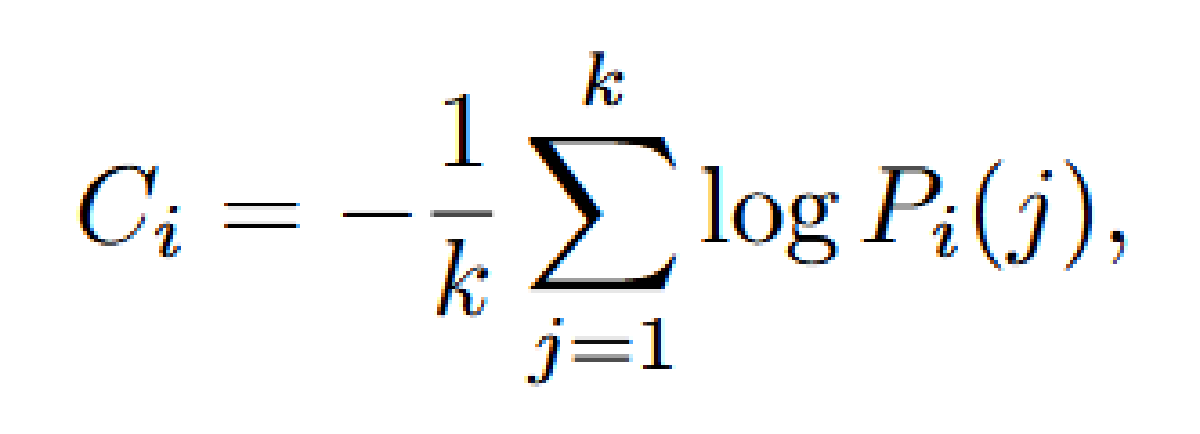
自信地深度思考#
DEEP THINK WITH CONFIDENCE
摘要#
大型语言模型(LLMs)通过测试时扩展方法(如基于多数投票的自洽性)在推理任务中展现了巨大的潜力。然而,这种方法通常会导致准确率提升逐渐减弱和计算开销过高。为了解决这些挑战,我们引入了“置信度深度思考”(DeepConf),这是一种简单而有效的方法,在测试时增强了推理效率和性能。DeepConf 利用模型内部的置信度信号,在生成过程中或生成后动态过滤掉低质量的推理路径。它不需要额外的模型训练或超参数调优,并可以无缝集成到现有的服务框架中。我们在多种推理任务和最新的开源模型(包括 Qwen 3 和 GPT-OSS 系列)上评估了 DeepConf。值得注意的是,在 AIME 2025 等具有挑战性的基准测试中,DeepConf@512 实现了高达 99.9% 的准确率,并相比完整的并行思考减少了最多 84.7% 的生成标记数。
动机#
- 先前的研究通过多个推理路径多数投票能提高 Acc,但是带来了大量的计算开销
- 多数投票平等对待每个推理路径,但是低质量的路径可能会导致次优的性能
