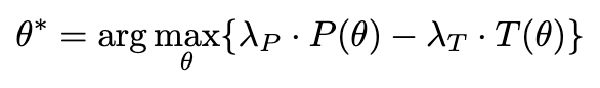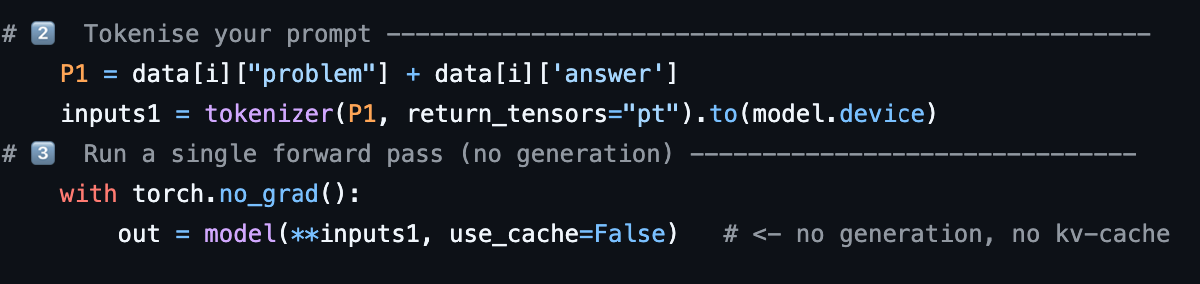
ASC:CoT 压缩的激活引导 Training free#
Activation Steering for Chain-of-Thought Compression
摘要#
大语言模型(Large language models,LLMs)在包含中间推理步骤(称为思维链(chains of thought,CoTs))时擅长复杂推理。然而,这些推理过程对于简单问题也往往过于冗长,导致上下文浪费、延迟增加和能耗上升。我们观察到,在模型残差流(residual-stream)激活空间中,以英文为主的冗长 CoTs 与以数学为中心的简洁 CoTs 占据着不同的区域。通过提取并注入一个转向向量(steering vector)在这两种模式之间转换,我们可以可靠地促使生成更加简洁的推理内容,从而在不重新训练模型的前提下有效压缩 CoTs。我们将该方法形式化为激活引导压缩(Activation-Steered Compression,ASC),这是一种在推理阶段通过直接修改隐藏表示来缩短推理路径的技术。此外,我们还从理论上分析了 ASC 对输出分布的影响,并基于闭式 KL 散度约束(closed-form KL-divergence-bounded constraint)推导出用于调节转向强度的理论依据。