⏰ 开始作答:弹性推理实现的可扩展的 CoT#
Scalable Chain of Thoughts via Elastic Reasoning
这篇文章给我的感觉就像让 LRM 参与面试 一般的 LRM 会尽可能长时间思考,确保答案正确,最后给出答案 但是这篇文章的 LRM 会思考一段时间,当面试官说“注意时间”的时候 LRM 就强行终止思考,基于已经思考的内容给出答案
其实我更想看一下经过这样处理以后模型的 Reasoning 过程会变成什么样子,会不会更抽象更简洁概括,可惜的是作者并没有放出来
摘要#
大型推理模型(LRMs)通过生成扩展的思维链(CoT)在复杂任务上取得了显著进展。然而,其不受控的输出长度为实际部署带来了重大挑战,在实际应用中,对 tokens、延迟或计算资源的推理时间预算有着严格的限制。我们提出了弹性推理(Elastic Reasoning),这是一种可扩展的思维链框架,明确将推理过程分为两个阶段——思考和解决方案,并分别为这两个阶段分配独立的预算。在测试时,弹性推理优先保证解决方案部分的完整性,从而在资源受限的情况下显著提高了可靠性。我们引入了一种轻量级的预算约束 rollout 策略来训练出对截断思考过程具有鲁棒性的模型,并将其整合到 GRPO 中,该方法教导模型在思考过程被中断时进行自适应推理,并能够有效泛化到未见过的预算约束,而无需额外训练。在数学(AIME、MATH500)和编程(LiveCodeBench、Codeforces)基准测试中的实证结果表明,弹性推理在严格预算约束下表现出稳健性,同时相比基线方法大幅降低了训练成本。