CODI: 通过自蒸馏将 CoT 压缩到连续空间中#
CODI: Compressing Chain-of-Thought into Continuous Space via Self-Distillation
这篇侧重于隐藏状态推理,但是我觉得也可以算压缩吧
Attention Sink:Q 和前面所有 K 计算的时候,关注大多在首尾,对于起始符关注较高
再加上会有信息迁移的现象,所以靠后的 token 关注度会比较高
摘要#
Chain-of-Thought (CoT) 通过使大型语言模型(LLMs)能够进行自然语言的逐步推理来增强其能力。然而,语言空间对于推理可能不是最优的。虽然隐式 CoT 方法试图在不使用显式的 CoT token 的情况下实现推理,但它们在任务性能上一直落后于显式 CoT 方法。我们提出 CODI(通过自蒸馏实现连续 Chain-of-Thought),这是一种新颖的框架,它将 CoT 蒸馏到一个连续空间中,在这个空间里,一个共享模型同时充当教师和学生角色,共同学习显式和隐式 CoT,同时在生成最终答案的 token 上对齐它们的隐藏激活。CODI 是第一个在 GSM8k 上与显式 CoT 性能相匹配的隐式 CoT 方法,同时还实现了 3.1 倍的压缩,准确率比之前最先进的方法高出 28.2%。此外,CODI 表现出在更复杂的 CoT 数据集上的可扩展性、鲁棒性和泛化能力。此外,CODI 通过解码其连续思维保持了解释性,使其推理过程透明。我们的发现确立了隐式 CoT 不仅是一种更高效而且是强大的替代方案,可以替代显式 CoT。
Motivation#
- 人类数学推理中大脑的语言区域并未被激活,因此自然语言推理可能不是最优的
- 隐藏状态的推理是稠密的,而自然语言推理是稀疏的
方法#
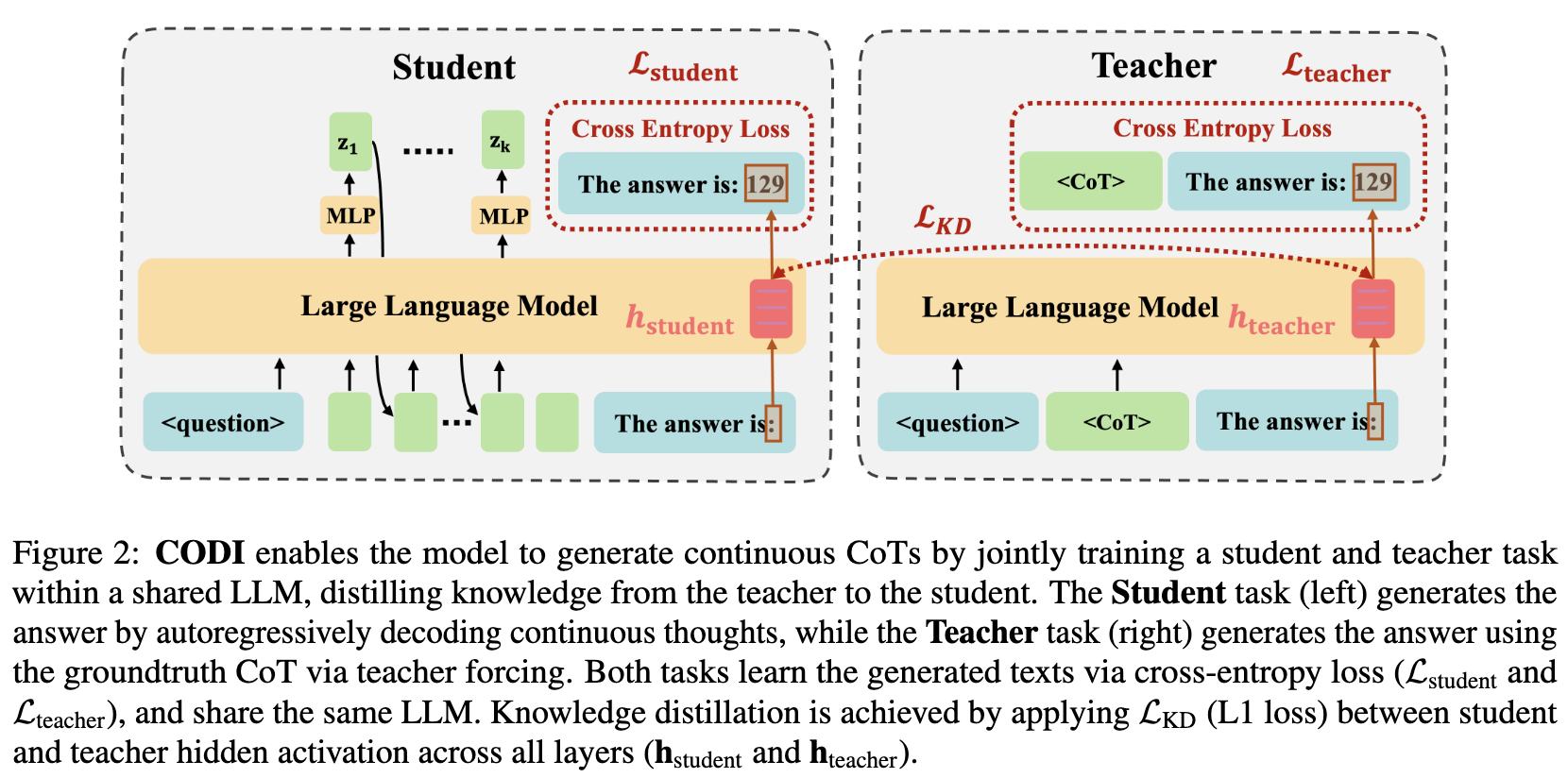
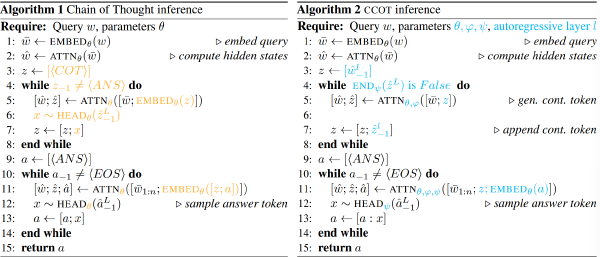
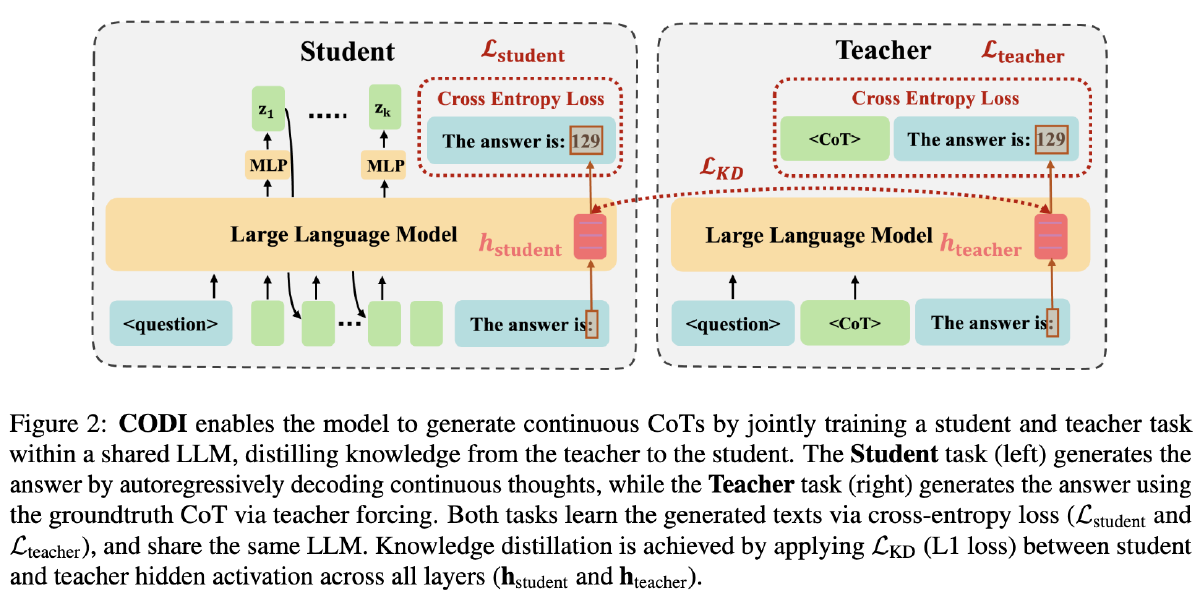
设计了一个自蒸馏框架,其中 Teacher 模型学习外显的 CoT,而 Student 学习隐式的 CoT
学生的最终回答计算出 L_student,教师的回答计算出 L_teacher,将教师模型中的关键 token 的隐藏激活与学生模型的对应部分计算 L_KD
最终 Loss:(三个系数是三个超参,看代码均设置为 1,论文中未提及)
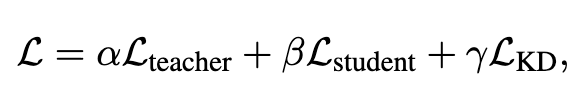
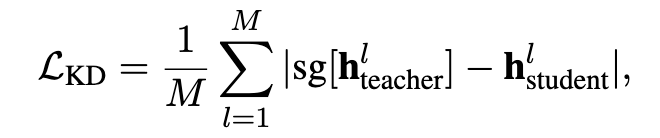
在模型架构方面,仅对学生模型进行了修改,增加了两个特殊 Token,BoT 和 EoT、一个两层的 MLP+ 归一化将隐藏状态改成 Token
学生的推理步骤如下:输入问题、手动插入 BoT、计算 n(超参数,看代码设置为 6,论文中提到 6 个步骤足够大多数 CoT 任务)个步骤、手动插入 EoT、自然语言给出答案
