真-Self-Spec-DLM#
SELF SPECULATIVE DECODING FOR DIFFUSION LARGE LANGUAGE MODELS

摘要#
基于扩散的大语言模型(dLLMs)已成为自回归模型的一种有力替代方案,凭借双向注意力和并行生成范式展现出独特优势。然而,当前并行解码方法的生成结果与逐步解码存在偏差,可能导致性能下降,限制了其实际部署。为解决此问题,我们提出自推测解码(Self Speculative Decoding, SSD),这是一种无损推理加速方法,利用 dLLM 自身同时作为推测解码的起草器与验证器,无需额外辅助模块。SSD 引入了一种自起草机制,使模型能够对多个位置生成预测,并通过分层验证树在单次前向传播中完成验证。与传统需要独立起草模型的推测解码不同,SSD 通过挖掘 dLLM 本身对多个位置的并行预测能力,消除了模型冗余和内存开销。这种自推测机制使得模型可在一次前向传播中逐步验证并接受多个 token。实验表明,SSD 在 LLaDA 和 Dream 等开源模型上实现了最高达 3.46 倍的加速,同时保持输出与逐步解码完全一致。代码将公开于 GitHub。
Motivation#
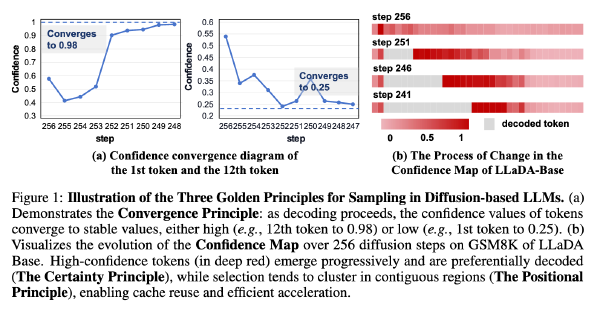
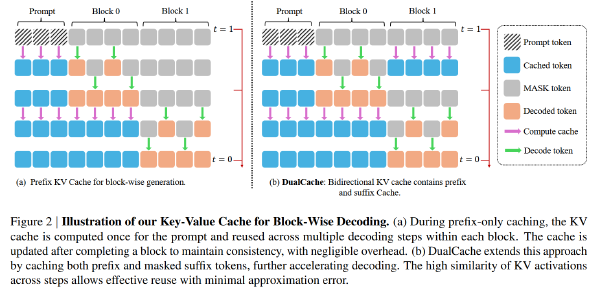
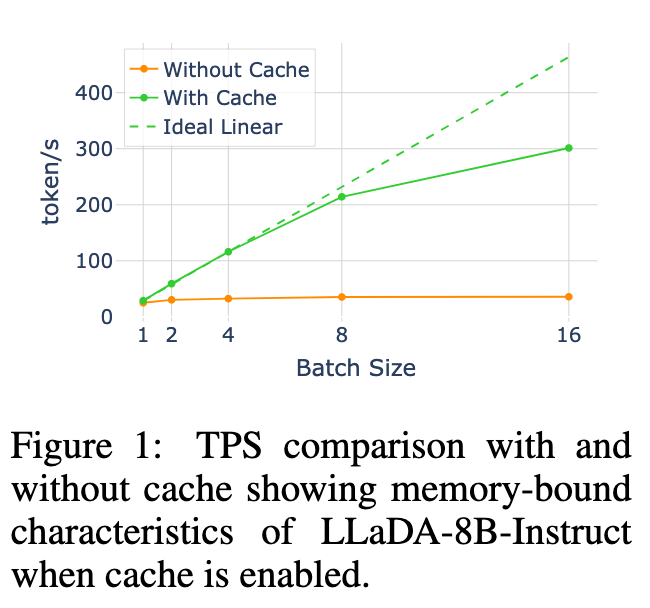
扩散语言模型(dLLMs)在推理效率方面仍面临挑战。与具备原生键值(KV)缓存支持的自回归模型(ARMs)不同,dLLMs 的双向注意力机制以及在去噪步骤中动态的 token 更新,阻碍了传统 KV 缓存策略的直接应用。如图 1 所示,在启用 Fast-dLLM(Wu et al., 2025)中的缓存时,dLLM 生成在中等批量大小(≤ 8)下表现出明显的内存受限特征,吞吐量扩展接近线性扩展,这为投机式解码方法(speculative decoding approaches)(Leviathan et al., 2023; Chen et al., 2023)创造了机会,此类方法可通过增加计算来降低延迟。
