🧠 思维操控:外部 CoT 辅助大模型推理#
Thought Manipulation: External Thought Can Be Efficient for Large Reasoning Models
Training Free
摘要#
近期在大型推理模型(LRMs)方面的进展证明了扩展测试时计算规模能够提升多个任务中的推理能力。然而,LRMs 通常会遭受“过度思考”问题,即模型生成大量冗余的推理步骤,而这些步骤仅带来有限的性能提升。现有的工作依赖微调来缓解过度思考的问题,但这需要额外的数据、非传统的训练设置、可能引发的安全性错位风险,以及较差的泛化能力。
通过实证分析,我们揭示了 LRM 行为的一个重要特性:将由较小模型生成的外部 CoTs(链式思维)放置在思考标记(
Motivation#
- 计算资源
- 基于微调的方法通常需要额外的数据收集,从而导致成本增加。此外,微调可能会引发安全性的对齐问题
实证#
使用 LLM( Qwen-Max、Qwen-Plus、Qwen2.5-7B-Instruct 和 Qwen-2.5-3B-Instruct)生成推理,然后使用
生成推理的 Prompt: “If you are a teacher, you are listing the important key points for solving the problem and no calculation details should be included. You are not allowed to produce any final answer. Add
when the key points are finished. You may provide only very high-level ideas for solving the problem, no calculation details should be included.”

**发现使用 RL 的 LRM 在很多情况下仍然会再生成自己的推理链,**但是如果外部 CoT 是质量较高的(比如 Qwen-Max)生成的,那么 LRM 再自己推理的概率会小很多。
但是基于蒸馏的 LRM 很少会再生成自己的推理链,作者推测基于蒸馏的 LRMs 可能并未真正“理解”推理或思考的概念。相反,它们的行为主要由监督微调期间学到的模式跟随技能驱动。
方法#
- 使用 LLM 生成 high level 的 CoT