- 也有方法在整条轨迹上计算全局置信度度量,以识别并过滤低质量轨迹,从而提高多数投票性能。但是全局置信度可能掩盖局部推理步骤中的置信度波动,而这些波动可以为估计追踪质量提供足够的信号。对整个追踪中的所有标记进行平均可能会掩盖在特定中间步骤中发生的关键推理故障。其次,全局置信度度量需要在计算之前生成完整的推理追踪,这会阻碍对低质量追踪的早期停止。
有研究表明,可以通过模型内部的 Token 分布得出的度量来有效评估推理轨迹的质量,于是定义 Token 置信度为位置 i 处前 k 个标记的负平均对数概率:
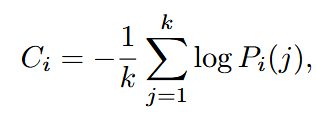
定义整个推理轨迹中的 Token 置信度的平均值为模型对于整个轨迹的置信度
作者认为平均轨迹置信度会掩盖中间推理的失败(少数高置信度 token 会掩盖低置信度片段。其次,这种方法需要完整的轨迹来进行质量评估,这阻止了低质量生成的早期终止,导致计算效率低下。)
方法#
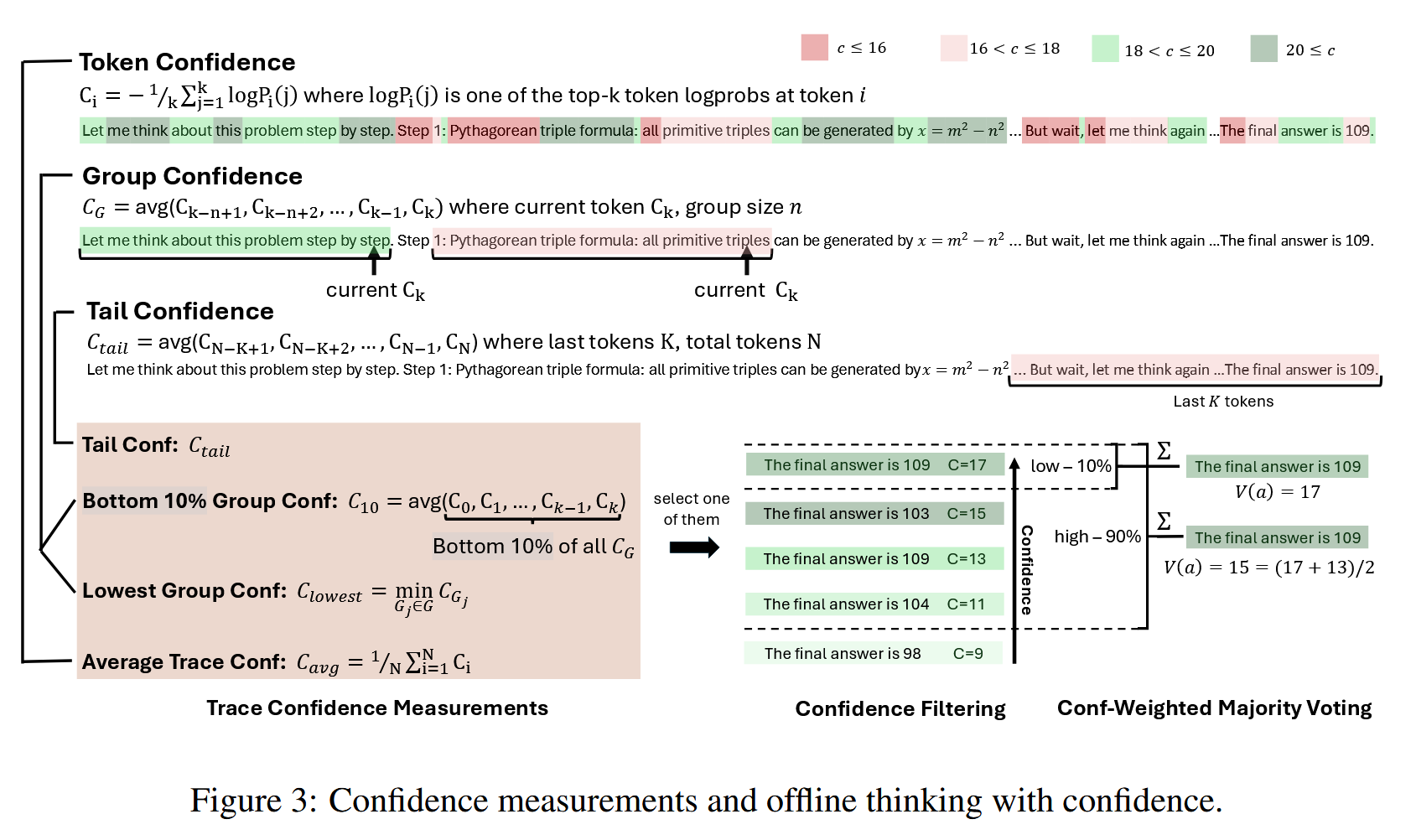
新的置信度测量方式#
组置信度#
每个标记都与一个滑动窗口组 Gi 相关联,该组由 n 个先前的标记(例如,n = 1024 或 2048)组成,相邻窗口之间存在重叠。对于每个组 Gi,组置信度该组所有 token 置信度的平均值。
我们观察到,轨迹中置信度极低的中间步骤会显著影响最终解决方案的正确性。例如,当在使用“wait”、“however”和“think again”等重复低置信度标记进行推理时,置信度急剧下降会破坏推理流程,并导致后续错误。
