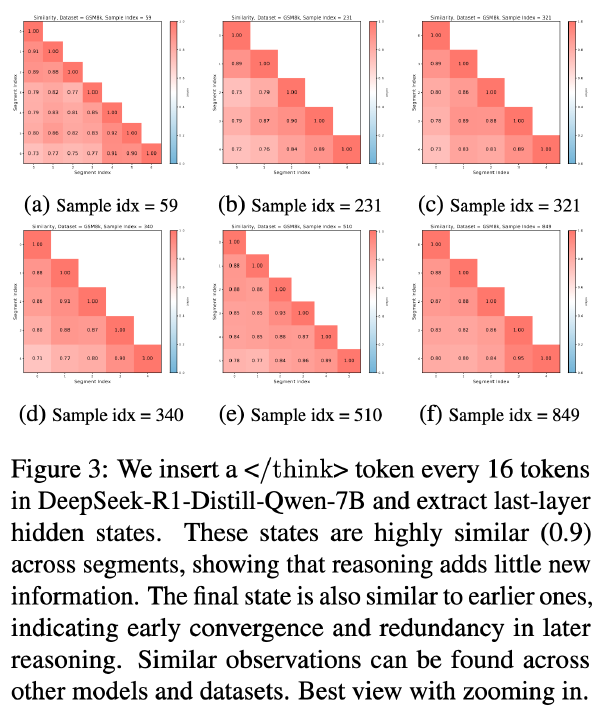
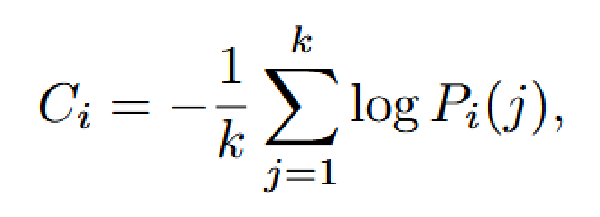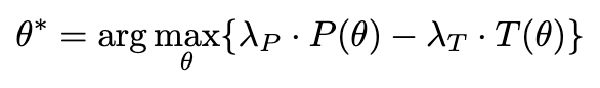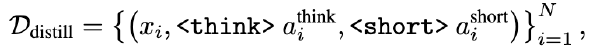面向大语言模型的门控注意力机制:非线性、稀疏性和Attention-Sink-Free2025 Dec 6·3585 字·8 分钟算法 论文 论文 算法面向大语言模型的门控注意力机制:非线性、稀疏性和 Attention-Sink-Free #
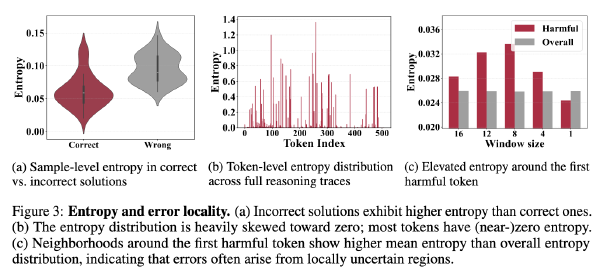
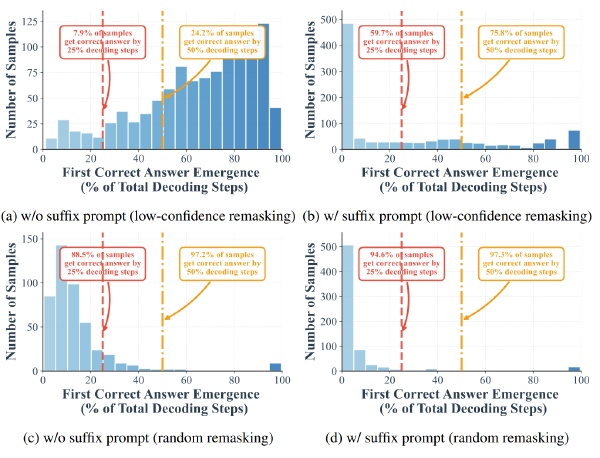
Saber:一种针对扩散语言模型的自适应加速与回溯增强的高效采样方法2025 Nov 7·1125 字·3 分钟算法 论文 论文 算法Saber:一种针对扩散语言模型的自适应加速与回溯增强的高效采样方法 # Saber: An Efficient Sampling with Adaptive Acceleration and Backtracking Enhanced Remasking for Diffusion Language Model
R-STITCH:用于高效推理的动态轨迹拼接2025 Nov 7·1361 字·3 分钟算法 论文 论文 算法R-STITCH:用于高效推理的动态轨迹拼接 # R-STITCH: DYNAMIC TRAJECTORY STITCHING FOR EFFICIENT REASONING
真-Self-Spec-DLM2025 Nov 7·1439 字·3 分钟算法 论文 论文 算法真-Self-Spec-DLM # SELF SPECULATIVE DECODING FOR DIFFUSION LARGE LANGUAGE MODELS
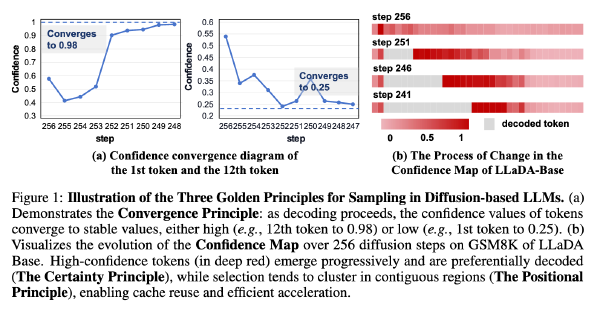
SlowFast采样加速DLM2025 Nov 7·1866 字·4 分钟算法 论文 论文 算法SlowFast 采样加速 DLM # ACCELERATING DIFFUSION LARGE LANGUAGE MODELS WITH SLOWFAST SAMPLING: THE THREE GOLDEN PRINCIPLES
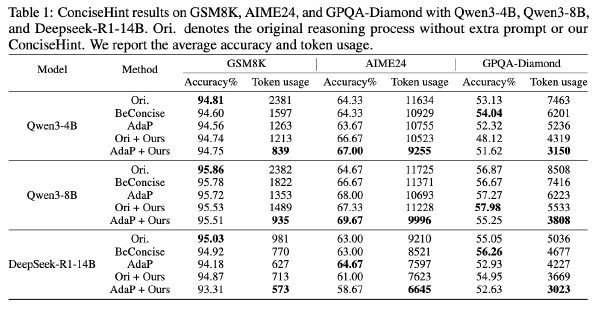
