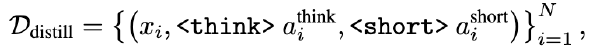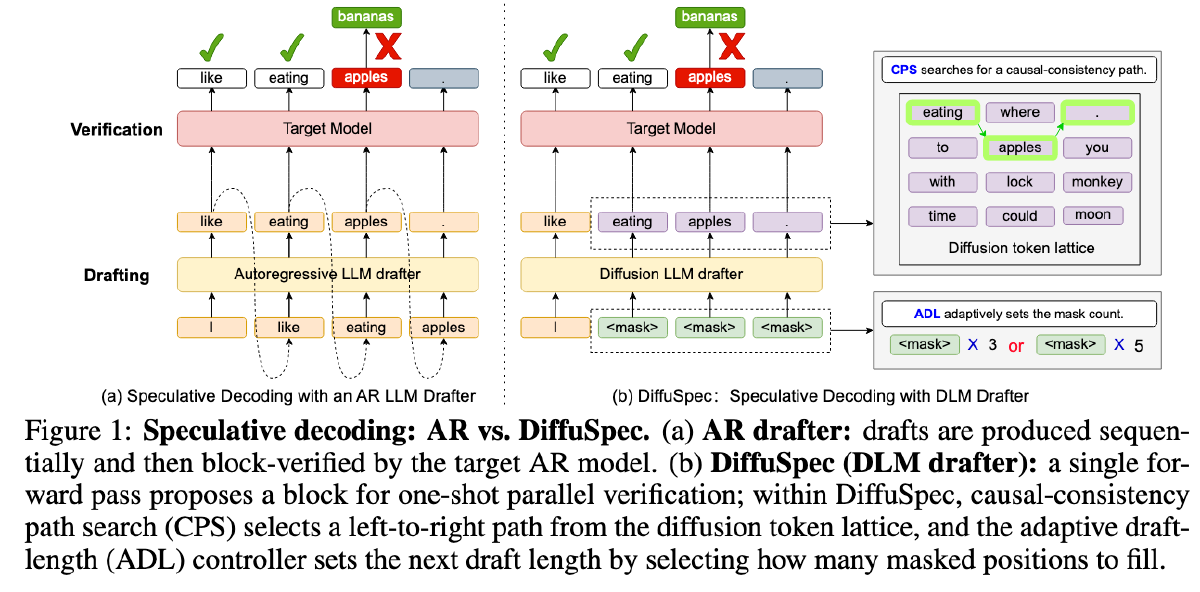
DiffuSpec:解锁 DLM 做投机采样#
DIFFUSPEC: UNLOCKING DIFFUSION LANGUAGE MODELS FOR SPECULATIVE DECODING
摘要#
随着大语言模型(LLMs)规模的扩大,准确性得到提升,但解码过程的自回归(AR)特性导致延迟增加,因为每个 token 都需要一次串行的前向传播。推测性解码通过引入一个快速的起草模型来提出多 token 草案,并由目标模型并行验证这些草案,从而缓解该问题。然而,许多部署仍依赖于自回归(AR)起草模型,其串行计算限制了实际时钟时间的加速效果。我们重新审视了起草阶段,提出了 DiffuSpec——一种无需训练、可直接集成的框架,利用预训练的扩散语言模型(DLM)在单次前向传播中生成多 token 草案,同时保持与标准自回归验证器的兼容性。由于 DLM 草案是在双向条件下生成的,各位置并行生成的候选 token 构成一个 token 格,其中每个位置局部概率最高的 token 并不一定形成符合因果顺序的从左到右路径。此外,DLM 起草需要预先指定草案长度,这引入了速度与质量之间的权衡。为应对这些挑战,我们引入两个实用组件:(i)在该格上进行的因果一致性路径搜索(CPS),用于提取一条与自回归验证对齐的从左到右路径;(ii)自适应草案长度(ADL)控制器,根据最近的接受反馈和实际生成长度动态调整下一次提案的大小。在多个基准测试中,DiffuSpec 实现了最高达 3 倍的时钟时间加速,确立了基于扩散模型的起草方法作为推测性解码中自回归起草器的一种稳健替代方案。
Motivation#
dlm 可以在一次 forward 中给出一整个 block 的 token 候选,并可选的对这些 token 进行迭代优化。这些能力刚好契合 draft 的核心需求——更高的吞吐量和更高质量的候选提议。然而 dlm 的 token 是在上下文同时作用下生成的,而非严格的从左到右的因果依赖。这导致形成一个扩散 token 格(diffusion token lattice),其节点为每个位置上的候选 token,其中局部最高概率的 token 未必构成一条符合因果性的从左到右路径。此外,DLM 生成需要预先设定草稿长度。这些特性共同引出了我们研究的两个实际问题:(i)因果对齐:如何从该格结构中选择一条与自回归(AR)验证相一致的从左到右路径以最大化接受率;以及(ii)草稿长度:**如何选择块大小以在生成成本和验证接受率之间取得平衡,因为更长的草稿会增加提议成本,却不能保证更高的接受率。**尽管已有并行工作开始探索基于扩散的 drafters(Christopher et al., 2024),但一种无需训练、即插即用且系统性处理因果一致性与草稿长度的框架仍缺乏充分研究。
方法#
因果一致的路径搜索(Causal-Consistency Path Search,CPS)#
dlm 对于每个 token 会生成很多 logits,基于这些 logits 计算出该 token 不同选项的概率,找到累计概率大于等于 \(\tau\)(超参数,0.8) 的地方,保留所有候选项
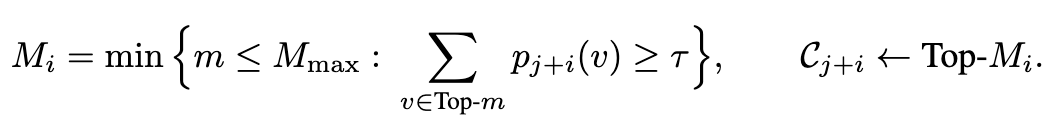
如果候选项太多,则只保留 M_max 个(超参数,15)
然后对于保留下来的所有路径使用 n-gram 或小的因果 LM 打分(论文中使用 3-gram KenLM)
\(\pi\)代表一条路径, \(\pi_i\)代表路径中第 i 个 token,使用下面的函数对于推理路径进行综合打分,中括号内左侧代表 lambda 乘 dlm 自己对这个 token 的概率,右侧是(1-lambda)乘小因果 LM 对这个 token 的概率,lambda 是一个超参数(0.5)
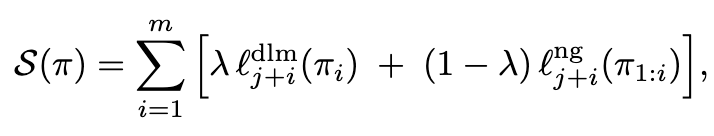
这样实现了 dlm 和因果的综合打分,选出得分最高的路径,传入后续步骤
自适应草稿长度(ADAPTIVE DRAFT LENGTH,ADL)#
Motivation#
草案长度 kt 共同决定了起草成本、提案质量和验证器接受率。较短的草案往往产生简略的片段;适中的草案能够捕捉更完整的推理过程;而过长的草案则会使内容饱和并触发提前的 EOS,同时积累大量偏离路径的 token,这些 token 会被验证器拒绝。从经验上看,EOS 感知的生成长度 Lgen 随 kt 增加而后趋于饱和,且被接受的长度 Lacc 跟随其变化
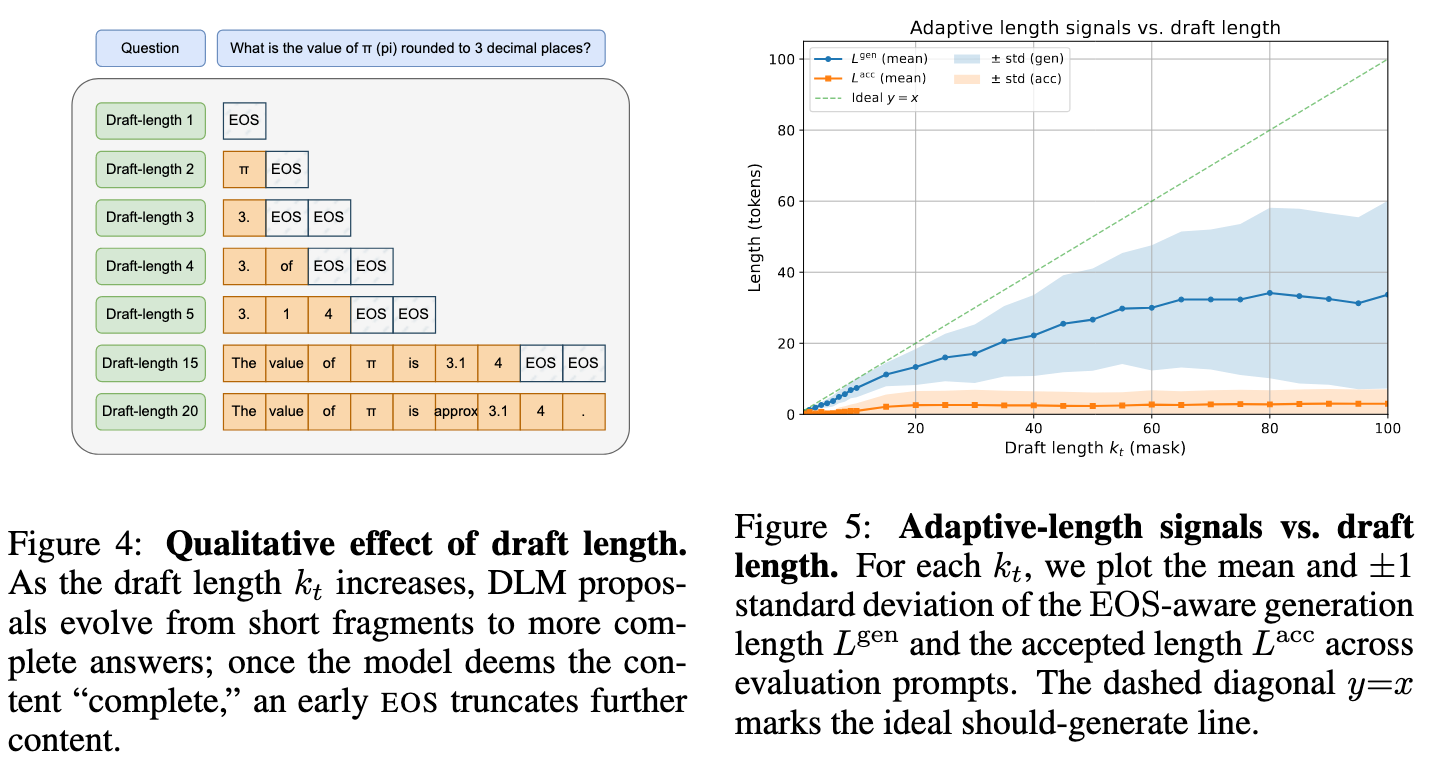
固定的 kt 要么在过长时浪费计算资源,要么在过短时限制进展,这促使我们引入一种自适应控制器。
方法#
在 CPS 之前,先计算 draft 在 EOS 前生成了多少 token,如果没有 EOS 就是生成的 draft length,获得 \(L^{gen}_t\);并设 CPS 后 Target 接受的长度为\(L^{acc}_t\),其中 t 是投机采样中的解码轮次,target 做了几次 verify,t 就是几
为了避免不同的 t 之间差异太大导致方差太大(图 5 的蓝色阴影部分),作者对于上面的两个 L 进行了平滑处理
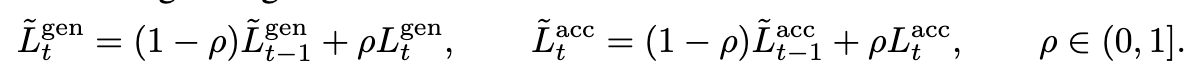
其中 \(\rho\)也是超参数(0.5)
于是更新下一次的 draft token 数如下:
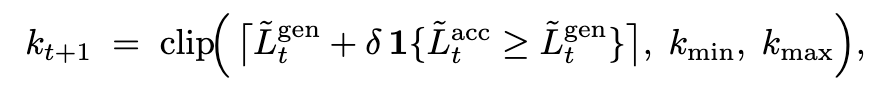
delta(10),k_min=20, k_max=30
合并 CPS 和 ADL#

实验#
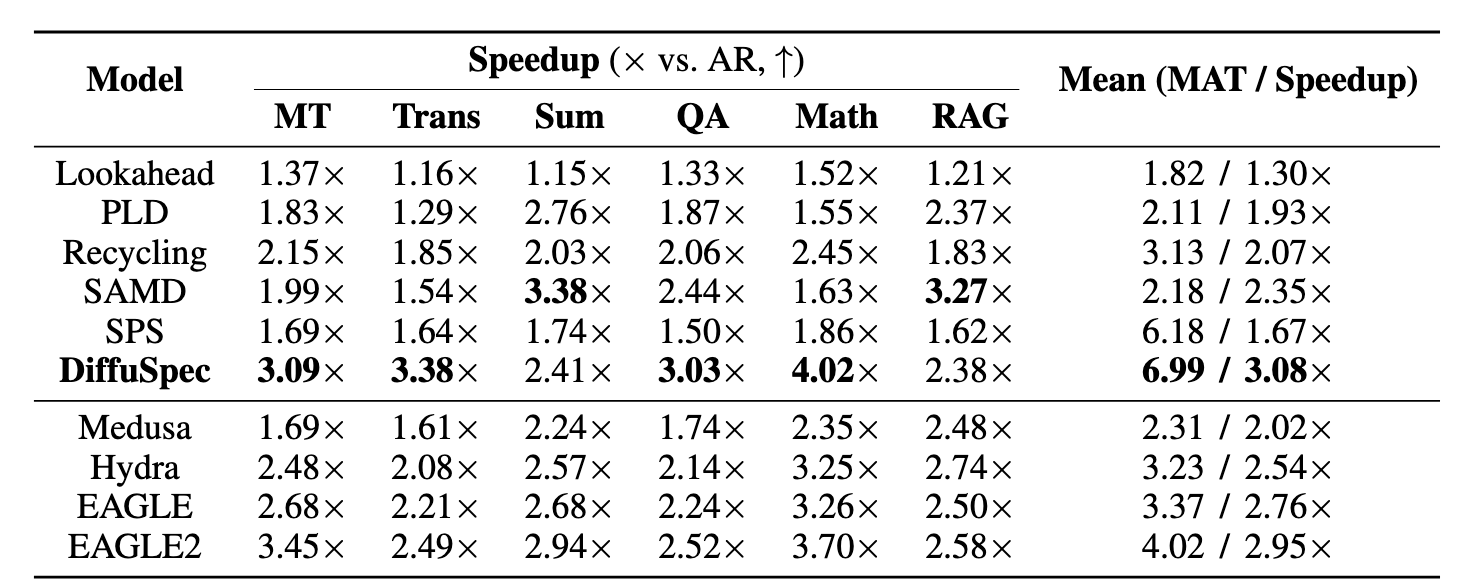
数据集:Multiturn Conversation(MT)、Machine Translation(Trans)、Summarization(Sum)、Open-domain QA(QA)、Mathematical Reasoning(Math)、Retrieval-Augmented Generation(RAG)
指标:平均接受 Token 数(Mean Accepted Tokens, MAT)、比 AR 贪婪采样加速比(Speedup)
Baseline:
Training Free
- 经典的投机采样(SPS)
- 前瞻性解码 Lookahead(构造[I, love, [MASK], [MASK]],使用 Target 并行预测多个 MASK,并将预测出来的内容拼起来当作草稿,再输入 Target 进行验证)
- PLD(适用于 few-shot 提示,拿 answer 的前缀去 prompt 做 n-gram,并将匹配到的内容作为 draft 送入 Target)
- Recycling(维护一个 token 图,将被接受的 token 序列放入图中,下次遇到相似的 token 直接在图里进行 BFS,将 BFS 的结果作为 draft 送入 Target)
- SAMD(维护一个大型 offline 的语料库,如果匹配到了类似的字符串前缀则直接取出相关语料作为 draft 送入 Target)
Training Based
- Medusa(给模型增加多个预测 head,基于当前的 hidden state 估算未来几个 token,有点像 lookahead)
- Hydra(类似 Medusa,但是每个 head 使用的是上一个 head 给出的 hidden state,将 Medusa 的并行改为了串行,但是提高了草稿质量实现了加速)
- EAGLE(为模型增加 EAGLE predictor heads,在单次前向传播中预测未来多个 token,同时增加一个自回归验证信号 (accept/reject),用以估计每个 token 是否能被 Target 接受)
- EAGLE2(改进 EAGLE,添加动态 draft length、模型内部学习“何时应该停”与“何时继续预测”,即自适应验证边界)
模型:Target Qwen2.5-32B、Draft Dream-7B
由于 Training based 的方法没有兼容 Qwen2.5-32B 的 checkpoints 开源,所以作者选择汇报 Vicuna-33B 的结果
其他细节:A100、bs=1、启用 KV cache、DiffuSpec 设置 step=1
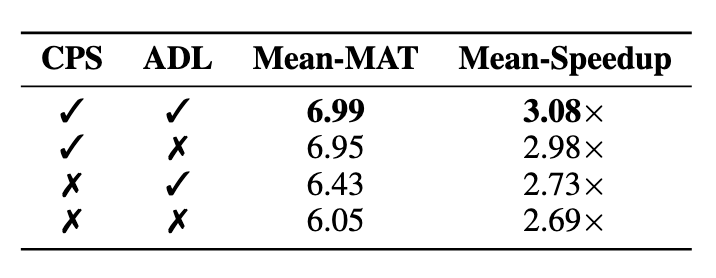
消融#