“If you are a teacher, you are listing the important key points for solving the problem and no calculation details should be included. You are not allowed to produce any final answer. Add
when the key points are finished. You may provide only very high-level ideas for solving the problem, no calculation details should be included. If you feel that you cannot solve it, output and return.”
- 如果 LLM 生成的 CoT 为空(Prompt 中写了如果模型觉得自己无法解决,那就直接输出 STOP),就抛弃掉 LLM 的 CoT 转而让 LRM 自行推理

实验#
数据集
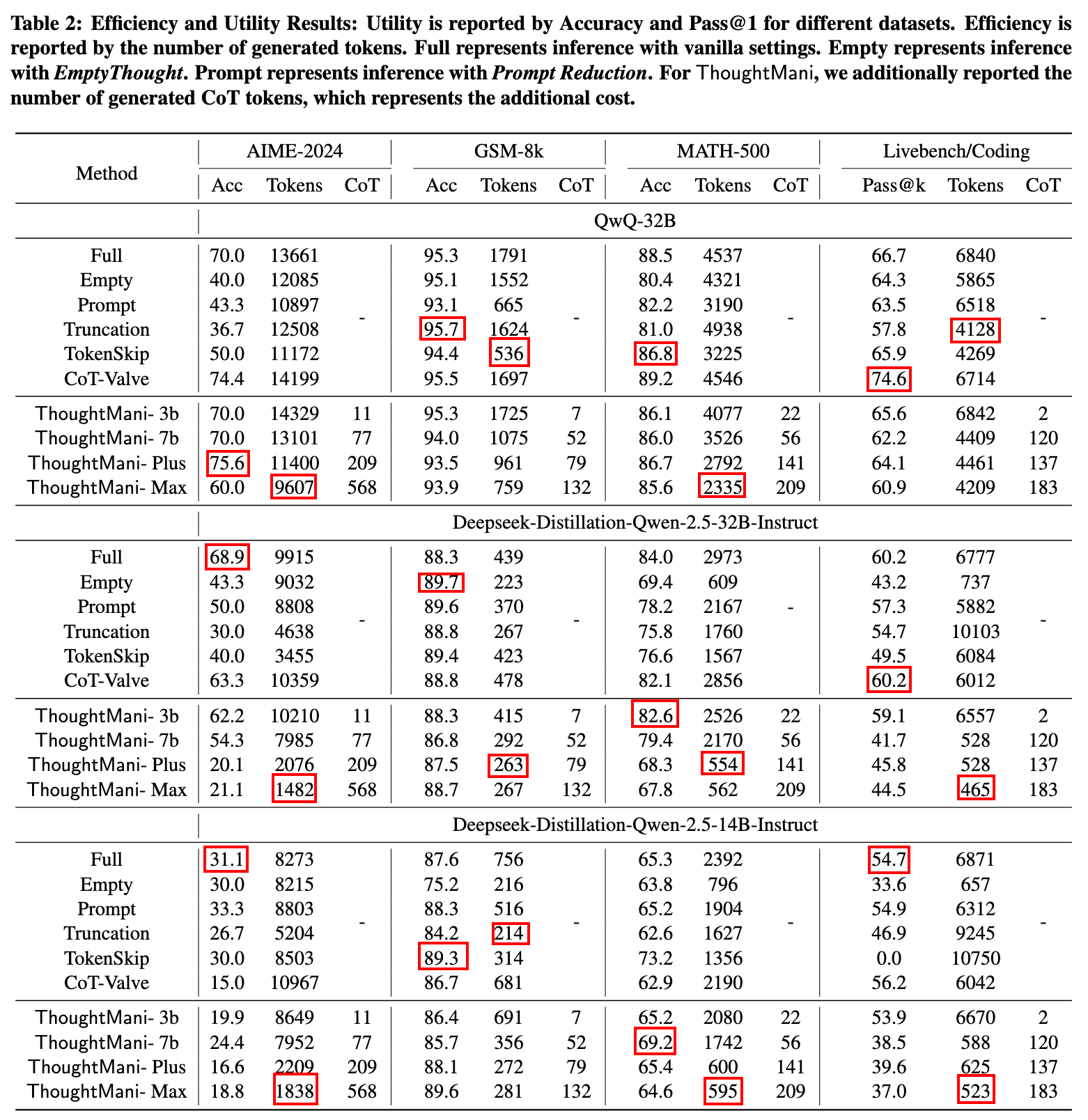
- 数学:AIME-2024、GSM-8k、MATH-500
- 编程:LiveBench
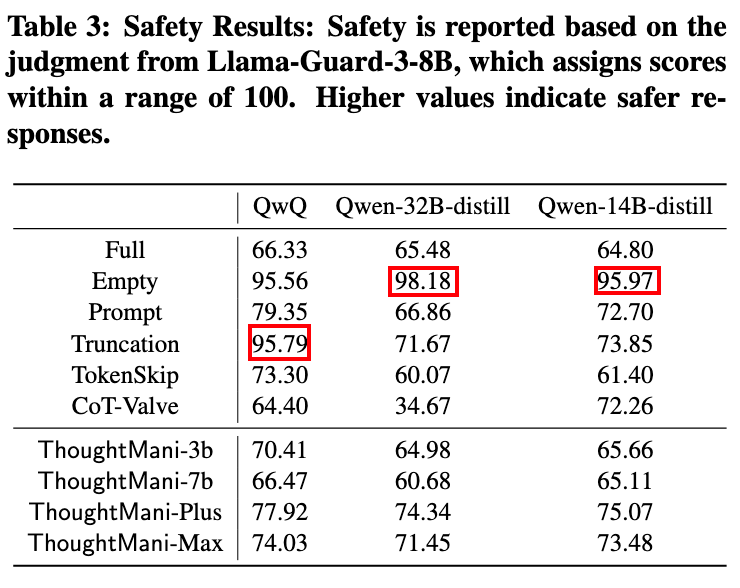
- 安全对齐:WildJailbreak
模型:
- CoT 模型:Qwen-Max, Qwen-Plus, Qwen-2.5-7B-Instruct, and Qwen-2.5-3B-Instruct.
- LRM:QwQ-32B(RL)、Deepseek-Distillation-Qwen-2.5-14B(32B)-Instruct(Distill)
- 模型均为 4-bit 量化版本
实验设置:
- 框架:vLLM
- 超参:temperature 0.7, top-k 0.95, maxlen 30000(AIME)、 20000 (Others)
Baselines:
- Empty Thought,将推理模型的 think 部分替换为空
- Truncation,在到达原 Reasoning 一半的长度时添加截断推理
- Prompt Reduction,(Let’s quickly conclude the answer without showing step-by-step reasoning.)
- 其他 CoT 压缩:Tokenskip、CoT-Valve