仅使用 50 组成对的冗长与简洁示例,ASC 在 MATH500 和 GSM8K 数据集上实现了高达 67.43% 的 CoT 长度缩减,同时在 7B、8B 和 32B 参数规模的模型上保持了准确率。作为一种无需训练的方法,ASC 引入的运行时开销可以忽略不计,并且在 MATH500 上,8B 模型的端到端推理实际运行时间平均提升了 2.73 倍。这使得 ASC 成为在对延迟或成本敏感的应用场景中简化具备推理能力的 LLMs 部署的一种实用且高效的工具。
https://github.com/ArminAzizi98/ASC
Motivation#
- Overthinking 消耗资源
- Overthinking 影响性能
- 使用激活引导具有可解释性
- 和现有方法(retrain、prompt-engineer、早停法)兼容
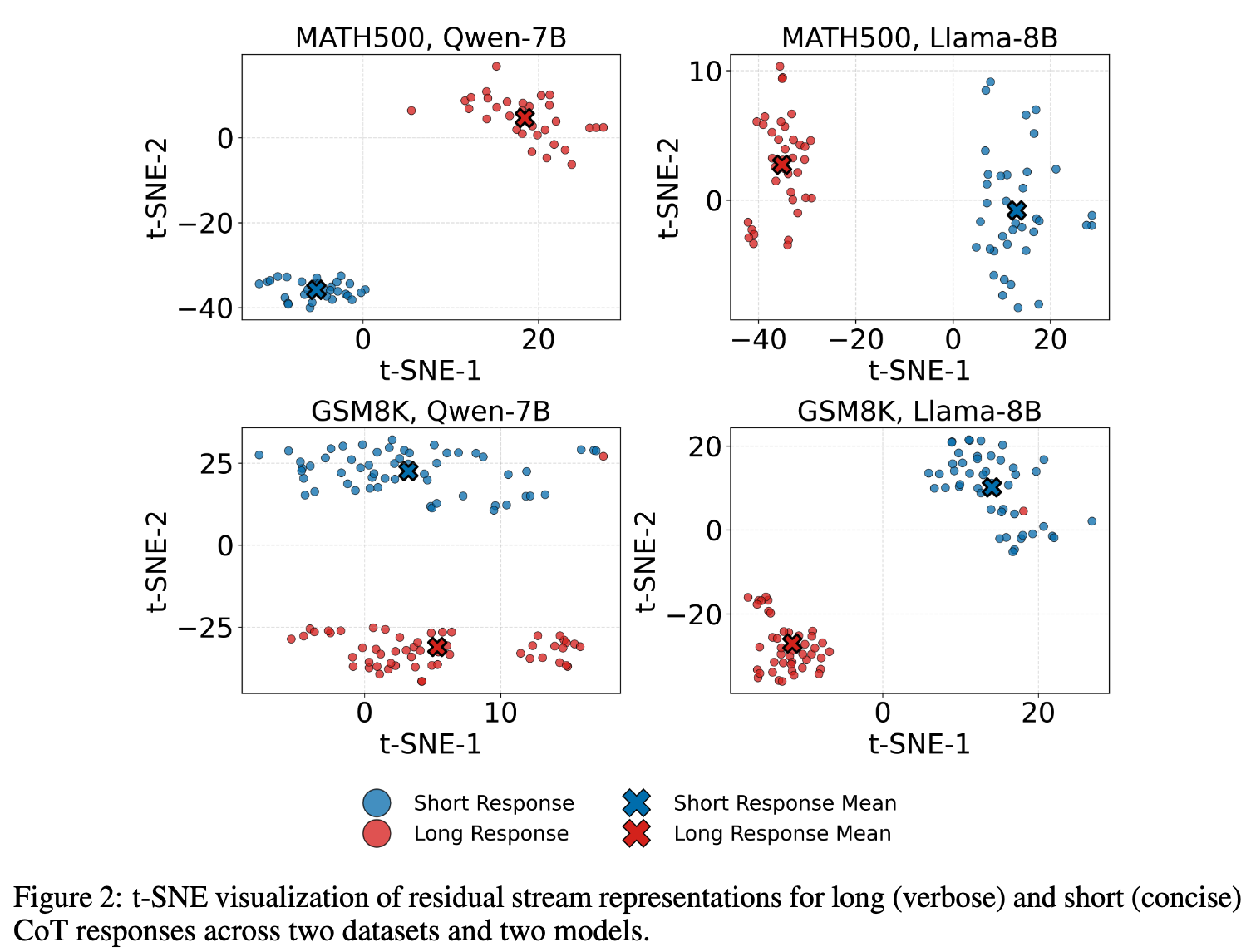
Long Response 和 Short Response 的 t-SNE#
从 MATH500 和 GSM8K 中采样问题,并使用 ds-distill-qwen7b 和 ds-distill-llama-8b 生成推理 CoT,并使用 gpt-4o 生成 short cot。
We feed each input independently into the model,并提取出第 21 层的 output