方法#
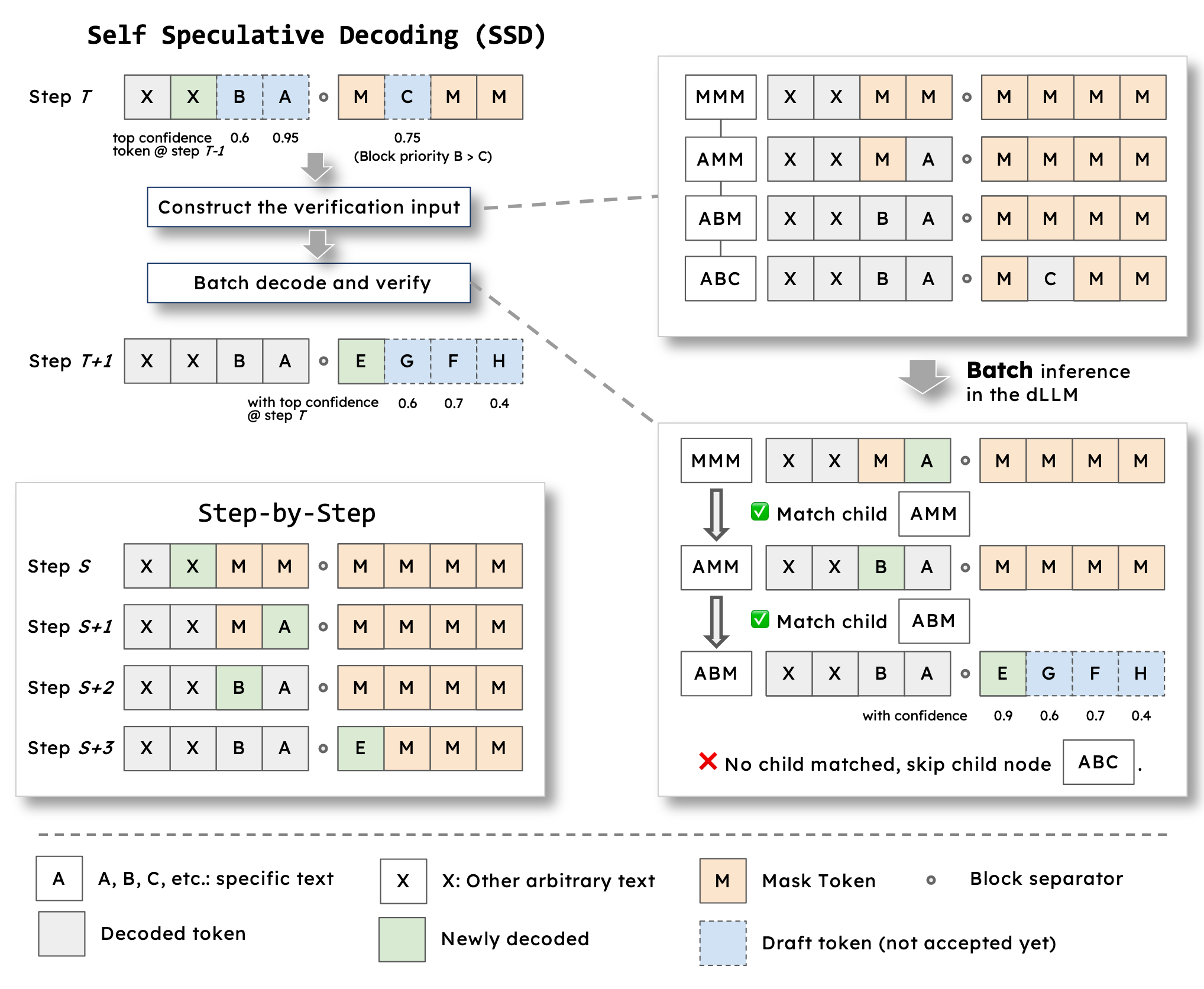
起草#
设起草长度 draft_len = 3
在 dlm 的一个 steps 中,并行 greedy decode 出 block 内置信度最高的 draft_len 个 token,如果 block 内的[MASK]数量小于 draft_len,则多出来的部分要从下一个 block 中 decode 出来
例如输入的 Token 是 BLOCK1: X [MASK] [MASK] [MASK] BLOCK2: [MASK] [MASK] [MASK] [MASK]
其中 BLOCK1 中红色[MASK]的置信度最高,按 step by step 的流程,红色[MASK]应当被 decode 出来,即:
BLOCK1: X X [MASK] [MASK] BLOCK2: [MASK] [MASK] [MASK] [MASK]
随着 X 被 decode 出来,所有[MASK]位置也获得了 logits,将按照 draft_len 进行起草
BLOCK1 中只有 2 个[MASK],则需要独立并行 Decode 出 Block1 中所有[MASK],并在同一个 step 中 decode 出 BLOCK2 中置信度最高的[MASK]
比如起草出来的 Token 是 BLOCK1: X X B A BLOCK2: [MASK] C [MASK] [MASK]
其中 B 的置信度为 0.6, A 的置信度为 0.95,C 的置信度为 0.75
验证#
根据起草部分的输入和输出构造要验证的内容。假设每一步只 decode 一个 token,则 draft 输入到输出每一步中间产物应当为:
draft 输入:X X [MASK] [MASK] [MASK] [MASK] [MASK] [MASK]
