AdaptThink: 让模型决定是否思考#
AdaptThink: Reasoning Models Can Learn When to Think
摘要#
最近,大型推理模型通过采用类似人类的深度思考,在各种任务上取得了令人印象深刻的表现。然而,冗长的思考过程显著增加了推理开销,使得效率成为关键瓶颈。在这项工作中,我们首先证明了对于相对简单的任务,NoThinking(即提示推理模型跳过思考并直接生成最终解决方案)在性能和效率方面都是更好的选择。受此启发,我们提出了 AdaptThink,一种新颖的强化学习算法,用于教导推理模型根据问题难度自适应地选择最优思考模式。具体而言,AdaptThink 包含两个核心组件:(1)** 一个约束优化目标,鼓励模型选择 NoThinking 同时保持整体性能**;(2) 一种重要性采样策略,在基于策略的训练过程中平衡 Thinking 和 NoThinking 样本,从而实现冷启动,并使模型在整个训练过程中探索和利用两种思考模式。我们的实验表明,AdaptThink 显著降低了推理成本,同时进一步提升了性能。特别地,在三个数学数据集上,AdaptThink 将 DeepSeek-R1-DistillQwen-1.5B 的平均响应长度减少了 53%,并将其准确性提高了 2.4%,这凸显了自适应思考模式选择在优化推理质量和效率平衡方面的潜力。我们的代码和模型可在 https://github.com/THU-KEG/AdaptThink 获取。
Motivation#
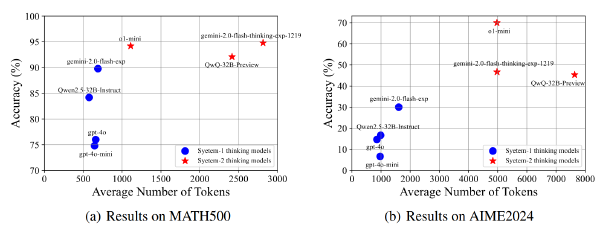
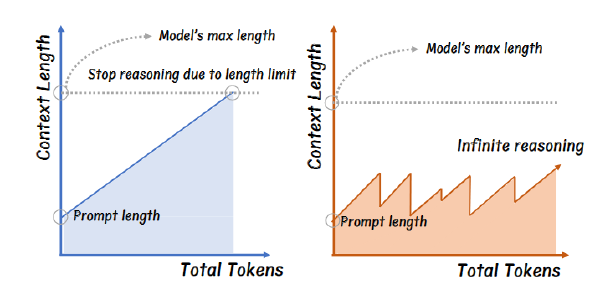
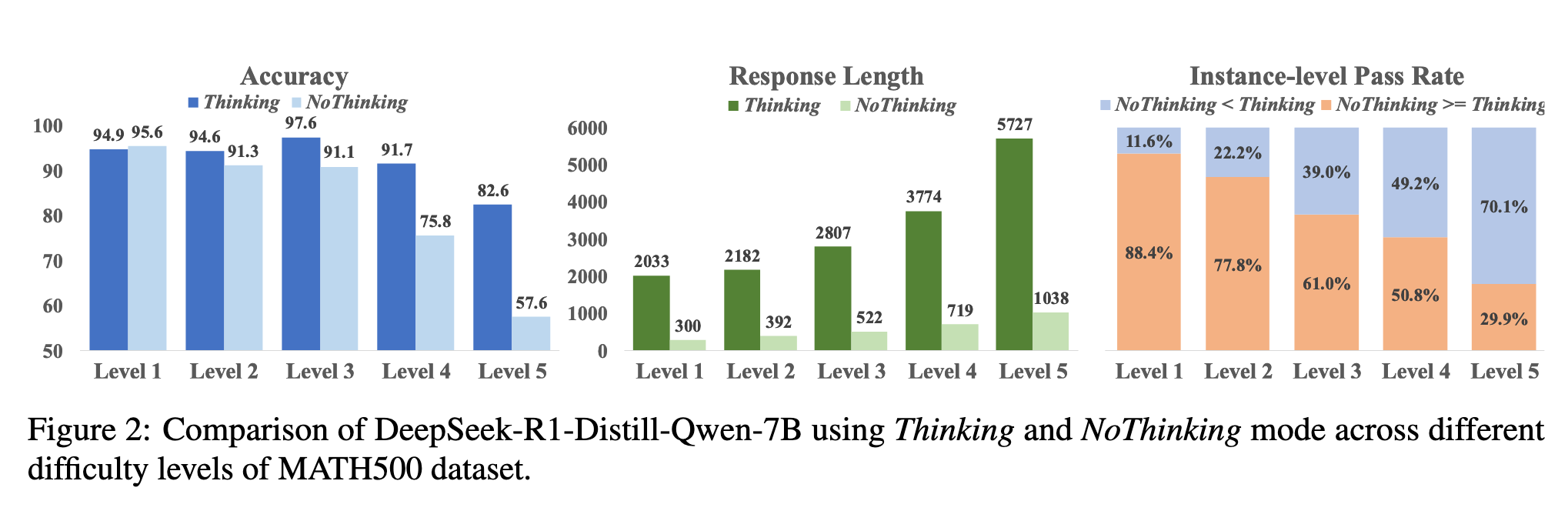
- 在简单问题(最高高中竞赛水平)上不思考(填充
来跳过思考过程)和思考相当甚至更好
方法#
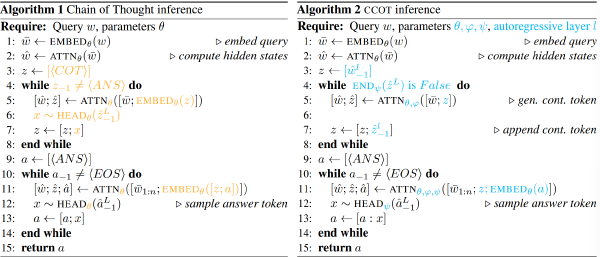
两种推理模式,think 和 nothink,think 即为正常推理,no-think 是使用空 think 段填充来跳过思考过程
约束优化目标#
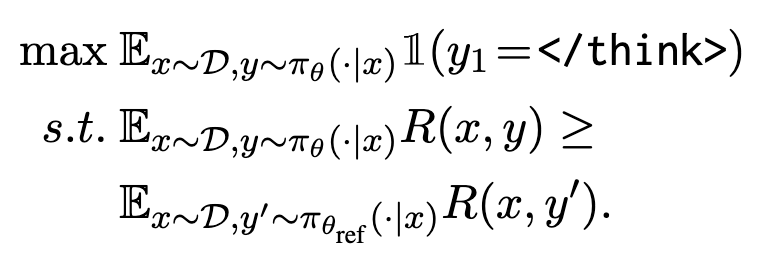