实验#
似乎未提到训练时的硬件资源,只提到了推理时使用一张 A100(应该是 80G)
训练数据集:GSM8k-Aug 和 GSM8k-Aug-NL
测试数据集:上述数据集、SVAMP、GSM-HARD、MultiArith、MAWPS
baseline:
- CoT-SFT(temperature 设置 0.1,取 10 次的平均值)
- No-CoT-SFT(不生成中间步骤)
- iCoT(另一种隐藏状态推理的模型)
- Coconut(截止发文时的隐藏状态推理的 SOTA)
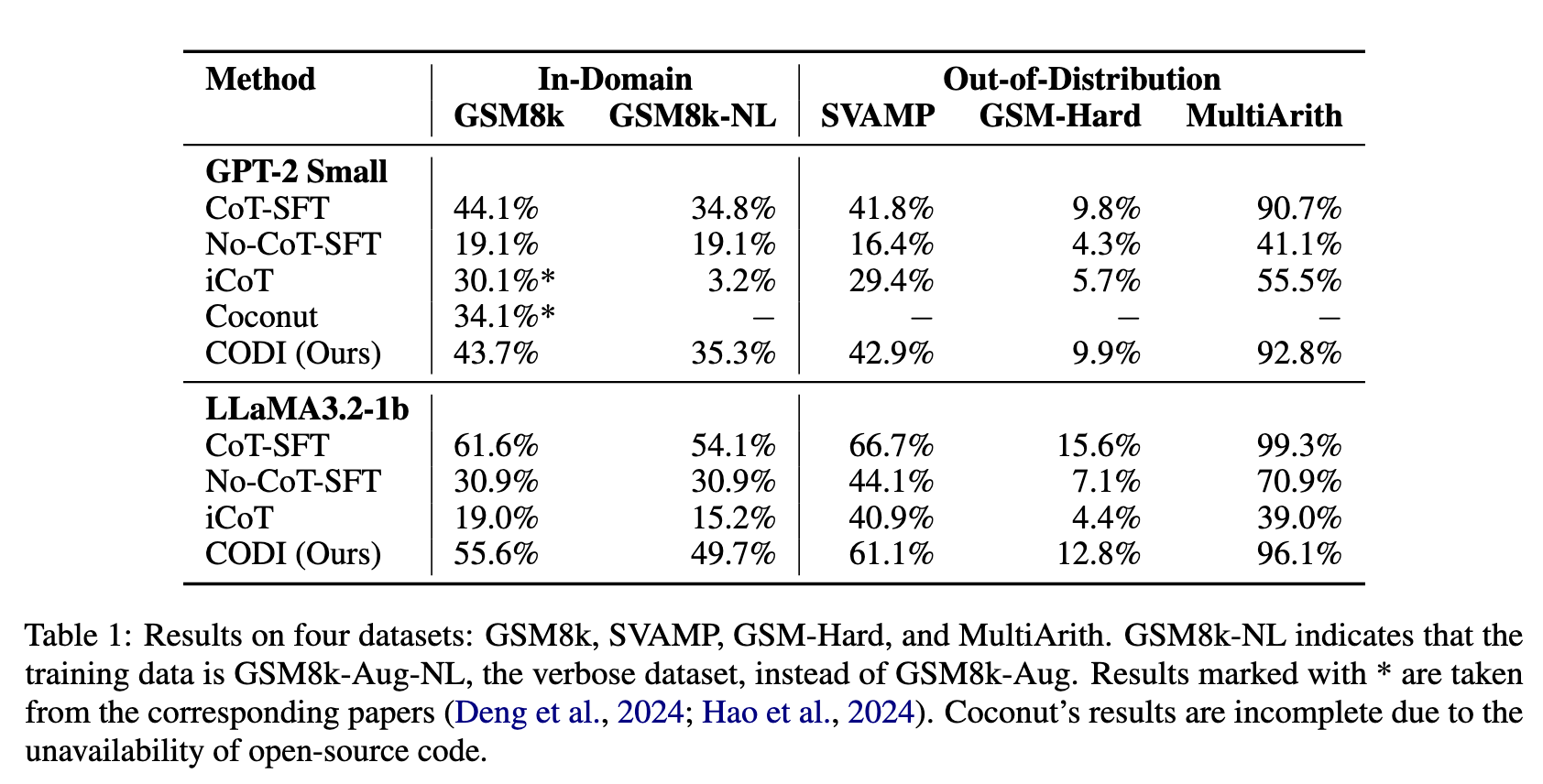
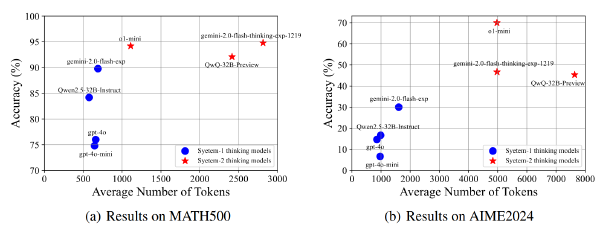
ACC 与 CoT-SFT 相差无大、优于其他隐藏状态推理
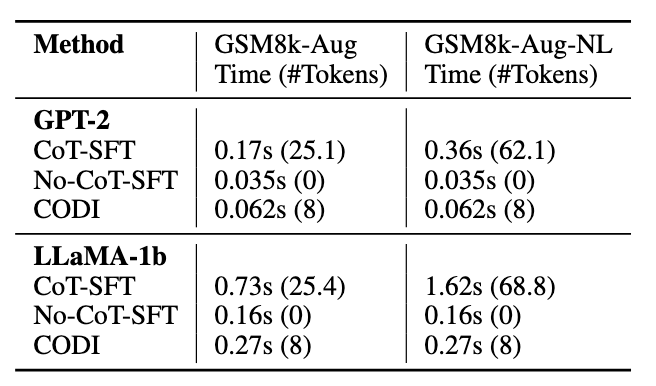
Token 数量也赢!