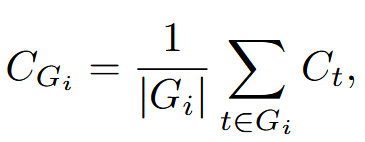
底部 10% 组置信度#
为了捕捉极低置信度组的影响,作者提出了底部 10% 组置信度,其中轨迹置信度由轨迹内组置信度底部 10% 组置信度的均值确定。
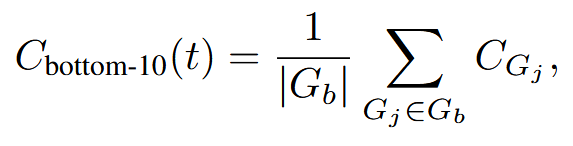
其中 Gb 是置信度得分最低的 10% 的组的集合。实证研究表明,10% 能够有效捕捉不同模型和数据集中最有问题的推理片段。
最低组置信度#
作者还考虑最低组置信度,这表示在推理轨迹中置信度最低的组的置信度——即前 10% 最低置信度组的一个特例。该指标仅基于最低置信度组来估计轨迹质量:
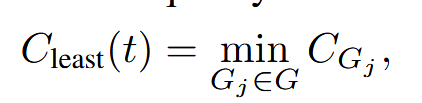
尾部置信度#
通过关注推理轨迹的最后部分来评估推理轨迹的可靠性。该指标的提出是基于观察到推理质量通常会在长链思维的末尾下降,而最后步骤对于得出正确结论至关重要。在数学推理中,最终答案和结论步骤尤为重要:那些开始表现良好但结尾较弱的轨迹可能会产生错误的结果,尽管中间推理看起来很有希望。
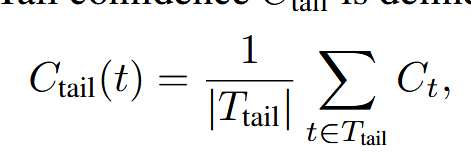
其中 T_tail 代表一组固定数量的 token,如 2048