\(\pi_{\theta_{ref}}\)是一个 Reasoning 模型,保持不变; \(\pi_\theta\)是当前在训练的模型,在训练之前,两个模型是同一个
R(x,y)是如果做对就返回 1,否则为 0
在保证回复的 Acc 的基础上有限选择 nothink(y 的第一个 token 是的)
为了实现上述有约束的优化目标,将约束作为惩罚项,乘以系数 \(\lambda\) 融合进目标函数:
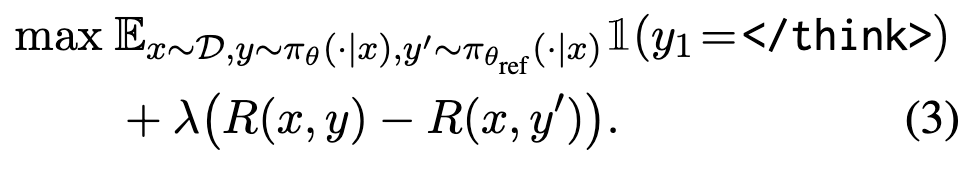
两项同时除以 \(\lambda\),让 \(\delta = \frac{1}{\lambda}\)
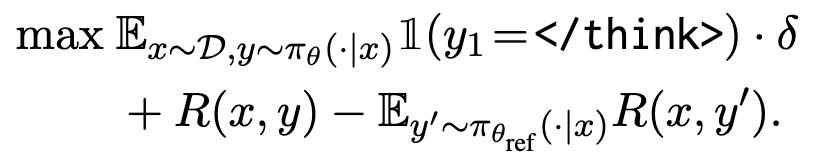
但是由于\(\pi_{\theta_{ref}}\)保持不变,所以可以提前在数据集上跑一波来近似 \(R(x,y')\),于是作者从数据集中随机抽取 K 个样本,并估算\(R(x,y')\)
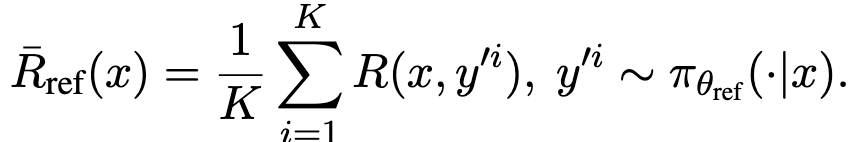
将上式带入优化目标得
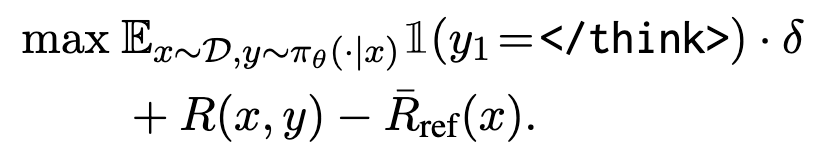
