CCoT:通过密集表示实现高效推理#
Compressed Chain of Thought: Efficient Reasoning Through Dense Representations
摘要#
提出了一种新的推理框架“Compressed Chain-of-Thought(CCOT)”,旨在在不显著增加解码时间的前提下提升大语言模型的推理能力。该方法通过生成**“沉思(contemplation)token”**——压缩版的推理链条表示,替代传统显式语言推理路径,实现在连续空间中高效推理。CCOT 可灵活地调节推理质量与计算效率的平衡,并可适用于现有的解码器型语言模型。实验显示,CCOT 在保持较低延迟的同时显著提升了准确率。
Motivation#
链式思维(CoT)技术通过让模型“逐步思考”以提高其复杂推理能力,但代价是极高的生成延迟。例如,使用 CoT 提示时 GPT-4o 的响应时间是普通方式的约 7 倍。其他工作尝试通过类似“沉思 token”来缩短显式推理路径,例如 pause token、filler token 等,这些 token 大多数是非语义性的,提供额外计算但缺乏语义表示。
本工作指出,使用语义有内容的沉思 token(compressed reasoning chain 的表示)可以在更短时间内保留推理能力,并能被模型用于后续解码或可解释分析。通过对 CoT 链条进行连续空间的压缩表达,可获得一种新的高效推理机制,同时减少计算成本和生成长度。
方法#
训练阶段
这种架构包含两个模块:CCOT φ(生成沉思 token)和 DECODE ψ(基于 query 和沉思 token 生成最终答案)。
打分器#
其中打分器的核心是一个 linear,来自另一篇 paper 发布的 checkpoint,作用是评价输入的隐藏状态的重要性,后续作者依据重要性选出 top-k 的隐藏状态作为沉思 token(沉思 token 定义:是推理链条压缩后的连续向量序列,具有语义意义,长度可调。),k 由超参数 r(压缩率,k=r*原始 CoT 的 token 数)指定。在具体实验中,作者选择 Transformer 第 T 层(实验中选择 3)的隐藏状态作为打分器的输入,并将打分器选出来的隐藏状态当做 ground truth 的沉思 token,使用 query 的隐藏状态和这些沉思 token 来训练 CCOT 模块
CCOT#
CCOT 的初始输入是第 l 层(实验中选择 15)的 query 的最后一个 hidden state,后续自回归生成
下图右侧的 END 是一个二分类器,用于判断是否还要继续生成沉思 token,除此之外,沉思 token 还有一个终止条件,就是生成了 h=200*r 个

下图有符号滥用,在其他地方 ^ 表示 ATTN,但是在这里表示预测
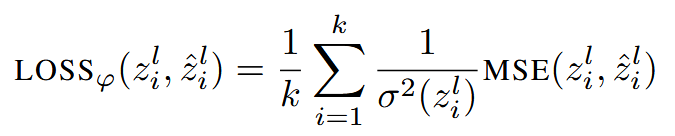
其中 σ²(z) 表示 z 的方差,MSE 表示两个向量之间的常规均方误差。
DECODE#
DECODE 也是自回归的,传入 query、沉思 token 和目前为止的答案 token \(a_{1:o}\)计算下一个答案 token 的分布 \(p_{1:o}\)
使用以下来训练 DECODE
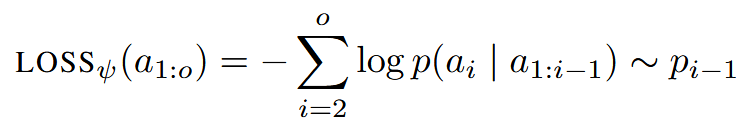
- 实验中取压缩率 r=0.05 和 r=0.10
实验#
数据集:GSM8K
模型:LLAMA2-7B-Chat
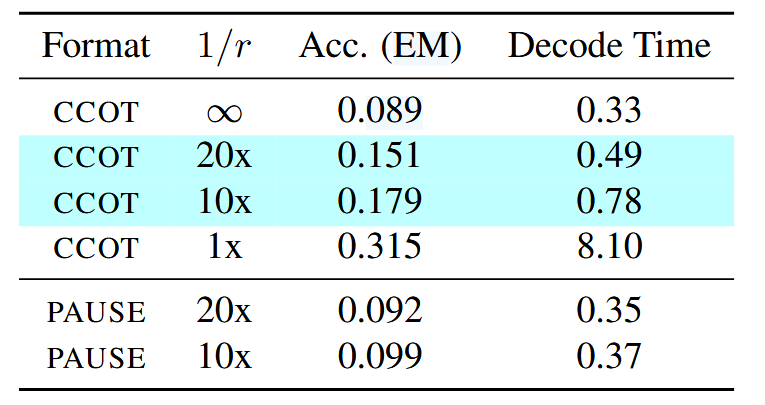
分别在 r=0.05 和 r=0.1 的情况下 finetune 了 CCOT,基线选择 r=0(直接输出答案)和 r=1(传统 CoT),也对比了 Pause Token
讨论#
超参数选择#
**r:**增加 r 会提高 acc 和解码时间,但是当 r=0.2 的时候 acc 就趋于平稳了,作者推测这是因为连续的沉思 token 是利用第 l 层的隐藏状态自回归解码的,这会传播对下一个沉思 token 生成的近似值。作者怀疑近似误差带来的噪声最终会超过沉思 token 提供的信号。
**l:**当 l 接近 0 或最后一层 L 时,我们无法为 CCOT 学习到良好的权重。我们推测,较早层(小 l)中的隐藏状态仍然包含大量关于 token 本身的局部信息,而较晚层(大 l)中反而融入了大量关于下一个 token 的局部信息。作者发现 l ≈ L/2 时表现最佳;推测中间层的隐藏状态编码了全局信息,使其适合我们用于生成沉思 token 的自回归解码方案。
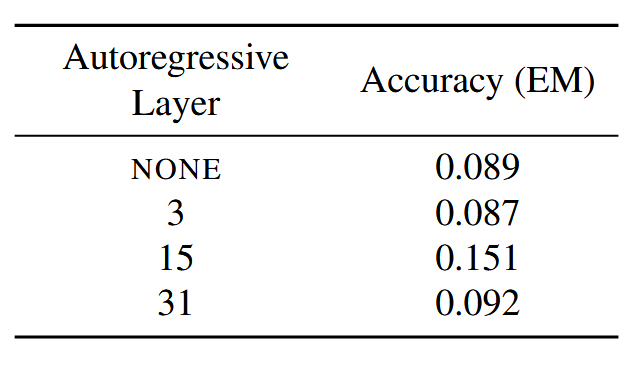
**打分器:**使用了一个预训练的评分模块来做子集选择,将选择出来的结果作为 CCOT 的 ground truth。在实践中,作者发现简单地选取 k 个等间距的 token 即可获得相似的性能。但是实际上使用打分器从原理上来说能实现无损性能。因此或许可以训练一个更好的打分器
一些备注#
Related Work 里有一些相关文章可以去读一下
- 记忆槽 https://arxiv. org/abs/2307.06945
- 动态压缩成小块 https://arxiv.org/abs/2310. 02409
- 低级缓存编码 https://doi. org/10.1145/3651890.3672274
- 仅使用 API 的 LLM(Prompt 水平) https: //arxiv.org/abs/2310.05736
Filler tokens:发现一种现象,在 CoT 中,如果仅使用……填充推理过程,也能提高模型的回答正确率