值得注意的是,即使在无约束条件下,我们的方法也能生成更简洁和高效的推理过程。
动机#
- 推理长度过长消耗资源
- 目前已有方法(Long2Short 和 Length Control)会显著降低模型性能
方法#
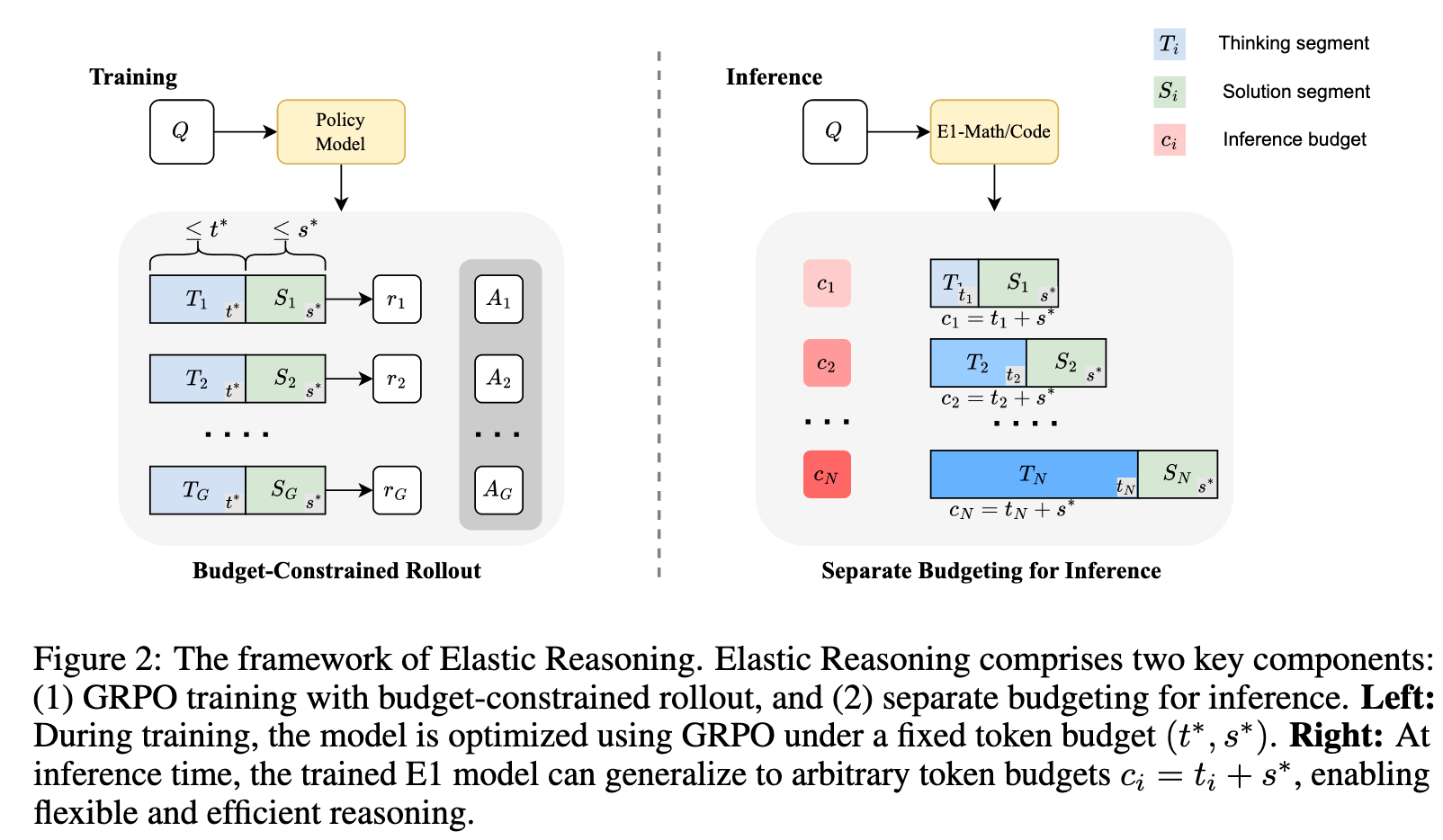
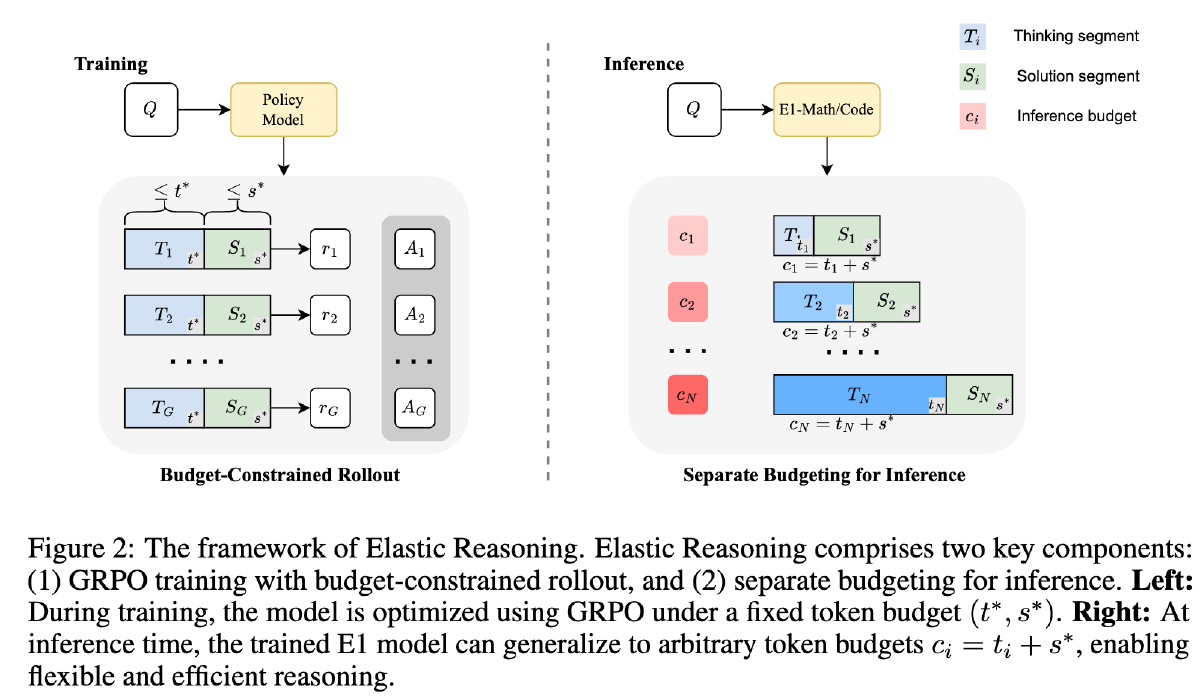
提出“预算分配”,将总预算 c 分为 t 和 s(t 和 s 是两个超参)两个部分,t 代表思考,s 代表解决方案。并且当推理用光 t 的预算后,就添加一个来强行终止推理
为了提升基于上述被截断的推理生成答案的性能,引入了一种新的训练策略,教导 model 在不完整的 CoT 基础上生成答案
训练#
首先基于 LRM 生成依次 think 和 solution,在生成 think 的过程中,如果 think 长度超出了 t,则强行添加转为生成解决方案。使用 GRPO 训练

推理#
同样采用上述方法控制 think 的长度
实验#
模型:DeepScaleR-1.5B-Preview、DeepCoder-14B-Preview
数据集:
训练
- 数学:AIME(1984-2023)、AMC、Omni-Math、STILL
- 编程:TACO、SYNTHETIC-1、LiveCodeBench
评测
- 数学:AIME2024、MATH500、AMC、Olympiad-Bench、Minerva Math
- 编程:LiveCodeBench、Codeforces、HumanEval+
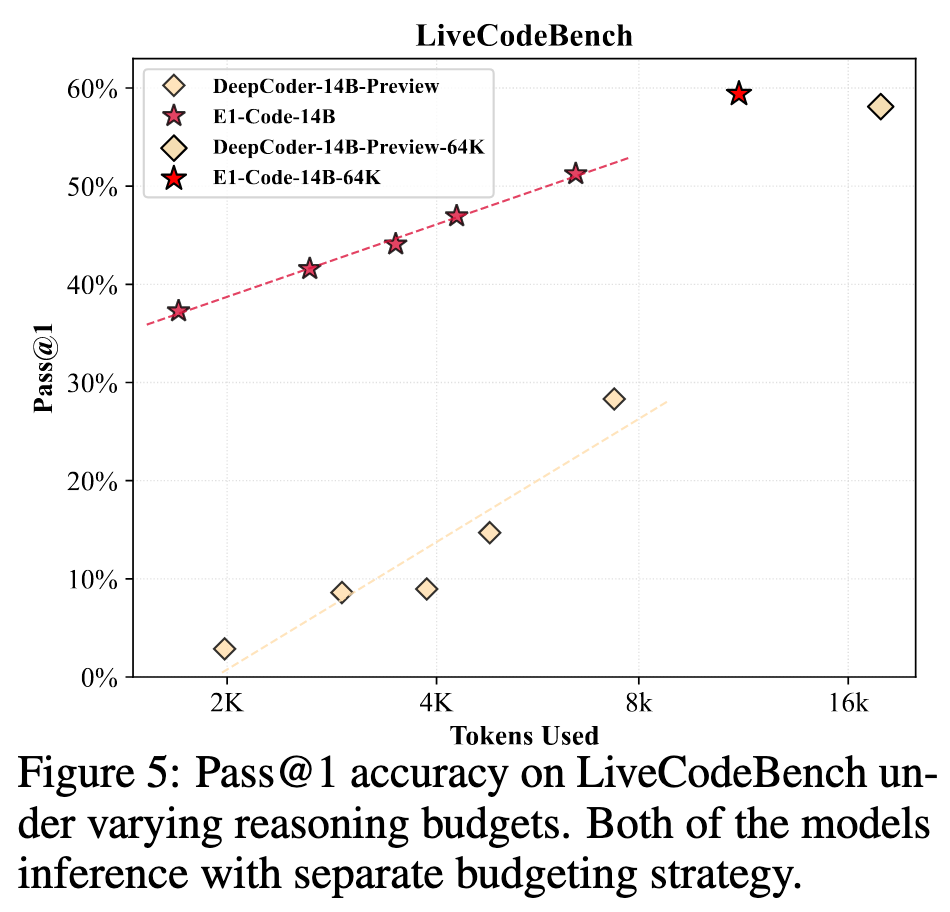
超参:训练时 t=s=1k;推理时 s=1k,t 测试了多组不同数据
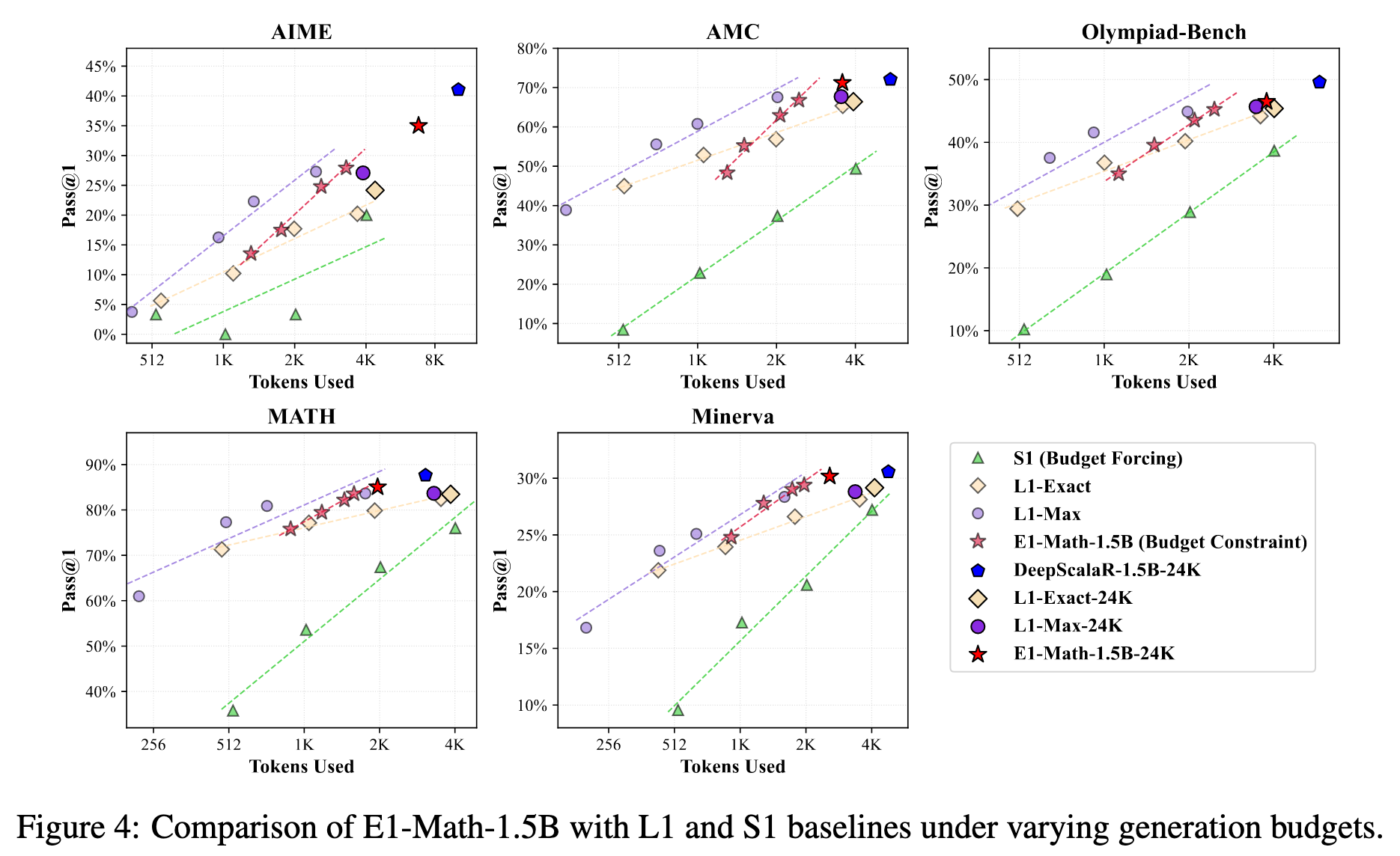
在数学上,始终优于 L1-Exact 和 S1,接近 L1-MAX(但是 E1 训练步骤少)。且当推理不设置预算的时候,其效果是除了原始模型外最佳的
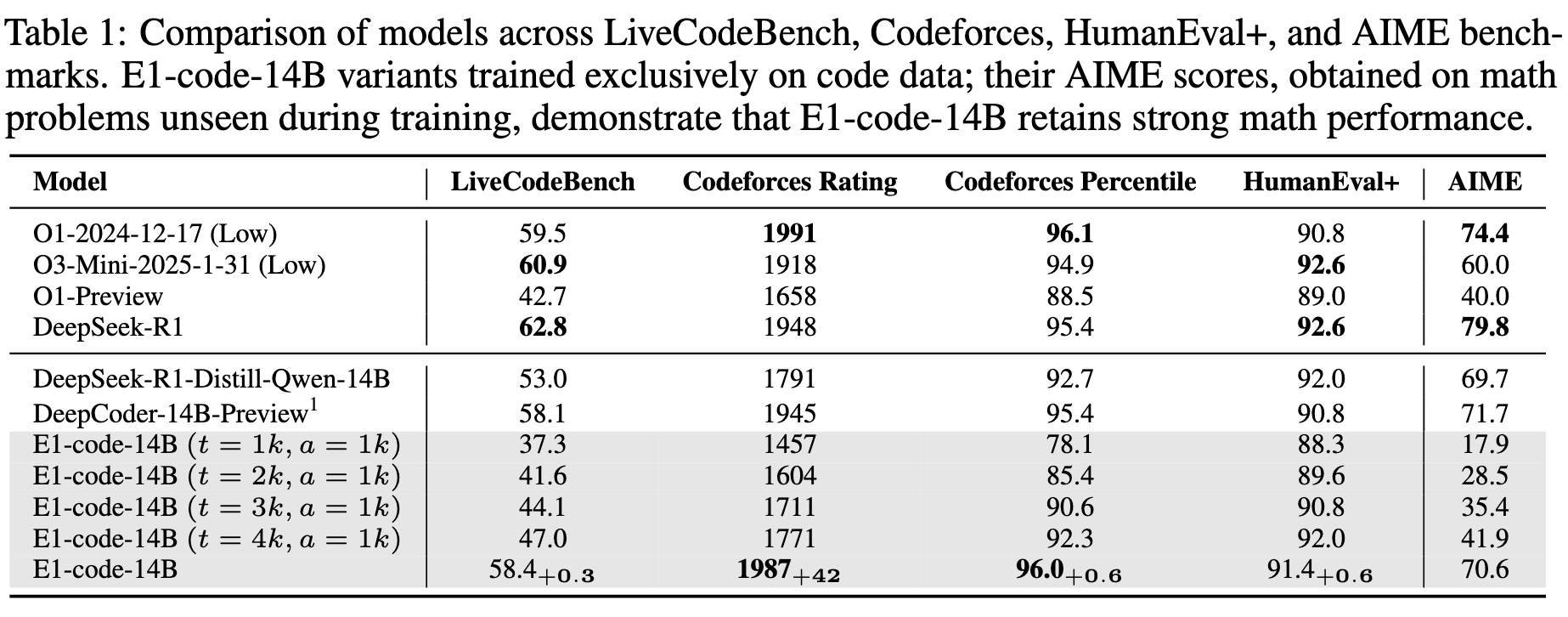
在编程问题上和原始模型打得有来有回