1:X X [MASK] A [MASK] [MASK] [MASK] [MASK] (因为 A 这个 token 在左侧 block 中,且置信度为 block 内最大)
2: X X B A [MASK] [MASK] [MASK] [MASK] (因为 B 这个 token 在左侧 block 中,尽管 C 的置信度更高,但应当按照半自回归的顺序解码)
3(draft 输出):X X B A [MASK] C [MASK] [MASK]
将上述的 0123 组合起来,构造一个 batch:
[
[X, X, [MASK], [MASK], [MASK], [MASK], [MASK], [MASK]],
[X, X, [MASK], A, [MASK], [MASK], [MASK], [MASK]],
[X, X, B, A, [MASK], [MASK], [MASK], [MASK]],
[X, X, B, A, [MASK], C, [MASK], [MASK] ]
]
送回模型本身,获取每个红色位置的 logits,如果红色位置的 logits 刚好能 decode 出来起草的 token,则接受草稿,否则拒绝草稿,并从获得的 logits 位置重新采样出一个 token 放上去,并拒绝这一次后续的草稿
比如接受了 A,拒绝了 B,且从拒绝 B 时的 logits 中可以采样出 D,则这次验证的输出为
X X D A [MASK] [MASK] [MASK] [MASK]
然后回到起草过程,继续生成新的 token
top-k 验证#
如果 draft 的 token 在验证阶段 top-k 的 token 之中则采用,其他路径一致
实验#
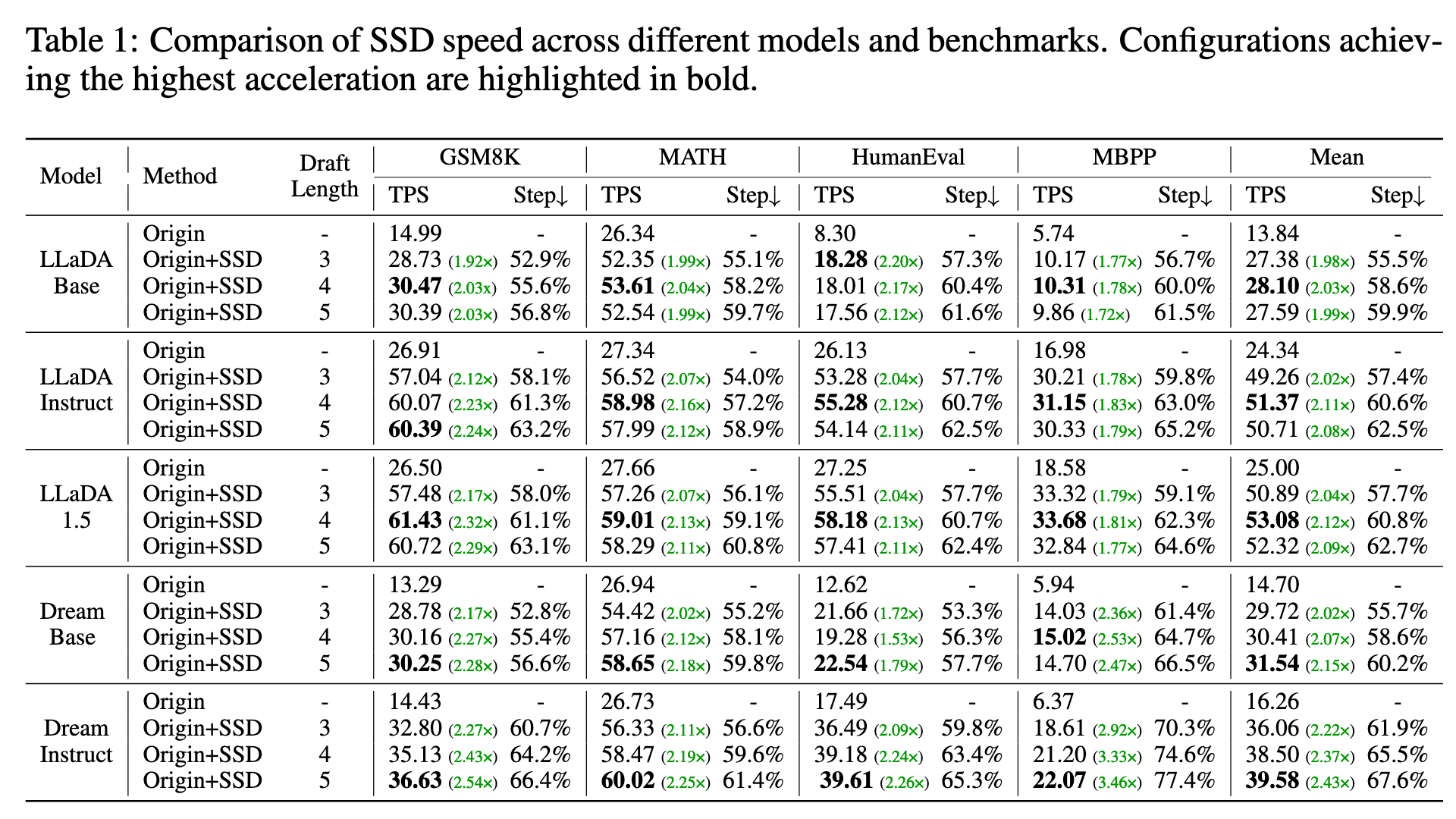
top-k 验证#

Upper bound 是所有 draft 都被 accpet 的理论极限 accepted_token / (draft_len) + 1