问题和长短 CoT 示例如下:

t-SNE 降维如下,特征明显
方法#
激活向量#
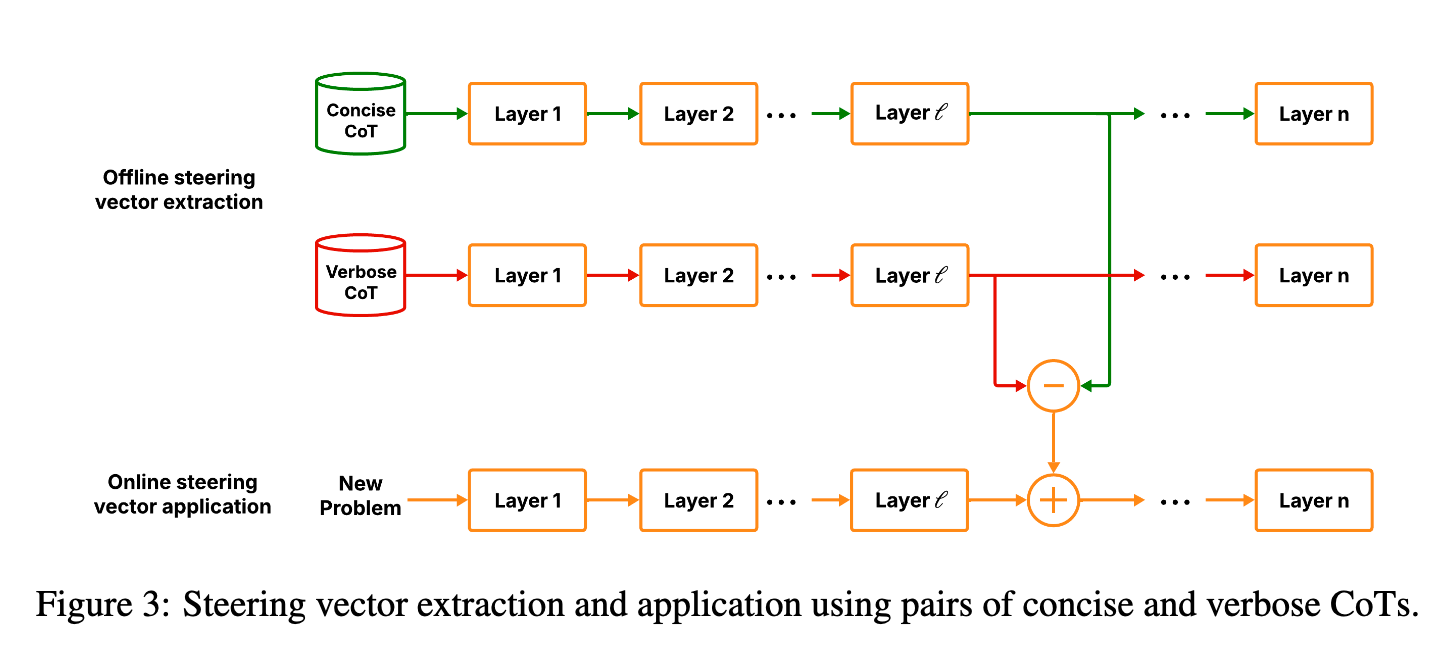
记冗长 CoT 为 l_i,简短 CoT 为 s_i,定义 h^l 为第 l 层的输出,h^l(s)为将字符串 s 输入模型时第 l 层输出的隐藏状态
引导向量计算如下:
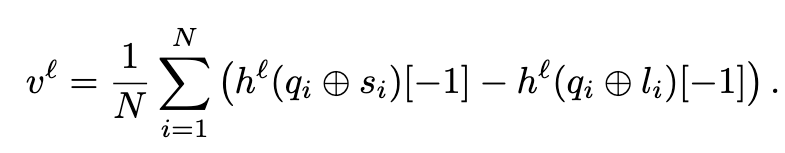
用自然语言表达就是,将问题和回复拼接成字符串,获取最后的隐藏状态,对于每个问题用短回复 ➖ 长回复,并最终求出平均值,获得一个向量
在 decode 阶段应用这个向量,其中 gamma 为超参数:
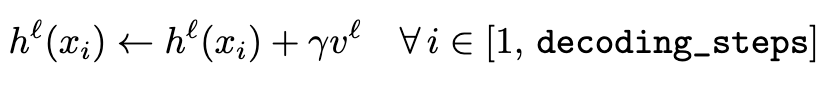
自适应 Gamma#
确保应用激活向量前后 KL 散度变化有限:
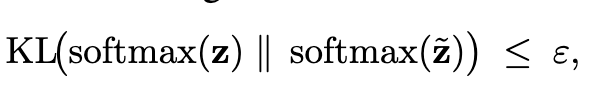
其中 \(\varepsilon\)是一个超参数
数学推导(我得再啃啃)#
推导结论#
如果定义:
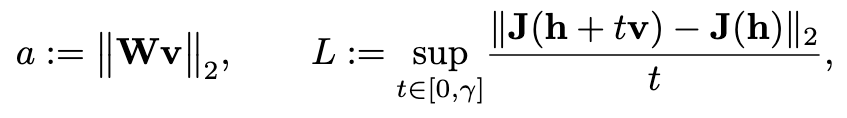
则有:
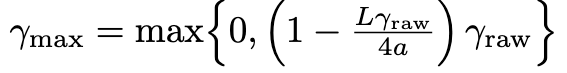
其中 \(\gamma_{raw}=\frac{ax}{L}\),并且 x 是 \(x^3+x^2-\frac{4\varepsilon{L}^2}{a^4}=0\)的解
我们在小型校准集(50 个隐藏状态)上估计两个尺度参数 α 和 L。对于每个隐藏状态,我们使用选定的引导方向计算一个雅可比矩阵-向量积(Jacobian–vector product),并记录其欧几里得范数;这些范数的中位数即作为我们对 α 的估计值。为了获得 L,我们在每个校准点上沿相同方向计算一个海森矩阵-向量积(Hessian–vector product),收集得到的范数,并取其第 95 百分位数。
如何应用方法#
从数据集中 sample 50 个样本,分别用推理模型和非推理模型生成冗长 CoT 和简短 CoT,并提取出对于的隐藏状态,用隐藏状态获取向量并估算 gamma
实验#
数据集:MATH500、GSM8K
模型:deepseek-r1-distill-llama-8b、deepseek-r1-distill-qwen-7b、qwq-32b
超参数: \(\varepsilon = 10^{-3}\),在每个数据集中提取出 50 条数据用于预估 a 和 L 从而预估 \(\gamma\) ,temperature=0.7,top_p=0.9, repetition_penalty=1.1
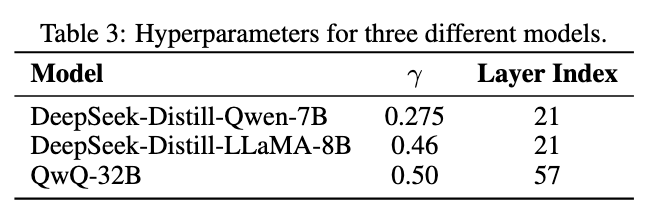
硬件:A6000,torch2.5.1+cu124,transformers4.50.1
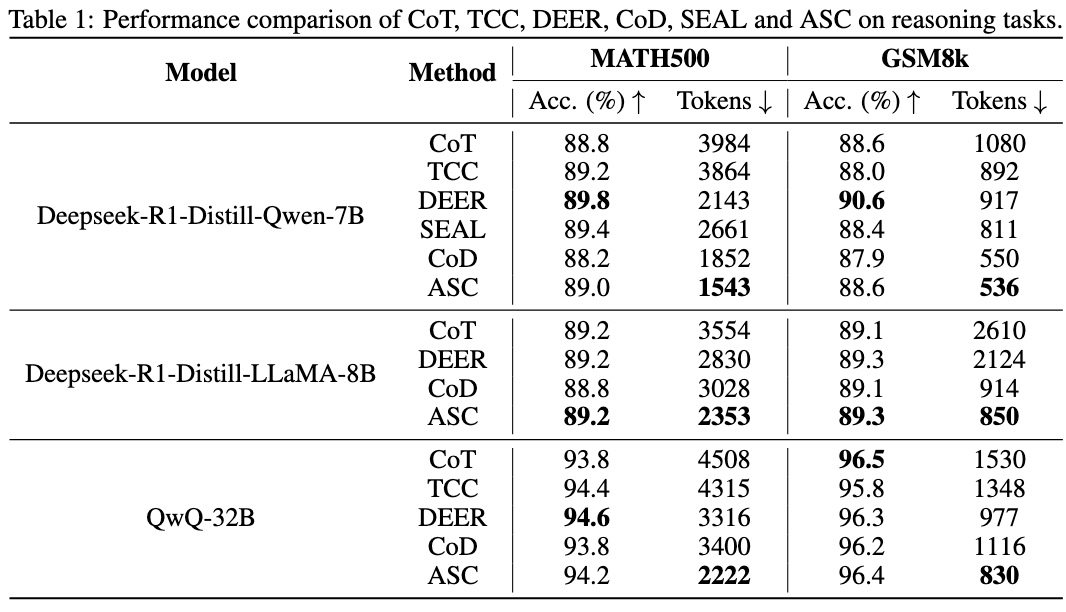
Baseline:
- CoT
- CoD(Chain-of-Draft,大概方法还是类似 CoT,但是让模型先生成核心步骤,每个步骤不超过 5 个 token,纯 prompt 的内容)
- DEER(DEER:基于 Trial 置信度的推理早停,出现 Wait 时计算一下置信度,如果置信度够高了就 Early exit)
- TCC(http://arxiv.org/abs/2501.19393 大致方法是将 eos 替换成 Wait,直到达到 budget)
- SEAL(SEAL:大语言模型的可操控推理 Traning Free, 跟这篇 Paper 有点像,SEAL 的方法是使用引导向量引导 response 多多生成执行 Thought 而少生成反思和过渡 Thought,引入了新的超参数)
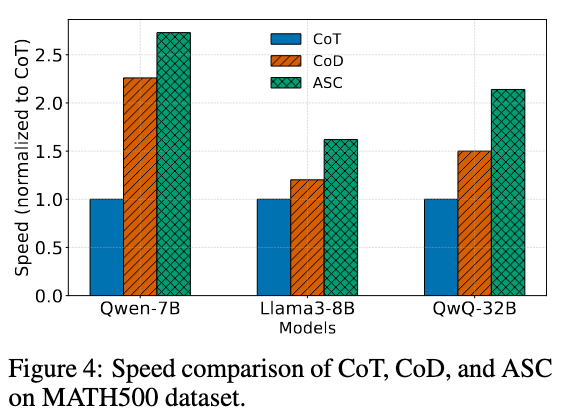
此外,作者还测试了跨数据集提取向量的压缩作用:
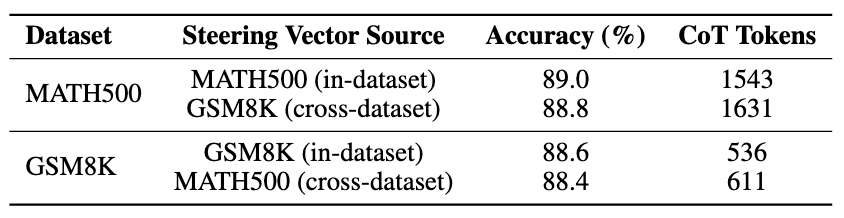
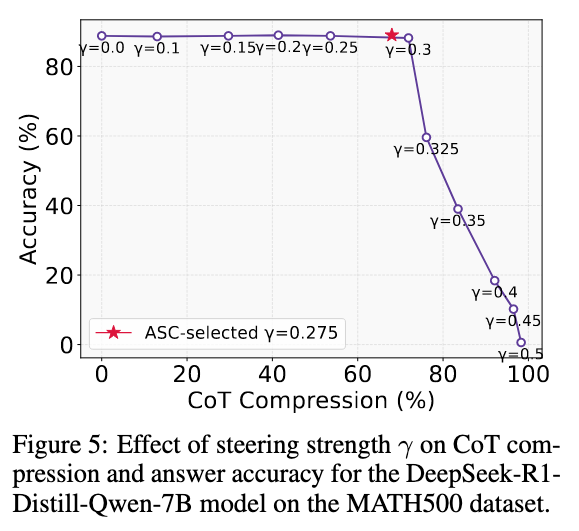
以及如果不使用预估的 gamma 而是直接指定的话: