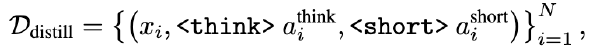
AdaCoT:通过强化学习实现的帕累托最优自适应链式思维触发器#
AdaCoT: Pareto-Optimal Adaptive Chain-of-Thought Triggering via Reinforcement Learning
摘要#
LRM 在需要复杂推理的任务上常常面临挑战。尽管 CoT 显著提升了推理能力,但它会不分情况地为所有查询生成冗长的推理步骤,这导致了巨大的计算成本和低效,尤其是对于简单输入时更是如此。为了解决这一关键问题,我们提出了 AdaCoT,使 LLMs 能够自适应地决定何时调用 CoT。AdaCoT 将自适应推理建模为一个 Pareto Improvement 问题,旨在平衡模型性能与 CoT 调用相关的成本(包括频率和计算开销)。我们提出了一种基于强化学习(RL)的方法,具体使用近端策略优化(PPO),通过调整惩罚系数动态控制 CoT 触发决策边界,从而使模型能够根据隐式的查询复杂性判断是否需要 CoT。一项重要的技术贡献是选择性损失掩码(Selective Loss Masking, SLM),其设计目的是在多阶段 RL 训练过程中防止决策边界崩溃,确保稳健且稳定的自适应触发。实验结果表明,AdaCoT 成功地在帕累托前沿上导航,大幅减少了不需要复杂推理的查询中的 CoT 使用。例如,在我们的生产流量测试集上,AdaCoT 将 CoT 触发率降低至 3.18%,并减少了 69.06% 的平均响应 token 数量,同时在复杂任务上仍保持高性能。这种显著的 token 减少直接转化为推理计算负载的大幅降低。AdaCoT 开创了自适应 CoT 触发的先河,为开发更高效、更响应迅速且更具成本效益的 LLMs 提供了一个实用且原则性的解决方案,这对于交互式和资源敏感型应用尤为重要。
Motivation#
- 即便是简单回答,CoT 也会大大消耗 Token 数量
- 现有的研究无法依据题目难度(查询复杂度)自适应 CoT
方法#
目标描述#
主要两个目标:最大化 acc + 最小化部署成本
几个指标:
\(T(\theta)=CoT 触发率 =
\frac{使用 CoT 回复数}{回复总数}\),如果有
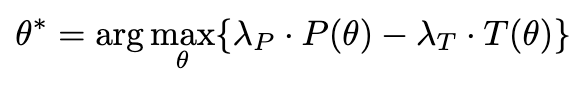
其中两个 lambda 是两个超参数
数据生成和 SFT#
使用一个辅助模型(实验中使用 15B 模型)对于一个用户和 AI 的对话打标签,标签共两种:是/否需要深度思考

基于辅助模型标注结果,对于数据进行处理。如果辅助模型任务需要深度思考,则不做处理,否则就将推理部分替换为空(
强化学习#
奖励函数如下:
$$ R(x, r)=R_{base}(x, r) - \alpha_1P_{miss}(x,r) - \alpha_2P_{over}(x,r)-\gamma P_{fmt}(r) $$其中 Rbase 为衡量响应质量的基础奖励,Pmiss 是对于推理省略的二元惩罚,Pover 是对于过度推理的二元惩罚,Pfmt 是对于格式化错误的二元惩罚,其他是非负超参数
为了防止在强化学习过程中,模型落入其中一种 CoT 模式(要么只 CoT、要么全跳过),AdaCoT 引入了选择性损失掩码(Selective
Loss
Masking, SLM),具体实现为掩盖
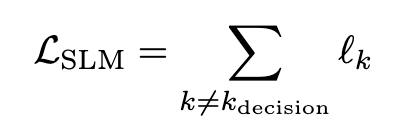
实验#
模型:豆包 15B 和 150B 模型
训练过程:SFT+ 数学 RL+ 通用 RL
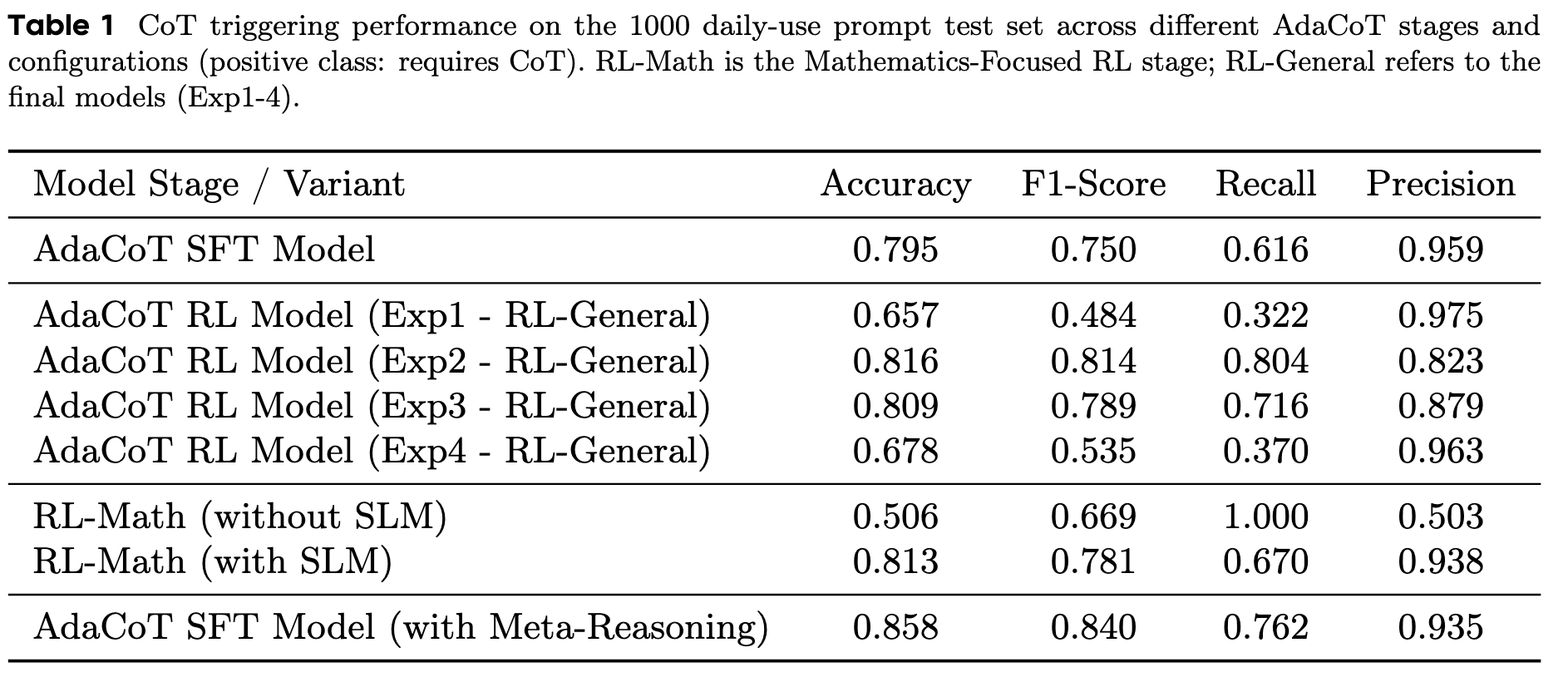
Baseline: Full CoT SFT、Full CoT RL、No CoT SFT、No CoT RL、仅经过了 SFT 未 RL 的 AdaCoT
数据集:LiveBench [45]、MMLU Pro [42]、SuperGPQA [7]、GPQA [32]、Chinese SimpleQA [12]、SimpleQA [44]、AIME24 & AIME25、MATH [13]、OlympiadBench [11]、SweBench Agentless [18]、LiveCodeBench [17]、KOR-Bench [25]、ProcBench [8] 和 SysBench [31]
超参:强化学习共 4 个阶段,Exp1 (α1 = 0.1, α2 = 0.3), Exp2 (α1 = 0.2, α2 = 0.3), Exp3 (α1 = 0.3, α2 = 0.3), and Exp4 (α1 = 0.3, α2 = 0.1),gamma 设置为 1.0
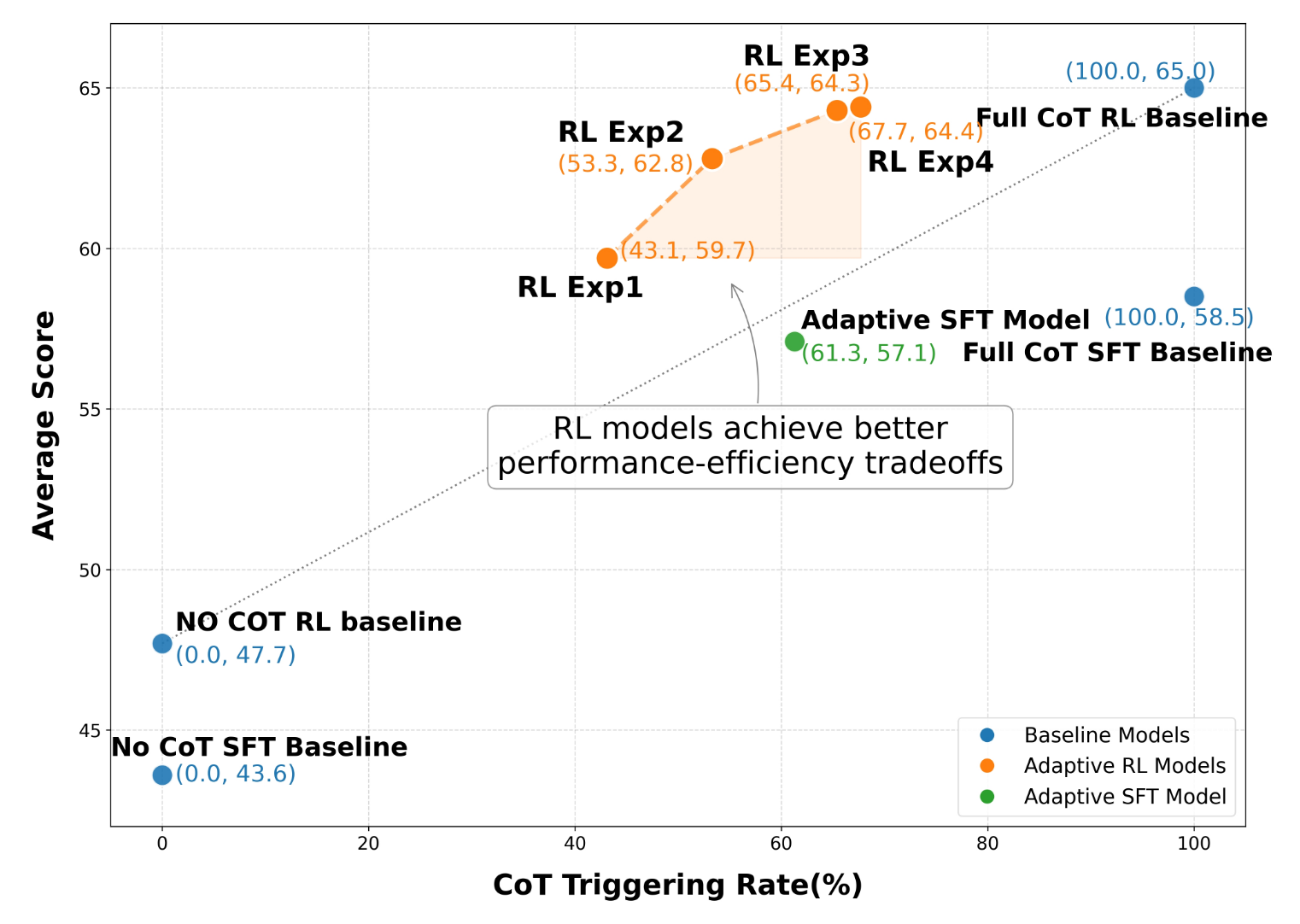
此外,团队还实验了 SFT 的 Meta-Reasoning,具体来说就是

在