DEER:基于 Trial 置信度的推理早停#
DYNAMIC EARLY EXIT IN REASONING MODELS
摘要#
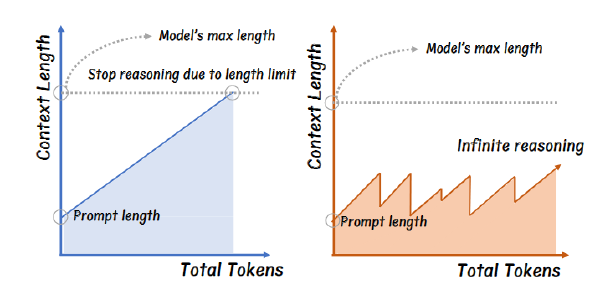
近期大型推理语言模型(LRLMs)的进展依赖于测试时扩展,这将长链条思维(CoT)生成延伸以解决复杂任务。然而,过长的 CoT 不仅会降低问题解决的效率,还可能因过于详细或冗余的推理步骤而导致准确性损失。我们提出了一种简单而有效的方法,允许大型语言模型(LLMs)在生成过程中通过早期退出机制自我截断 CoT 序列。与依赖固定启发式规则不同,所提出的方法在潜在的推理转换点(例如,“Wait” tokens)监测模型行为,并在模型对试探性答案表现出高置信度时动态终止下一推理链的生成。我们的方法无需额外训练,可无缝集成到现有的类似 o1 推理 LLMs 中。在多个推理基准测试 MATH-500、AMC 2023、GPQA Diamond 和 AIME 2024 上的实验表明,所提出的方法在 deepseek 系列推理 LLMs 上始终有效,平均将 CoT 序列长度减少 31% 至 43%,同时将准确性提高 1.7% 至 5.7%。
Motivation#
- 过长 CoT 显著增加计算开销、推理延迟
- 过长 CoT 可能偏离正确道路导致 Acc 下降
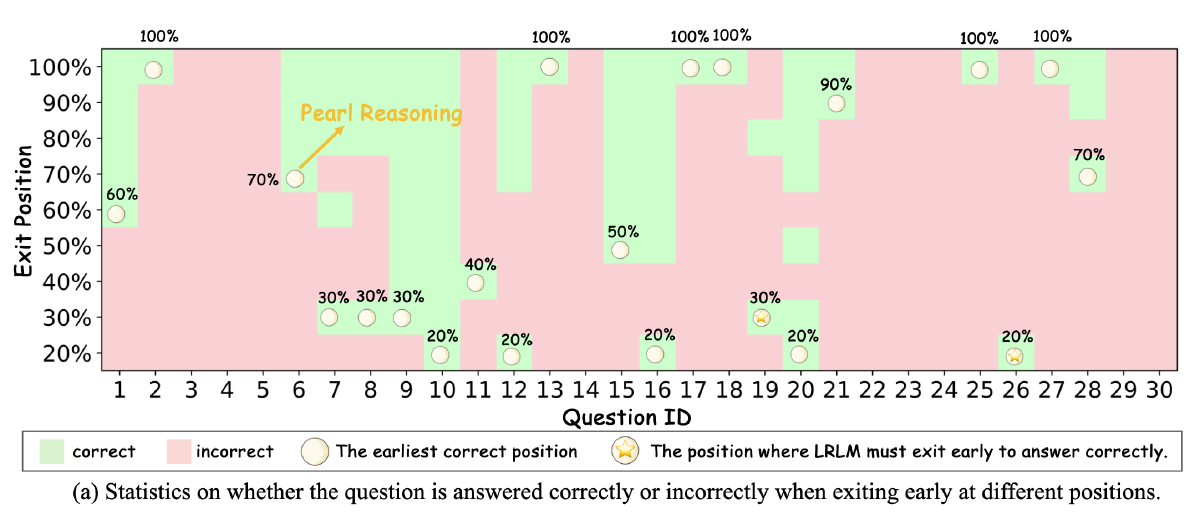
- 推理信息中具有信息刚刚好足够的关键点(Pearl Reasoning)
验证 Motivation 3#
选择 AIME2024 数据集,让 DeepSeek-R1-Distill-Qwen-14B 进行完整推理和解答,然后从 think 过程中找出“Wait”这个 token,基于这个 token 将完整的推理划分为思考片段,然后仅保留 len(思考片段) > 5 的样本。对于这些样本保留了其不同比例(20%-90%)的思考片段,并在每个截断的推理序列末尾添加了一个结束思考的 token 分隔符,以强制终止慢思考过程。结果如下图
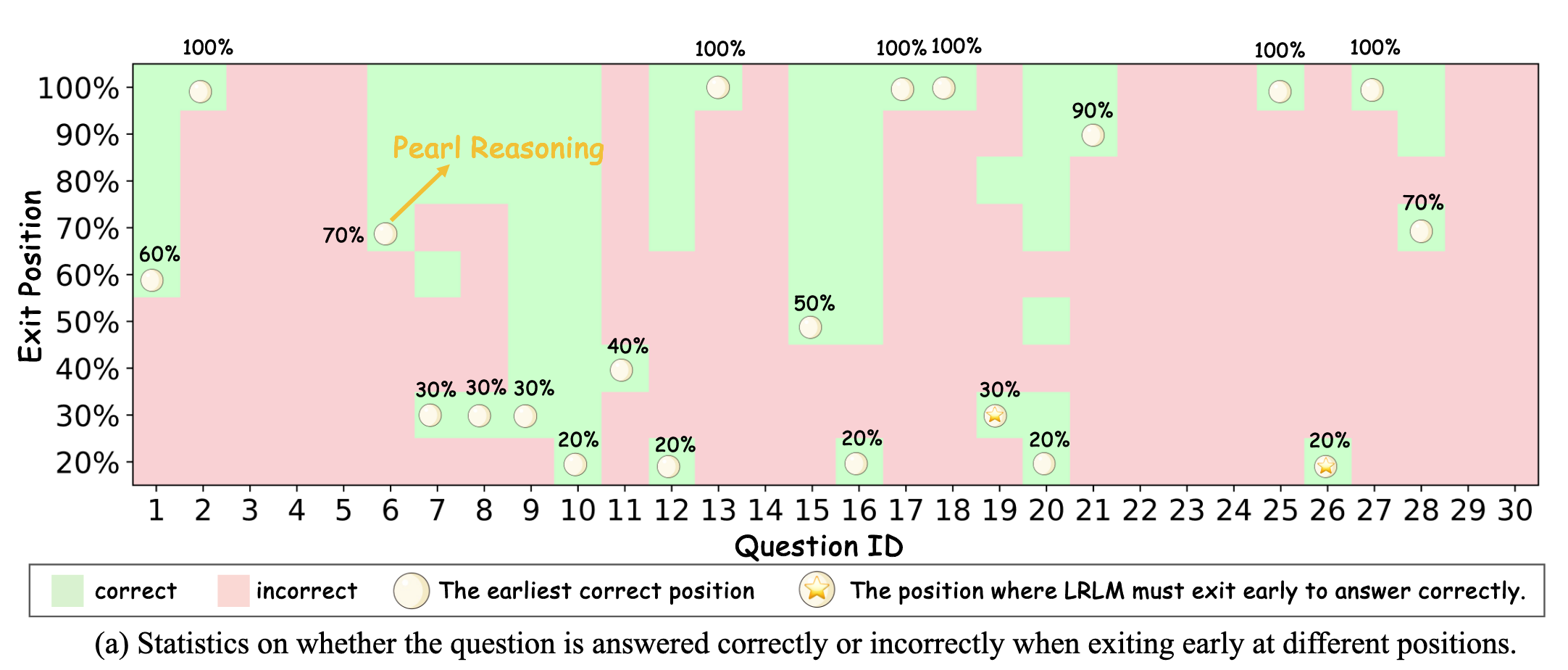
LLM 对于大多数问题(75%)的推理具备这样一个 Pearl Reasoning,甚至部分(36.7%)问题的 pearl reasoning 还不到原问题的一半。
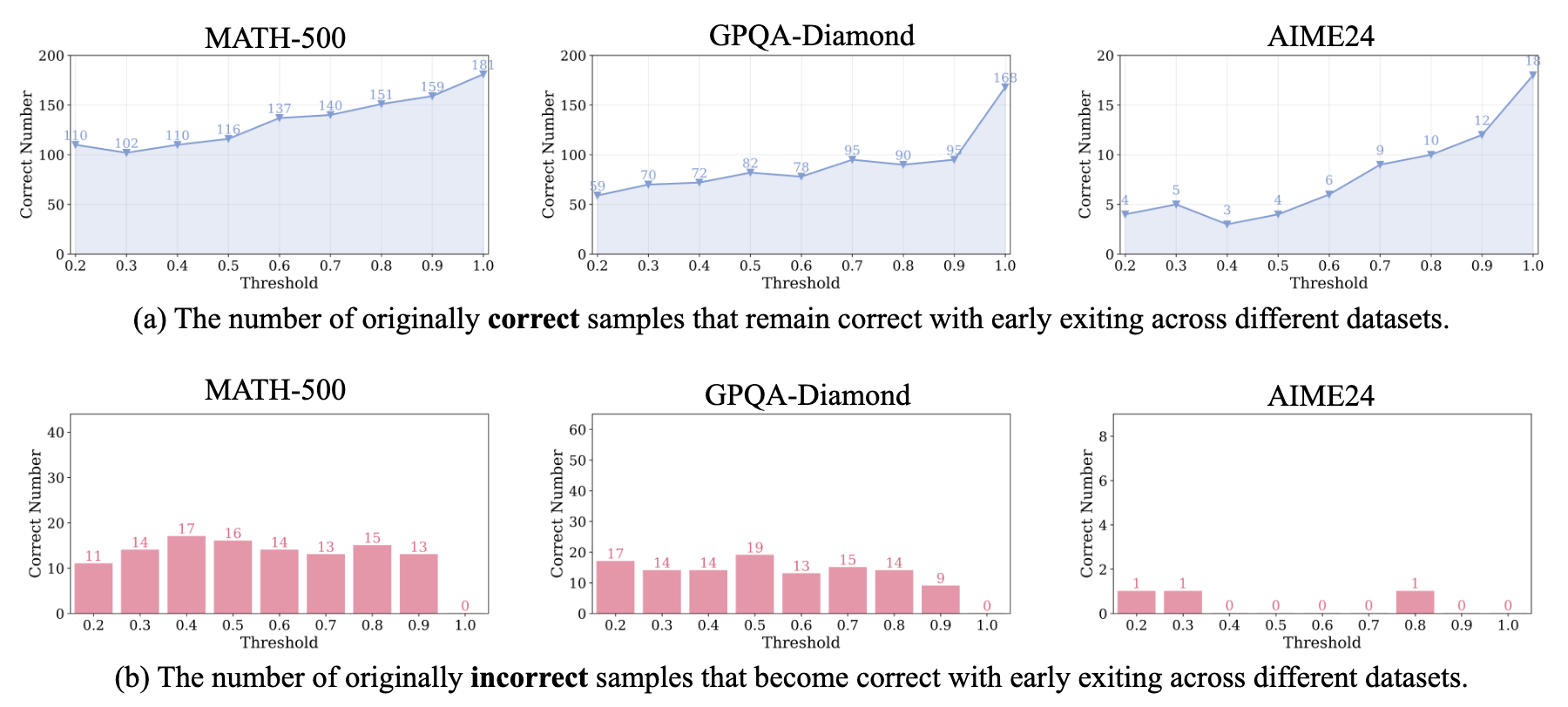
此外,还验证了一下原始推理是正确/错误的但是使用早停机制后正确的数量(Threshold 为 1.0 代表原始推理)
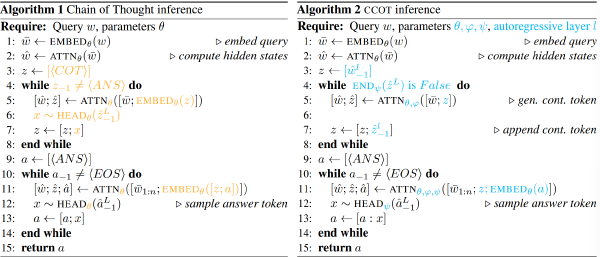
Method#
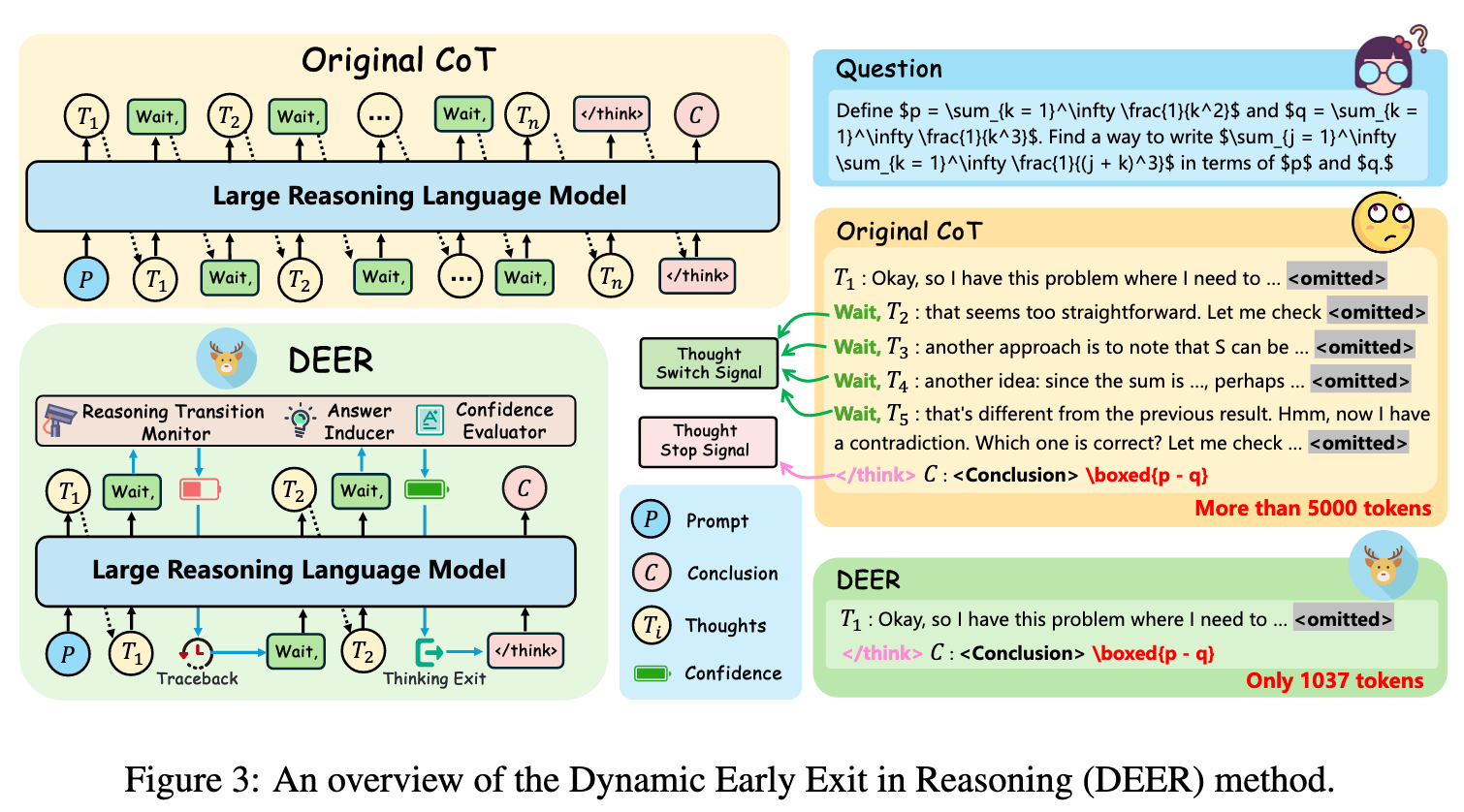
识别出推理中信息刚刚好充足的关键点(Pearl Reasoning),并迫使模型在这一步停止思考转为开始回答,提出三步走方法来识别关键点:
- 推理转换监控
像“Wait”这样的词识别为推理转换的关键点,并对其出现进行监测。出现以后进入下一步
- 试验性答案诱导
将最后的“Wait”替换为“Final Answer”,来诱导 model 尝试给出答案
- 置信度评估
计算试答的置信度,如果试答的置信度够高,就让 LLM 基于已生成的想法直接给出结论;否则就撤回替换那一步,让 LLM 继续推理
$$ A=LRLM(P,T,I) $$P 代表输入的 Prompt,T 是目前已经生成的 Thought,I 代表引导回答的 token,A 代表着 final answer token 后的东西,由很多 token 组成的 token 序列:\(A=[a_1,a_2,a_3,……a_n]\)
通过下面的公式计算 A 的置信度,下图中 M 为 LM Head 及其前置组件,以 logits 作为输出。
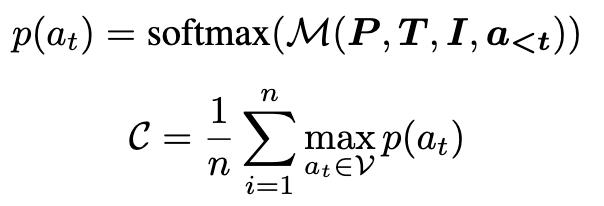
如果置信度 c 大于阈值 \(\lambda\)(超参),则认为到了 Pearl Reasoning。

小优化#
当推理出现 Wait 的时候,不是停止继续推理,而是通过 Attention Mask 进行继续往下推理和试着回答的并行,并通过基于置信度的动态 KV 缓存管理进行剪枝。
实验#
数据集:
- 数学:MATH-500、AMC 2023、AIME 2024、GPQA Diamond
- 编程:HumanEval、BigCodeBench
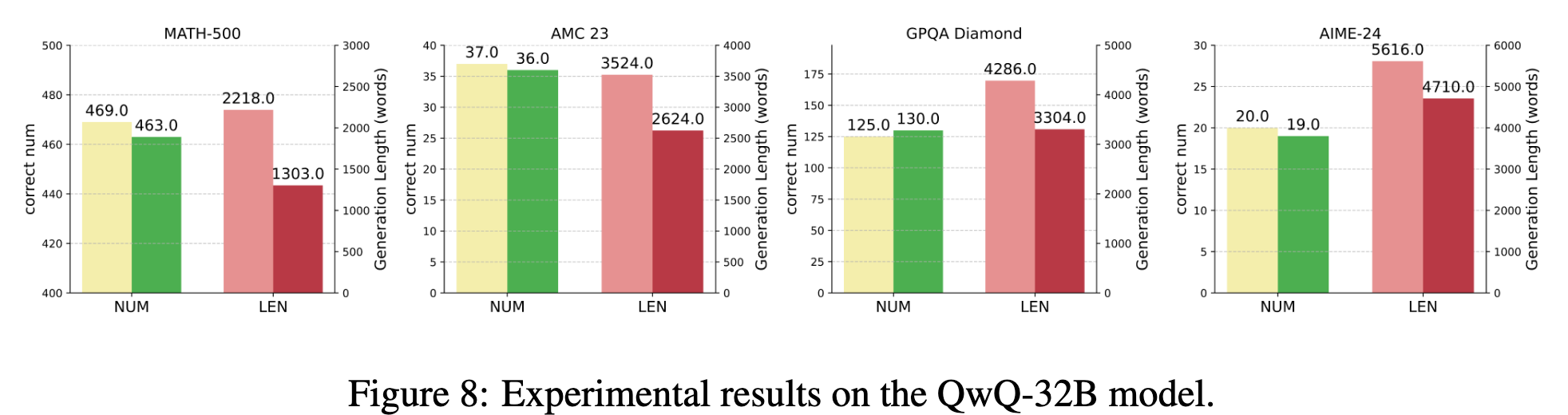
模型:DeepSeek-R1-Distill-Qwen 系列 1.5B、7B、14B、32B,额外测了 QwQ-32B
超参:max_len=16384
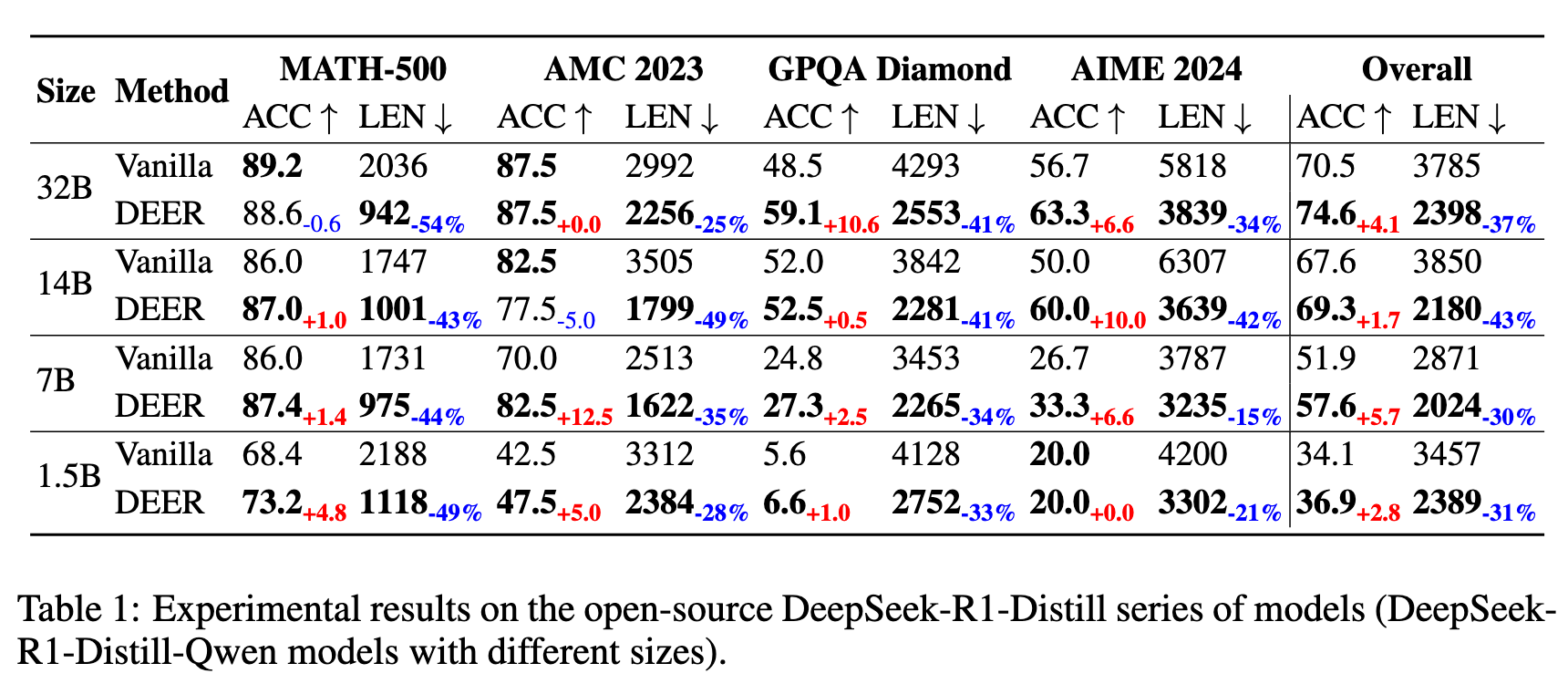
其他现象#
- DEER 纠正的错误比 DEER 造成的错误多(绿色部分多于红色部分)
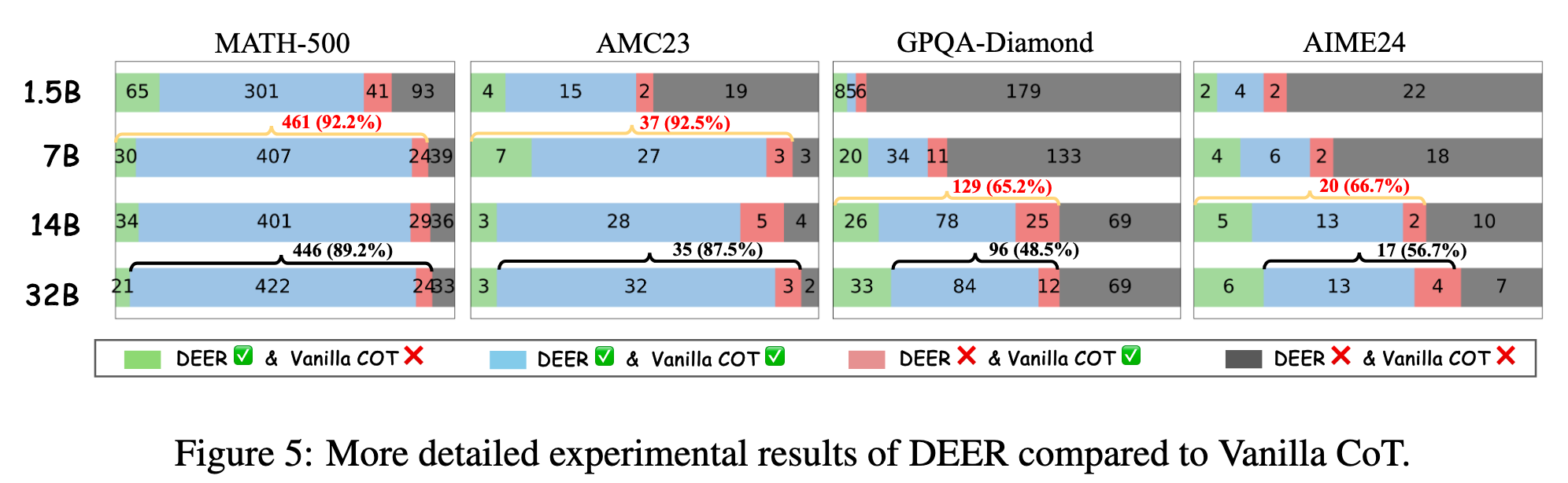
- 如果 DEER 能在红色样本上避免过早退出,在在 AMC23 上 7B 模型能打败 14B 模型,因此可以研究如何修改早停策略
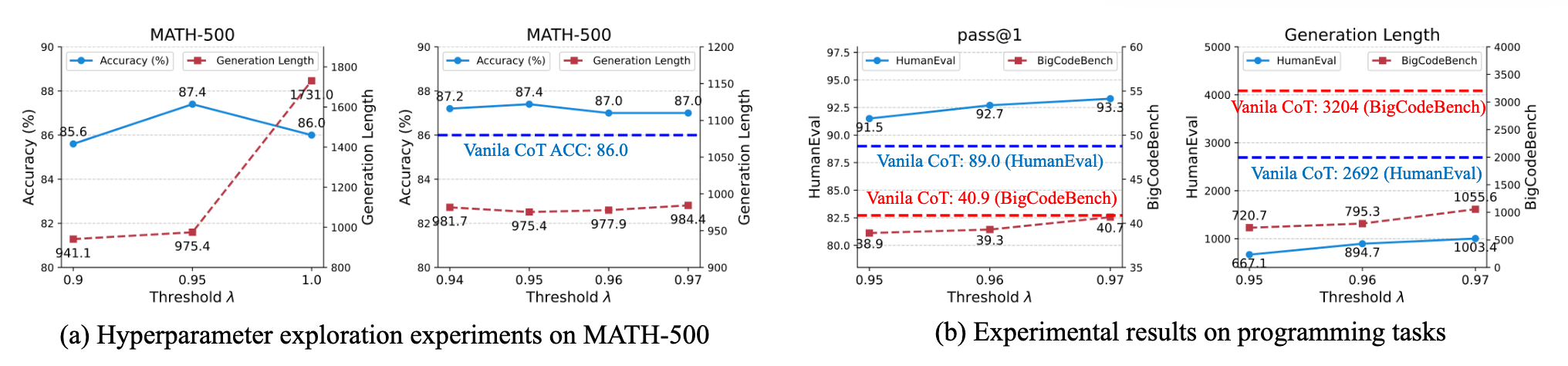
- 一系列 \(\lambda\)和编程数据集
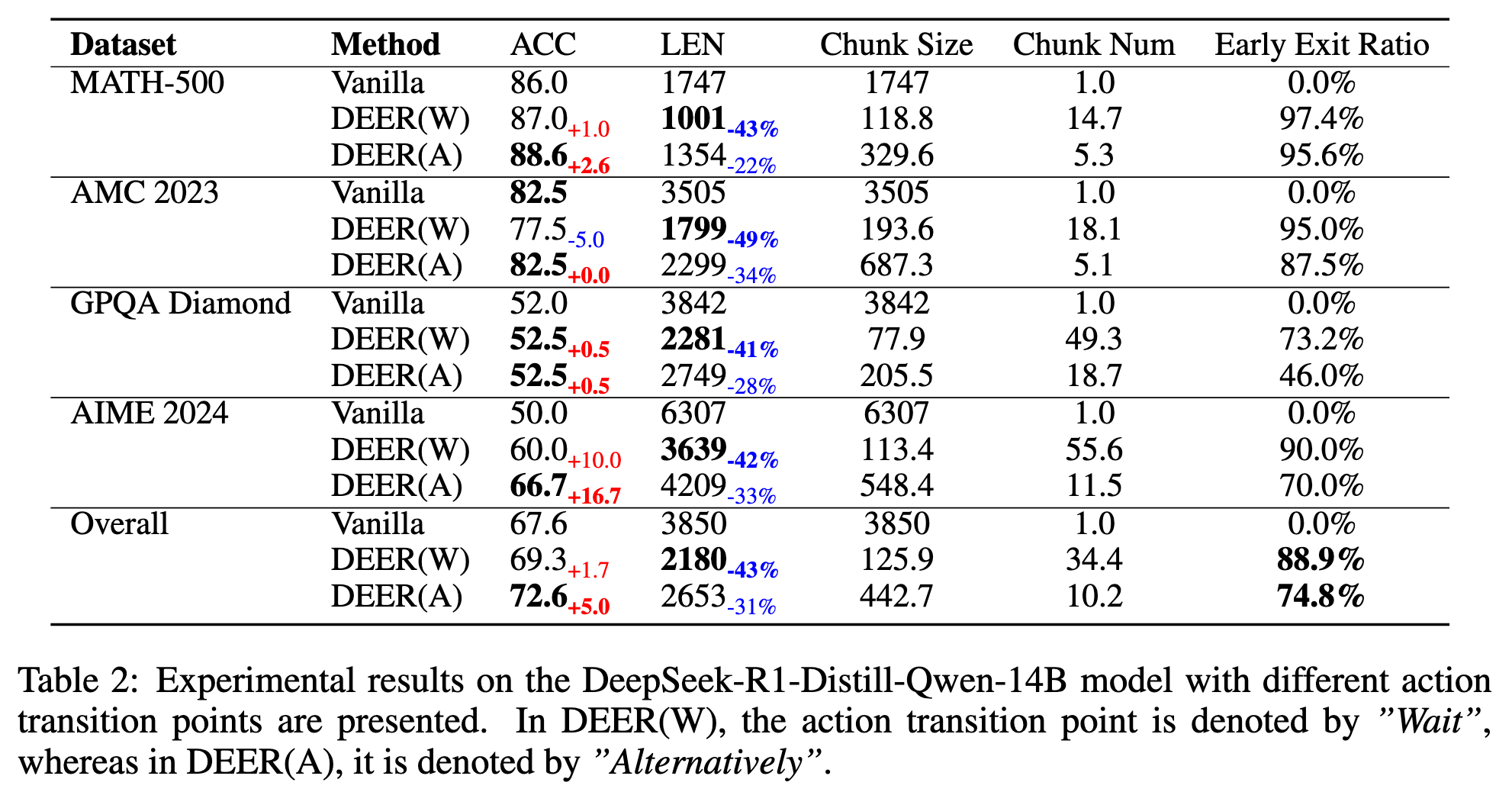
- 监控其他的推理分界线
DEER(W)是 Wait,DEER(A)是 Alternatively
- 在 QwQ-32B 上的实验