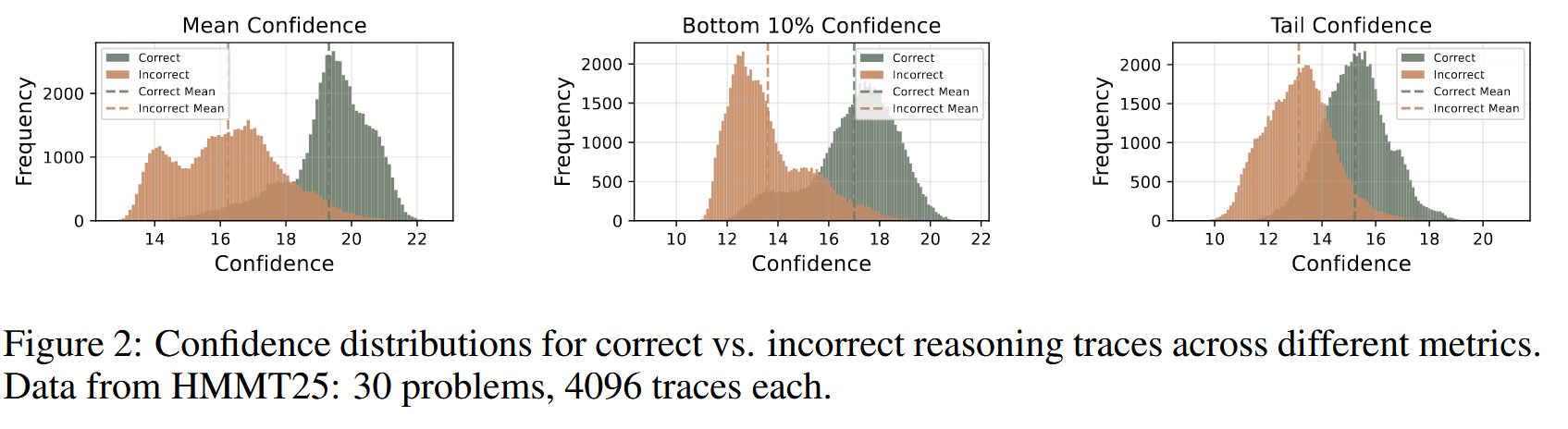
作者统计了在 HMMT25 的 30 个问题上,30*4096 个轨迹的推理结果
离线带置信度的思考#
采用多数投票的方法,但是使用置信度加权
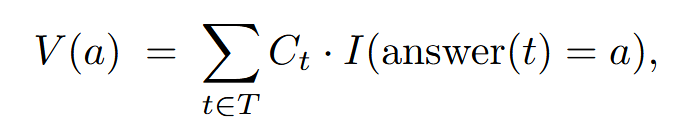
并应用置信度过滤器(只使用前 η% 的推理轨迹)
在线带置信度思考#
在在线思考过程中评估置信度,能够在生成过程中实时估计轨迹质量,并允许动态终止没有前景的轨迹。这种方法在资源受限的环境或需要快速响应的情况下尤其有价值。最低组置信度指标在此在线设置中可以有效应用。当标记组置信度低于临界阈值时,我们可以停止轨迹生成,确保这些轨迹在置信度过滤过程中很可能会被排除。
作者提出一种办法(基于最低组置信度),可以在推理时提前停止希望不大的路径,具体包含两个部分:离线预热和自适应采样
离线预热#
离线预热是为了找到一个判断可以提前终止的阈值 s。对于每个新的 Prompt,生成 N 个推理轨迹,于是停止阈值定义为
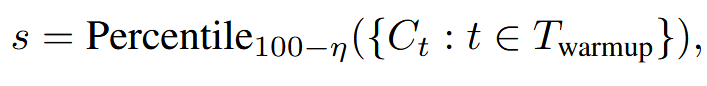
其中 T_{warmup}表示所有的预热轨迹,Ct 是轨迹 t 的置信度,η 是期望保留比例
具体来说就是找了个分位点 s
自适应采样#
根据问题难度动态决定 N 为多少。难度通过生成轨迹之间的共识进行评估,其量化方式为多数投票权重与总投票权重的比值
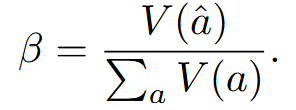
设置一个超参数 τ,如果 β<τ,则认为当前模型未达成共识,就继续推理,直到达到固定的推理预算 B。否则,追踪生成停止,使用现有的追踪确定最终答案。
实验#
模型:DeepSeek-r1-distill-qwen3-8b、Qwen3-8B、Qwen3-32B、GPT-OSS-20B、GPT-OSS-120B
数据集:AIME24、AIME25、BRUMO25、HMMT25、GPQA
Baseline:多数投票(每个大语言模型采样 T 个独立的推理路径,并通过无权重多数投票选择最终答案)
实验设置:每个 Prompt 提前生成 4096 个完整推理轨迹来建立一个共同的采样框架,离线实验在每次运行时从该池中重新采样大小为 K(例如,K=512)的工作集,并应用指定的投票方法。在线实验同样重新采样一个工作集,以驱动即时生成并提前停止;该池确保了不同方法之间的采样一致性。对于滑动窗口计算置信度的的 window size 是 2048 个 token,N=16,τ=0.95
Pass@1 是一次推理,Cons@K 是无权重 K 次投票,Measure@K 是置信度权重的多数投票
下图是 offline
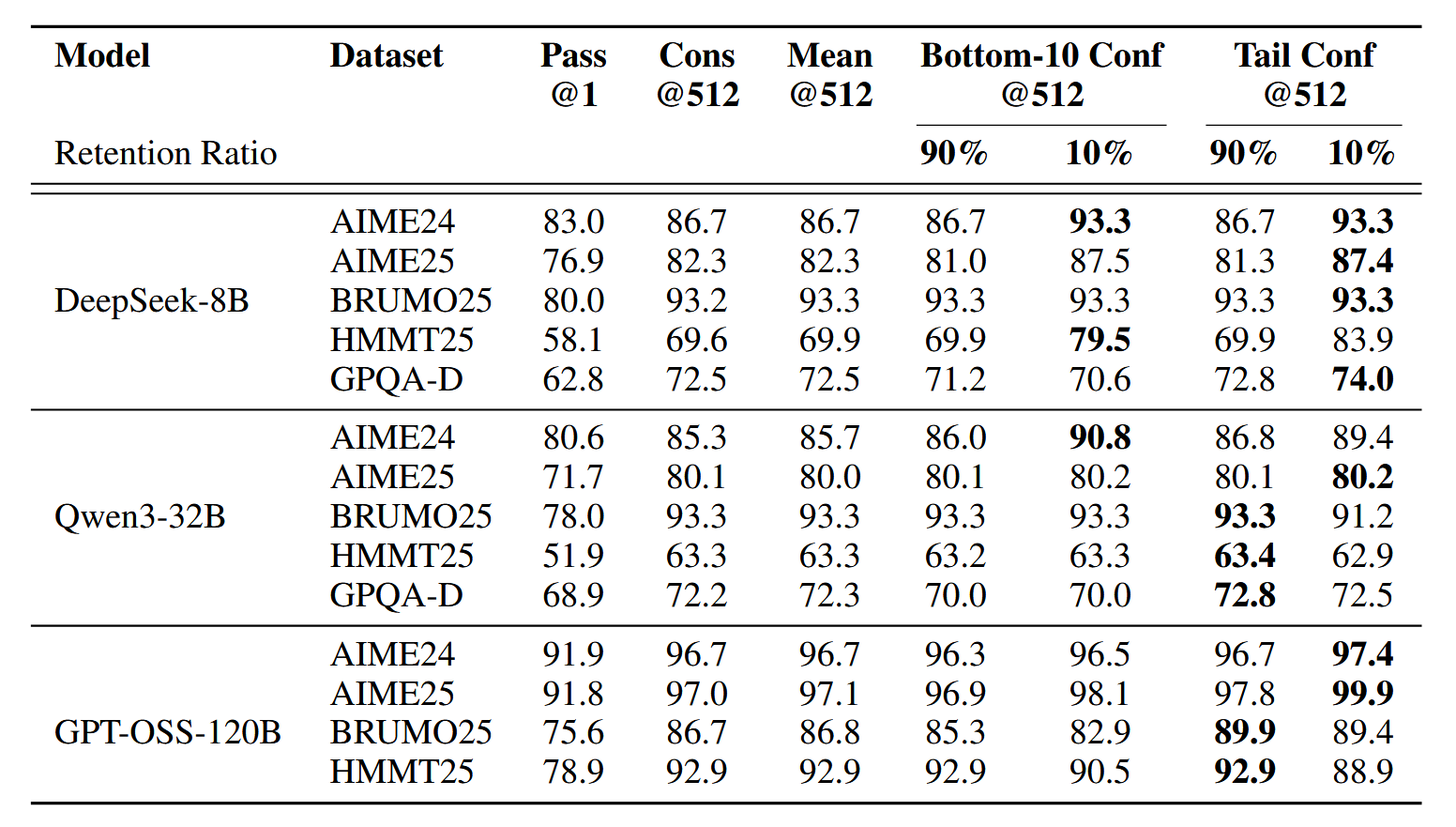
下图是 online