简洁提示:通过生成过程中的连续简洁提示提升推理效率2025 Oct 10·1556 字·4 分钟算法 论文 论文 算法 CoT压缩简洁提示:通过生成过程中的连续简洁提示提升推理效率 # ConciseHint: Boosting Efficient Reasoning via Continuous Concise Hints during Generation
Prophet:Diffusion模型基于置信度的Decoding早停2025 Oct 10·1543 字·4 分钟算法 论文 论文 算法 Diffusion DLLMProphet:Diffusion 模型基于置信度的 Decoding 早停 # Prophet: Fast Decoding for Diffusion Language Models
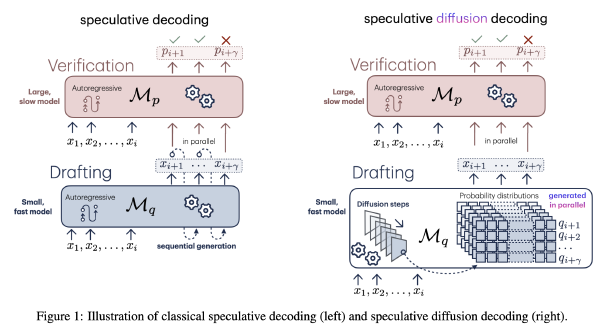
SpecDiff:使用扩散模型作为Draft模型2025 Oct 10·1356 字·3 分钟算法 论文 论文 算法 Diffusion DLLM SpecSpecDiff:使用扩散模型作为 Draft 模型 # Speculative Diffusion Decoding: Accelerating Language Generation through Diffusion
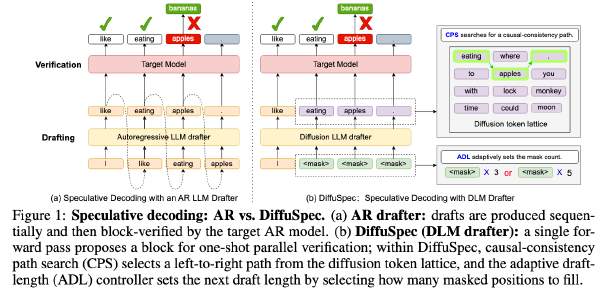
DiffuSpec:解锁DLM做投机采样2025 Oct 10·2609 字·6 分钟算法 论文 论文 算法 Diffusion DLLM SpecDiffuSpec:解锁 DLM 做投机采样 # DIFFUSPEC: UNLOCKING DIFFUSION LANGUAGE MODELS FOR SPECULATIVE DECODING
后端部署第二步:本地到公网——如何使用 Nginx 发布 FastAPI 服务2025 Sep 5·1668 字·4 分钟开发 运维 FastAPI Nginx 部署 Python后端 Web服务配置后端部署第二步:本地到公网——如何使用 Nginx 发布 FastAPI 服务 # 在当今的开发环境中,快速构建和部署后端服务变得至关重要。FastAPI 作为一个高性能、现代化的 Python 异步 Web 框架,广受开发者喜爱。而 Nginx 则是部署 Web 应用最常见也是最稳定的解决方案之一。
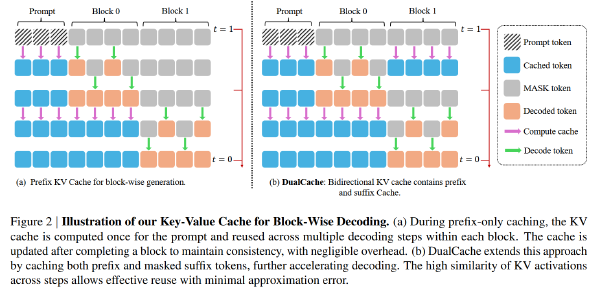
Fast-dLLM:通过KV Cache和并行Decoding加速dLLM2025 Sep 5·2003 字·4 分钟算法 论文 论文 算法 Diffusion DLLMFast-dLLM:通过 KV Cache 和并行 Decoding 加速 dLLM # Fast-dLLM: Training-free Acceleration of Diffusion LLM by Enabling KV Cache and Parallel Decoding
后端部署第一步:Nginx 发布服务前的万全准备2025 Sep 3·1594 字·4 分钟开发 运维 后端 Nginx 服务器 部署后端部署第一步:Nginx 发布服务前的准备工作 # 你是不是刚刚用 Java、Python 或 Go 写出了第一个后端程序?它在本地跑得飞快,通过 localhost:8080 就能访问,功能也都挺顺畅。接下来,自然而然会冒出一个念头:“我要怎样才能让别人也能访问到它?”
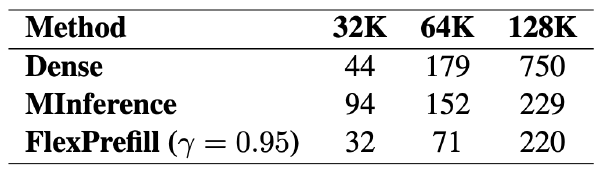
TriangleMix:无损且高效的用于预填充阶段的注意力模式2025 Sep 2·2323 字·5 分钟算法 论文 论文 算法 CoT压缩TriangleMix:无损且高效的用于预填充阶段的注意力模式 # TriangleMix: A Lossless and Efficient Attention Pattern for Long Context Prefilling
ASC:CoT压缩的激活引导 Training free2025 Sep 2·1854 字·4 分钟算法 论文 论文 算法 CoT压缩ASC:CoT 压缩的激活引导 Training free # Activation Steering for Chain-of-Thought Compression
SEAL:大语言模型的可操控推理 Traning Free2025 Sep 2·2081 字·5 分钟算法 论文 论文 算法 CoT压缩SEAL:大语言模型的可操控推理 Traning Free # SEAL: Steerable Reasoning Calibration of Large Language Models for Free
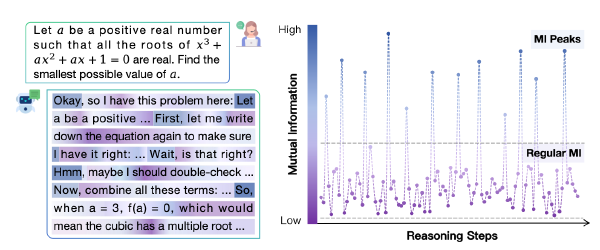
Hmm等Token影响模型推理能力2025 Sep 2·2840 字·6 分钟算法 论文 论文 算法 CoT压缩Hmm 等 Token 影响模型推理能力 # Demystifying Reasoning Dynamics with Mutual Information: Thinking Tokens are Information Peaks in LLM Reasoning
AdaCoT:通过强化学习实现的帕累托最优自适应链式思维触发器2025 Sep 2·1472 字·3 分钟算法 论文 论文 算法 CoT压缩AdaCoT:通过强化学习实现的帕累托最优自适应链式思维触发器 # AdaCoT: Pareto-Optimal Adaptive Chain-of-Thought Triggering via Reinforcement Learning
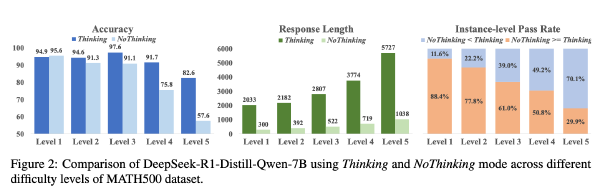
AdaptThink: 让模型决定是否思考2025 Sep 2·1806 字·4 分钟算法 论文 论文 算法 CoT压缩AdaptThink: 让模型决定是否思考 # AdaptThink: Reasoning Models Can Learn When to Think
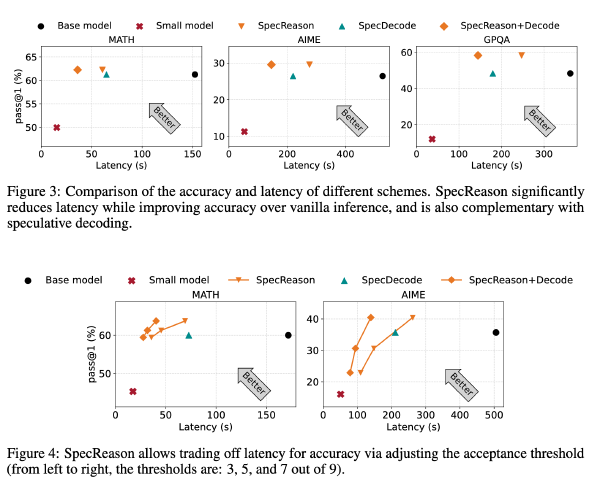
SpecReason:使用推测性推理实现加速推理2025 Sep 2·1229 字·3 分钟算法 论文 论文 算法 CoT压缩SpecReason:使用推测性推理实现加速推理 # SpecReason: Fast and Accurate Inference-Time Compute via Speculative Reasoning
ThinkLess:一种无需训练的推理高效方法,用于减少推理冗余2025 Sep 2·941 字·2 分钟算法 论文 论文 算法 CoT压缩ThinkLess:一种无需训练的推理高效方法,用于减少推理冗余 # ThinkLess: A Training-Free Inference-Efficient Method for Reducing Reasoning Redundancy
Thinkless: LLM Learns When to Think2025 Sep 2·1167 字·3 分钟算法 论文 论文 算法 CoT压缩Thinkless: LLM Learns When to Think # Thinkless: LLM Learns When to Think
🧠思维操控:外部CoT辅助大模型推理2025 Sep 2·1480 字·3 分钟算法 论文 论文 算法 CoT压缩🧠 思维操控:外部 CoT 辅助大模型推理 # Thought Manipulation: External Thought Can Be Efficient for Large Reasoning Models
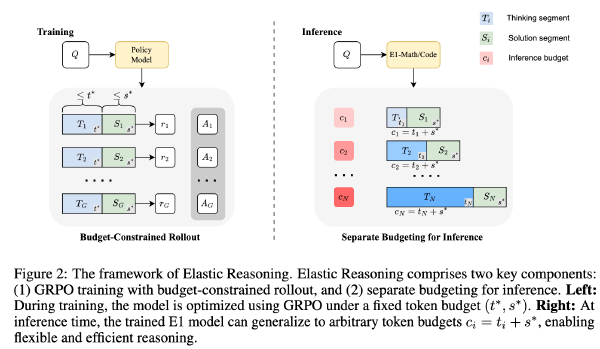
⏰开始作答:弹性推理实现的可扩展的CoT2025 Sep 2·1378 字·3 分钟算法 论文 论文 算法 CoT压缩⏰ 开始作答:弹性推理实现的可扩展的 CoT # Scalable Chain of Thoughts via Elastic Reasoning
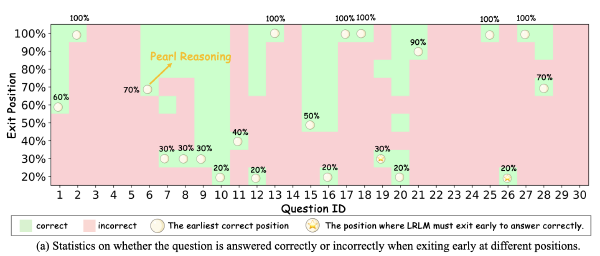
DEER:基于Trial置信度的推理早停2025 Sep 2·1675 字·4 分钟算法 论文 论文 算法 CoT压缩DEER:基于 Trial 置信度的推理早停 # DYNAMIC EARLY EXIT IN REASONING MODELS
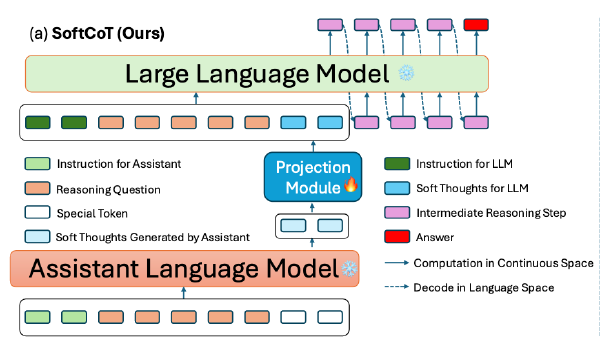
SoftCoT:Prompt➡️SLM➡️LLM2025 Sep 2·1168 字·3 分钟算法 论文 论文 算法 CoT压缩SoftCoT:Prompt➡️SLM➡️LLM # SoftCoT: Soft Chain-of-Thought for Efficient Reasoning with LLMs
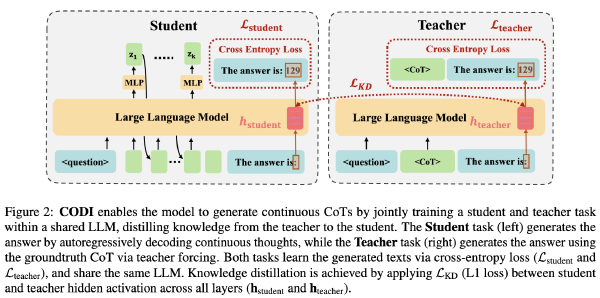
CODI: 通过自蒸馏将CoT压缩到连续空间中2025 Sep 2·1122 字·3 分钟算法 论文 论文 算法 CoT压缩CODI: 通过自蒸馏将 CoT 压缩到连续空间中 # CODI: Compressing Chain-of-Thought into Continuous Space via Self-Distillation
HAWKEYE:大小模型协作实现精简CoT2025 Sep 2·1502 字·3 分钟算法 论文 论文 算法 CoT压缩HAWKEYE:大小模型协作实现精简 CoT # Hawkeye:Efficient Reasoning with Model Collaboration
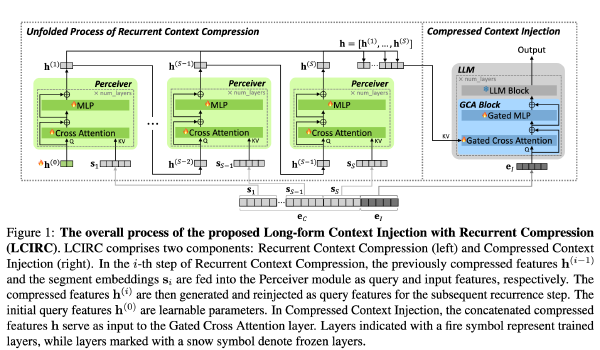
LCIRC: 长文档循环压缩方法 (LLM Training Free)2025 Sep 2·1445 字·3 分钟算法 论文 论文 算法 CoT压缩LCIRC: 长文档循环压缩方法 (LLM Training Free) # LCIRC: A Recurrent Compression Approach for Efficient Long-form Context and Query Dependent Modeling in LLMs
LLM在连续Latent空间中推理2025 Sep 2·2096 字·5 分钟算法 论文 论文 算法 CoT压缩LLM 在连续 Latent 空间中推理 # Training Large Language Models to Reason in a Continuous Latent Space
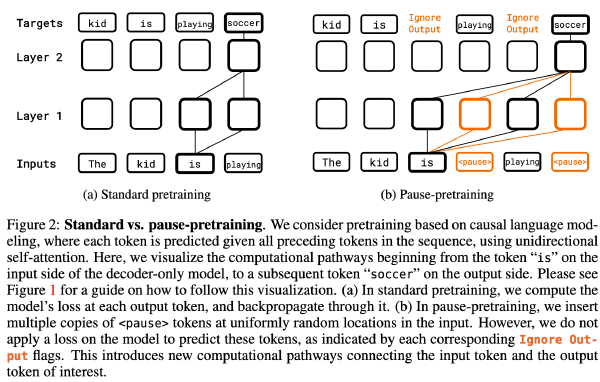
Pause Token:隐式CoT2025 Sep 2·1600 字·4 分钟算法 论文 论文 算法 CoT压缩Pause Token:隐式 CoT # Think before you speak: Training Language Models With Pause Tokens
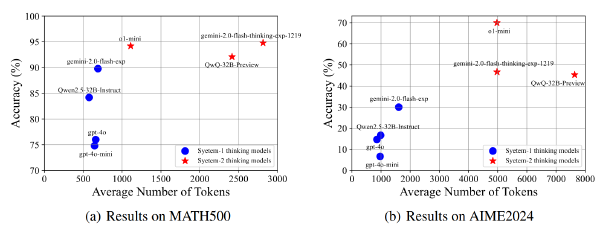
面向模型推理思考优化的Test time scaling2025 Sep 2·2784 字·6 分钟算法 论文 论文 算法 CoT压缩面向模型推理思考优化的 Test time scaling # Towards Thinking-Optimal Scaling of Test-Time Compute for LLM Reasoning
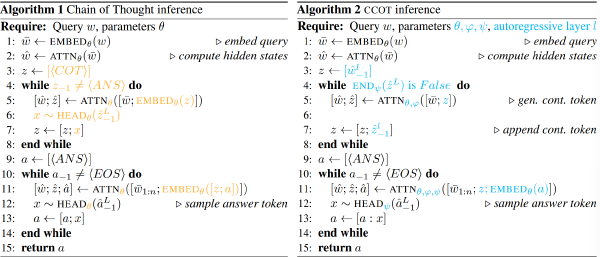
CCoT:通过密集表示实现高效推理2025 Sep 2·1773 字·4 分钟算法 论文 论文 算法 CoT压缩CCoT:通过密集表示实现高效推理 # Compressed Chain of Thought: Efficient Reasoning Through Dense Representations
Token预算意识的llm推理2025 Sep 2·1535 字·4 分钟算法 论文 论文 算法 CoT压缩Token 预算意识的 llm 推理 # Token-Budget-Aware LLM Reasoning
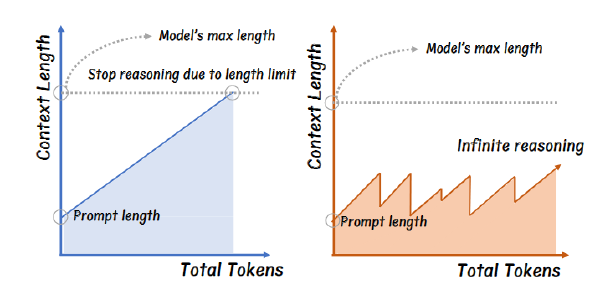
INFTYTHINK:打破大型语言模型长上下文推理长度限制2025 Sep 2·3139 字·7 分钟算法 论文 论文 算法 CoT压缩INFTYTHINK:打破大型语言模型长上下文推理长度限制 # InftyThink: Breaking the Length Limits of Long-Context Reasoning in Large Language Models
TokenSkip:可控的CoT压缩 in LLMs2025 Sep 2·787 字·2 分钟算法 论文 论文 算法 CoT压缩TokenSkip:可控的 CoT 压缩 in LLMs # TokenSkip: Controllable Chain-of-Thought Compression in LLMs
LightThinker: 每个想法压缩成两个token2025 Sep 2·2304 字·5 分钟算法 论文 论文 算法 CoT压缩LightThinker: 每个想法压缩成两个 token # 如果 lt 确实靠谱