下式中, \(A(x, y) = 1(y_1=\text{}) · \delta + R(x, y) - R_{ref}(x)\)
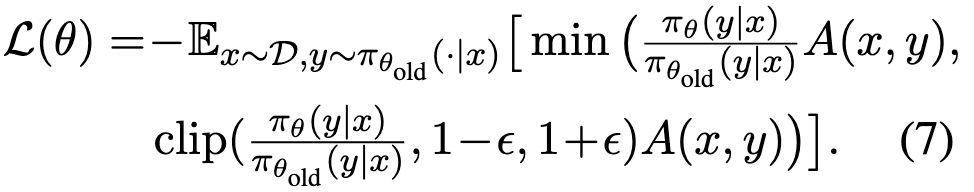
重要性采样策略#
上面提到,从数据集中采样 K 个来近似\(R(x,y')\),但是在训练之前模型只能天然生成 think 的回复而不会 Nothink,为了解决这个问题,作者修改了模型的推理过程。让第一个词为的概率为 0.5,为 wstart(如“嗯,”、“Alright”等发语词,实验中使用的是 Alright)
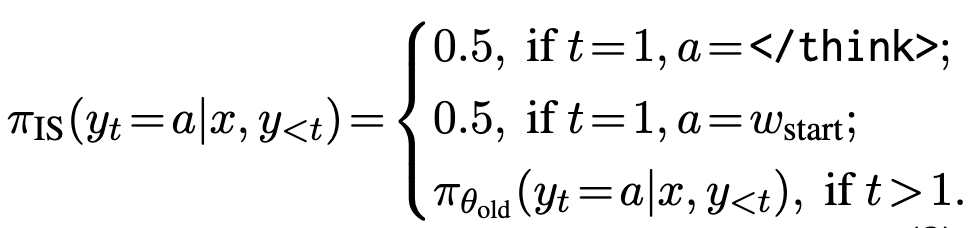
然后用这个新的分布来近似\(R(x,y')\)
实验#
模型:#
DeepSeek-R1-Distill-Qwen1.5B、DeepSeek-R1-Distill-Qwen-7B
数据集:#
训练集:#
DeepScaleR(AIME 1983-2023, AMC, Omni-Math and STILL 派生出来的包含 40k 问题的数据集)
测试集:#
GSM8K、MATH500、AIME2024(AIME 每个问题采样 16 次,取 16 次平均值)
实现细节:#
使用 VeRL 作为训练框架,上下文 16K,batchsize 128,learning rate 2e-6
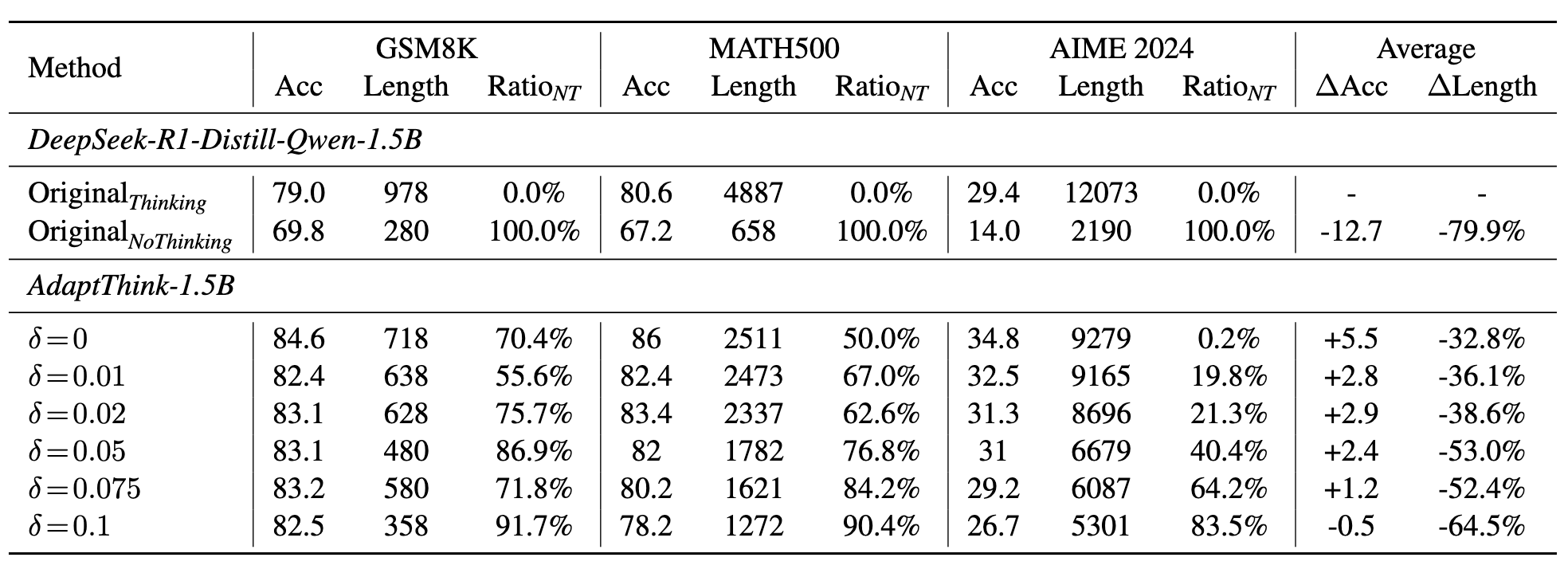
K(上面从训练集中抽样来进行估计的超参数)=16,δ(惩罚系数的倒数)=0.05,ε(clip 中的超参)=0.2
训练 1 个 epoch,314 个 step
1.5B 模型 8H800,32 个小时,7B 8H800 28 个小时
分别为 1.5B 和 7B 模型选择了 300 步和 150 步的 checkpoint
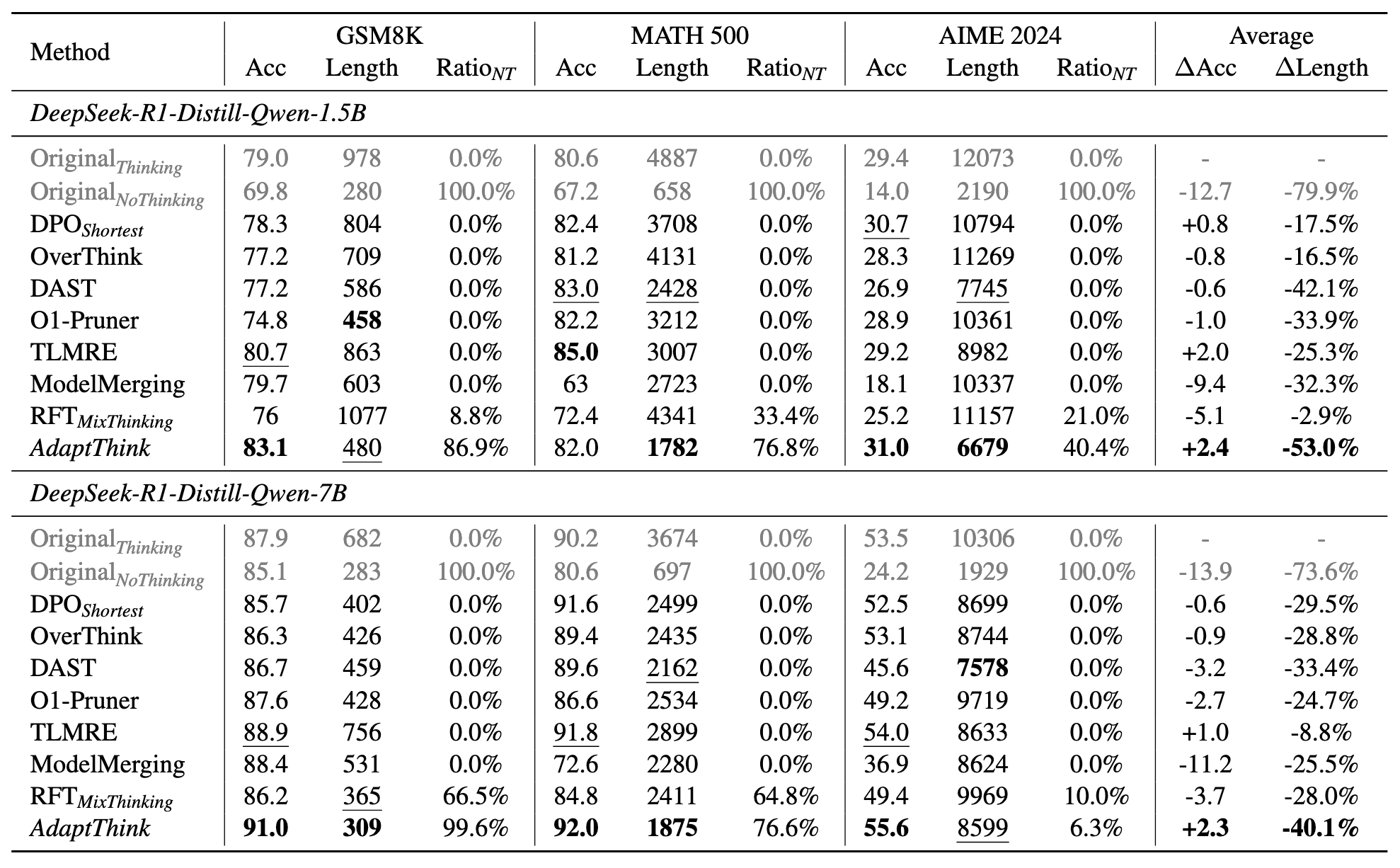
DPO shortest 是在数据集中采样多个响应,并取出最短的那个来 DPO 训练
OverThink 将每个训练问题的原始长思考响应作为负例,同时将思维过程中前两次得到正确答案的尝试作为正例来构建偏好数据,然后使用 SimPO 来缓解模型的过度思考行为。
DAST 使用基于长度的奖励函数对预先采样的响应进行排名来构建偏好数据
O1-Pruner 预采样估计参考模型的性能,然后使用离线策略 RL 风格的微调,在准确性约束下鼓励模型生成更短的推理过程
TLMRE 引入了一个基于长度的惩罚项到策略型强化学习中,以激励模型生成更短的响应。
ModelMerging 通过将非推理模型(即,Qwen-2.5-Math-1.5B/7B)的权重与其进行加权平均,从而缩短推理模型的响应长度。
RFTMixThinking 首先对每个训练问题 x 使用 Thinking 和 NoThinking 采样多个响应,然后选择 (1) 如果实例级通过率 R ̄nothink(x) ≥ R ̄think(x),则选择正确的 NoThinking 响应,以及 (2) 如果 R ̄nothink(x) < R ̄think(x),则选择正确的 Thinking 响应,并使用这些选定的响应来微调模型。
不同惩罚系数的选择
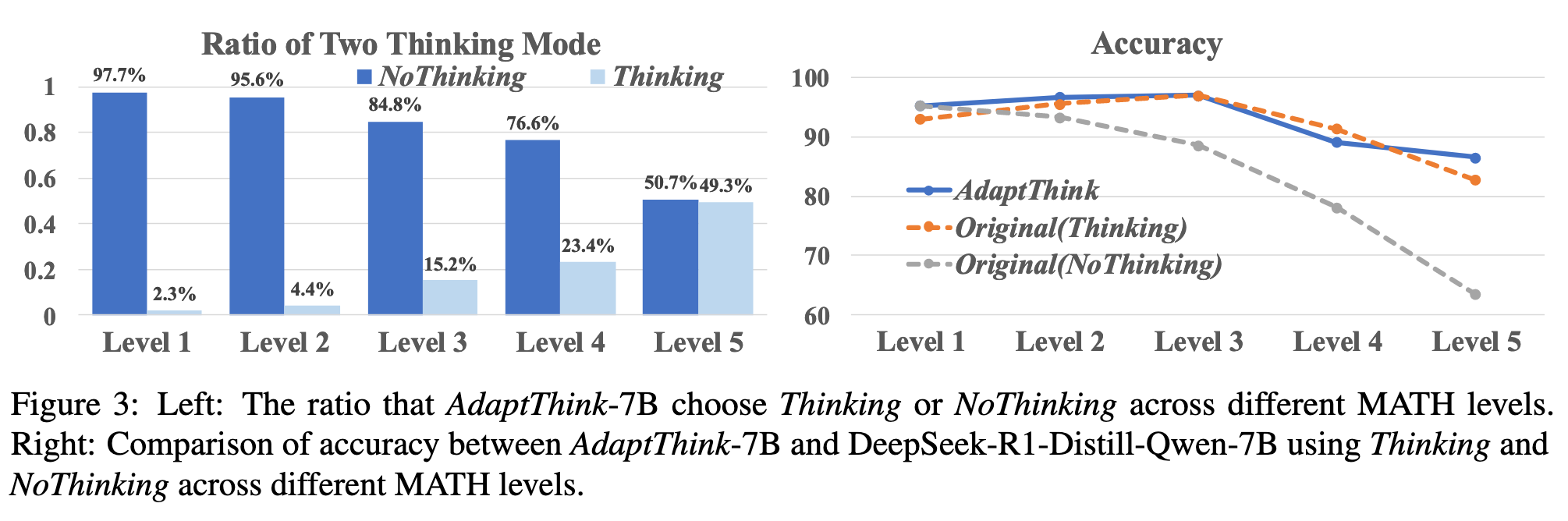
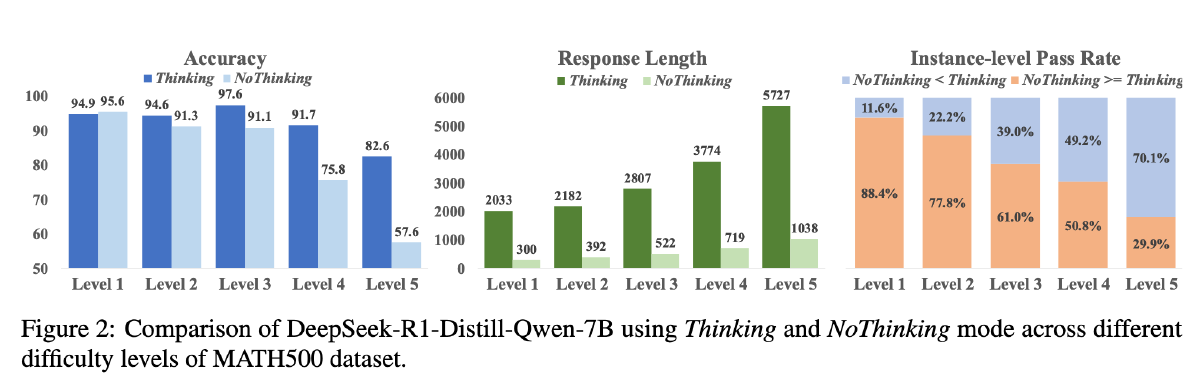
观察到 AdaptThink 的现象,题目越难越容易 Think: