Fast-dLLM:通过 KV Cache 和并行 Decoding 加速 dLLM#
Fast-dLLM: Training-free Acceleration of Diffusion LLM by Enabling KV Cache and Parallel Decoding
摘要#
基于扩散的大型语言模型(Diffusion LLMs)在非自回归文本生成方面表现出潜力。然而,由于缺乏 KV Cache 以及在同时解码多个 token 时的质量退化,开源 Diffusion LLMs 的实际推理速度通常落后于自回归模型。为了弥补这一差距,我们引入了 Fast-dLLM,这是一种针对双向扩散模型设计的新颖分块近似 KV 缓存机制,能够在性能下降可忽略的情况下实现缓存重用。此外,我们识别出并行解码中生成质量退化的主要原因是条件独立性假设下标记依赖关系的破坏。为了解决这个问题,Fast-dLLM 还提出了一种置信度感知的并行解码策略,仅对超过置信度阈值的标记进行解码,从而缓解依赖关系冲突并保持生成质量。在 LLaDA 和 Dream 模型上的实验结果表明,在准确率损失最小的情况下,吞吐量提升了最高 27.6 倍,缩小了与自回归模型的性能差距,并为 Diffusion LLMs 的实际部署铺平了道路。
Motivation#
- dLLM 生成快,因为有并行 token 生成的潜力以及双向注意力机制
- 目前的 dLLM 没有 KV Cache,所以在实际应用中并不如 AR(autoregressive)模型,且 dLLM 同时生成多个 token 时,其质量会下降。
Masked Diffusion Model(MDM)生成过程#
设在某时刻,整句话的噪声水平为 \(t \in (0,1]\),MDM 的功能就是让下一时刻,这句话的噪声水平为 \(s \in [0, t)\),也就是进行降噪。而整句话降噪完成的概率=每个 token 降噪完成的概率的乘积,即(设这句话有 n 个 token):
\(q_{s|t}=\prod_{i=0}^{n-1} q_{s|t}(x_s^i \mid x_t)\)
其中如果 \(x_t^i\)已经生成(不为 MASK),则\(q_{s|t}(x_s^i \mid x_t)=1\)(因为已经生成了,不需要修改了)
如果\(x_t^i\)未生成(为 MASK),则有\(\frac st\)的概率保持 MASK(例如从 t=1 降噪到 s=0.3,还剩余 30% 的 token 未生成),而有\(1-\frac st\)的概率生成一个 token,且该 token 取自于\(q_{0|t}(x_s^i \mid x_t)\)
$$ q_{s|t}(x_s^i \mid x_t) = \begin{cases} 1, & x_t^i \neq [MASK], \; x_s^i = x_t^i \\[6pt] \frac{s}{t}, & x_t^i = [MASK], \; x_s^i = [MASK] \\[6pt] \frac{t-s}{t} \, q_{0|t}(x_s^i \mid x_t), & x_t^i = [MASK], \; x_s^i \neq [MASK] \end{cases} $$并行 Decoding 的问题#
如果让 dLLM 补全下面这句话:
两个字组成的扑克牌牌型是:[MASK][MASK]。
可选答案有“同花”、“顺子”、“葫芦”、“高牌”等,如果是 AR 模型,当生成第一个字(比如“同”)之后下次 forward 会参考第一个字生成第二个字(“花”)。
但是对于 dLLM,目前的采样方法是先为每个 token 生成一个概率分布,然后从这些分布中独立采样。这样就很可能导致不理想的组合,比如“同子”。
所以并不能独立采样,而应当在联合概率中考虑依赖关系
方法#
块级 Decoding 的 KV Cache#
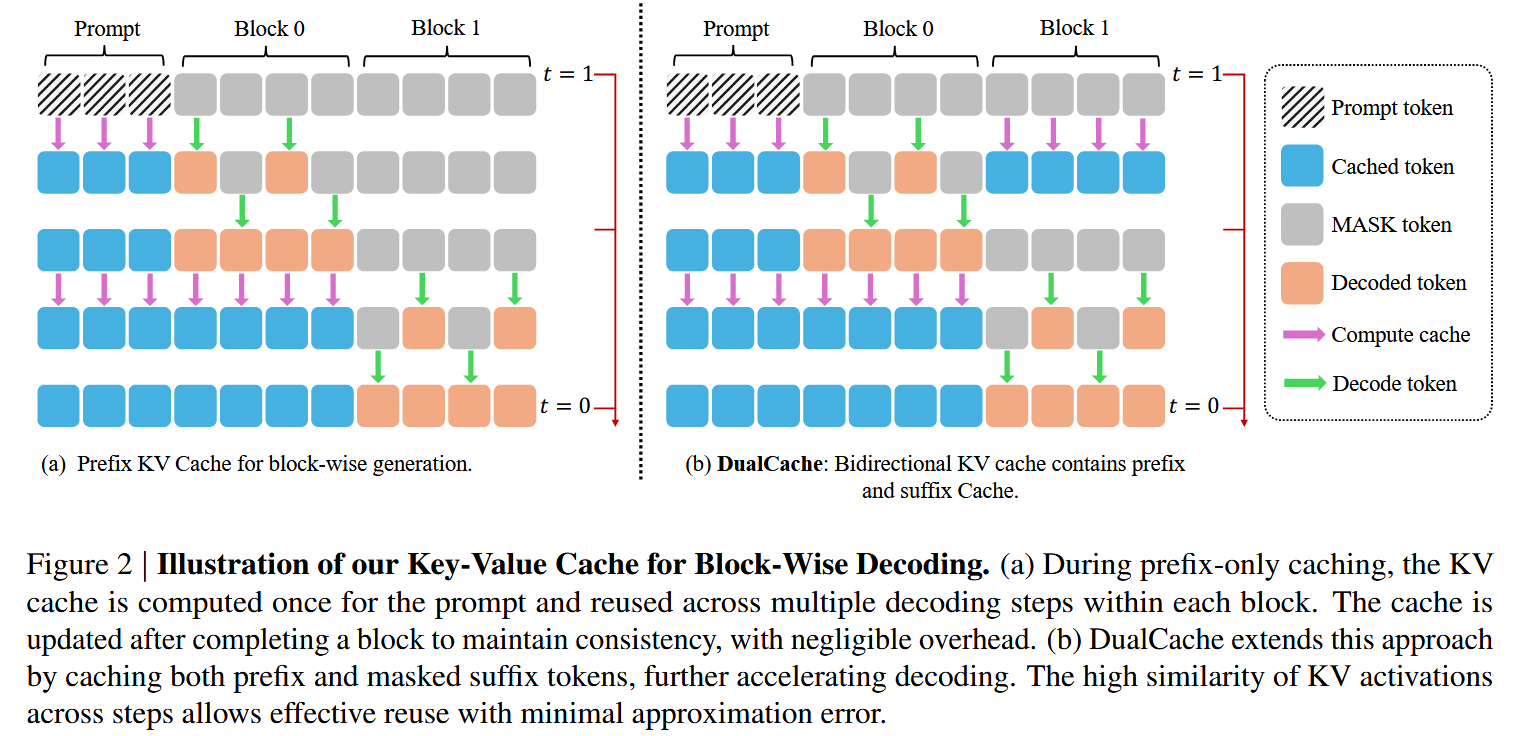
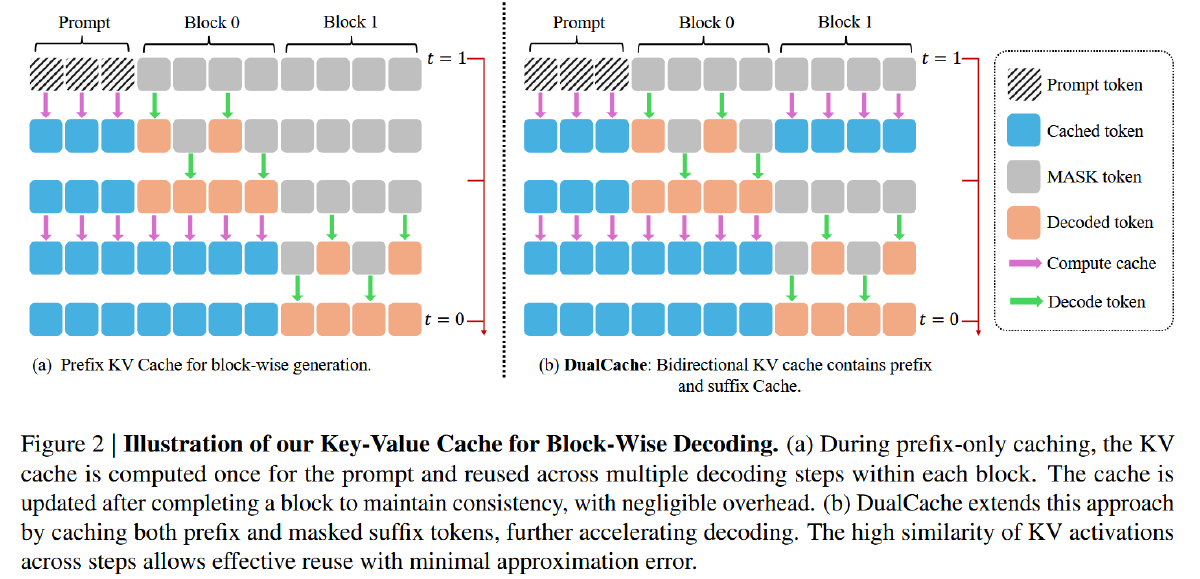
左侧图——前缀 KV Cache(Prefix KV Cache)#
先计算 Prompt 的 KV Cache,并在其相邻的下一个 Block(Block0)中使用,基于 Prompt Cache 生成 Block0 之后,基于 Prompt Cache 和 Block0 生成新的 Prompt+Block0 Cache(Block1 第一次去噪的时候顺便生成的,所以没有额外计算),用于生成 Block1
在第一次去噪完成后,Block0 就生成了两个 token,按道理应当基于这两个 token 更新一下 Cache,可是并没有,作者解释如下:
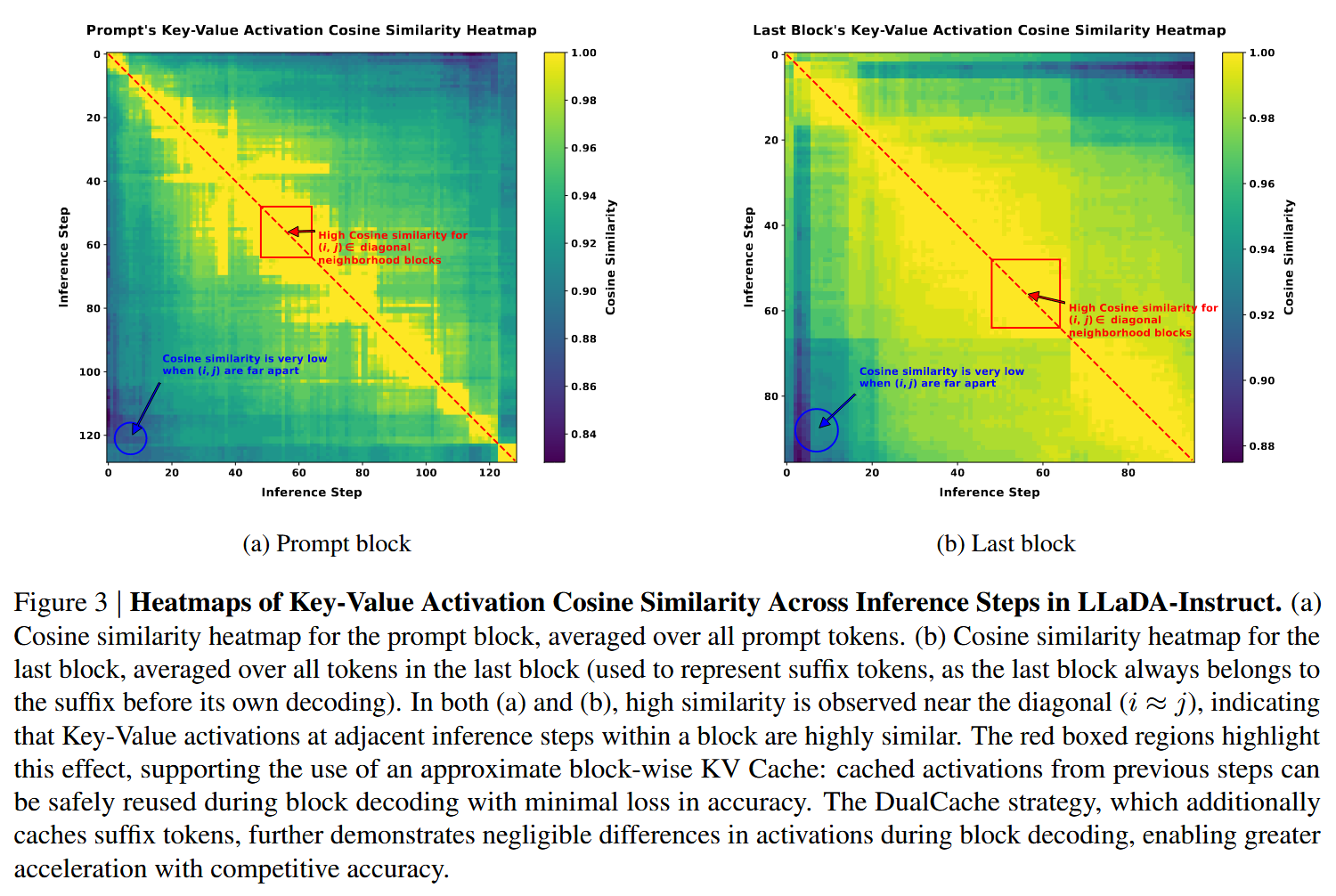
作者可视化出了不同推理步骤间 KV Cache 的相似性,作者发现相邻的推理步骤间的 KV Cache 十分接近,所以作者在 Block0 生成两个 token 后并没有立即更新 Cache,而是直接复用了 Cache 来更新剩余两个 token,待 Block0 都生成完成,才更新一次 Cache
右侧图——双向 KV Cache(DualCache)#
不仅缓存前缀标记,还缓存后缀标记,在块解码方案下,这些后缀 token 完全由【MASK】组成。DualCache 进一步提高了加速效果。图 3b 中的红色框区域进一步表明,在块解码过程中后缀键和值的差异可以忽略不计。
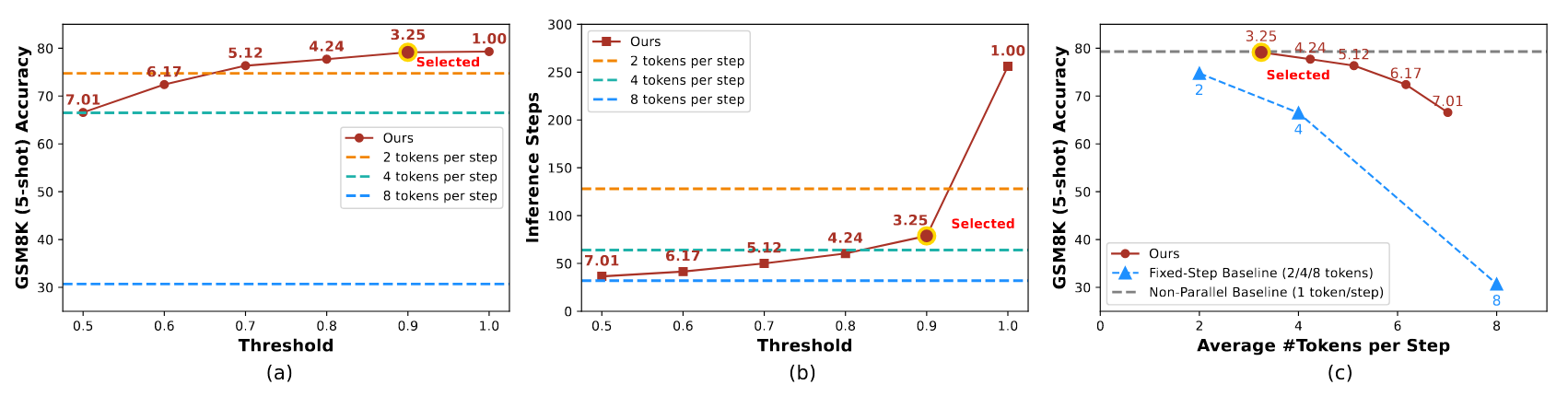
置信度感知的并行 Decoding#
在每次降噪过程中,并非激进地使用各自独立概率来生成所有被 mask 的 token,而是为每个 token 计算一个置信度分数(比如最大 softmax 概率)。
- 如果有些 token 的置信度超过阈值,则在当前降噪步骤中被 decode 改 token,其他就仍然保持 mask 状态
- 如果没有 token 的置信度超过阈值,则只 decode 最高的 token
作者通过数学证明提出上述方法可以用于并行 Decoding 而尽可能避免产生刚刚提到的问题。得出只要满足置信度分数(softmax 概率) \(\gt \frac{n}{n+1}\)(n 为一共要生成的 token 个数,也就是一个 block 中的 token 数)就可以近似避免并行带来的问题,但是阈值越低,问题避免效果越差。
于是引入一个超参数 f,只 decode \(置信度 \gt 1-\frac{f}{n+1}\)的 token

实验#
硬件:A100 80G
超参:如未另外说明,则 block_size=32,使用了 Prefix Cache,f=0.9
数据集:GSM8K、MATH、HumanEval、MBPP、MathVista(视觉数学)、MathVerse(视觉数学)
模型:LLaDA、LLaDA-1.5、Dream、LLaDA-V(视觉)
框架:lm-eval(原来还有一个专用于 lm 评估的框架)
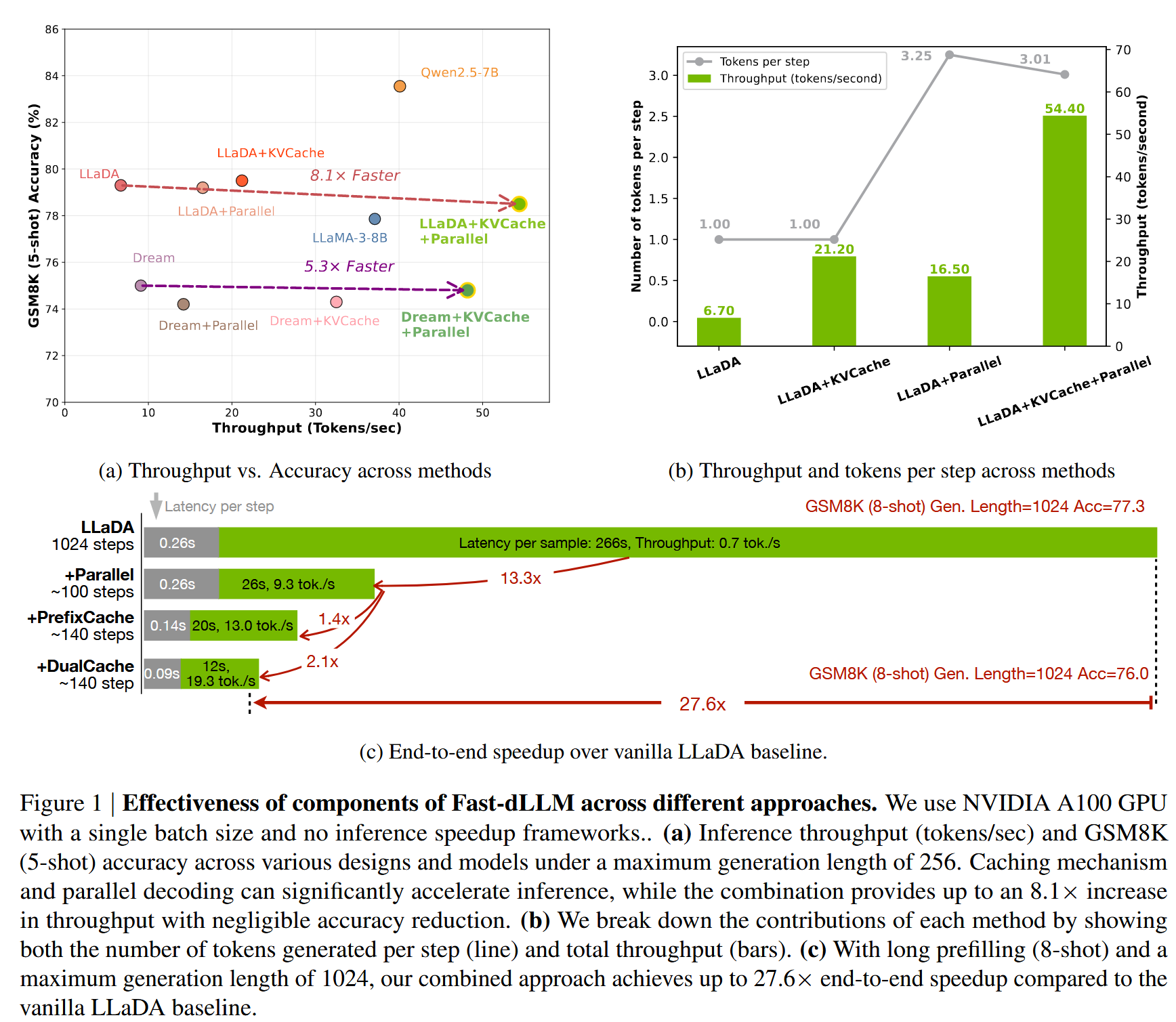
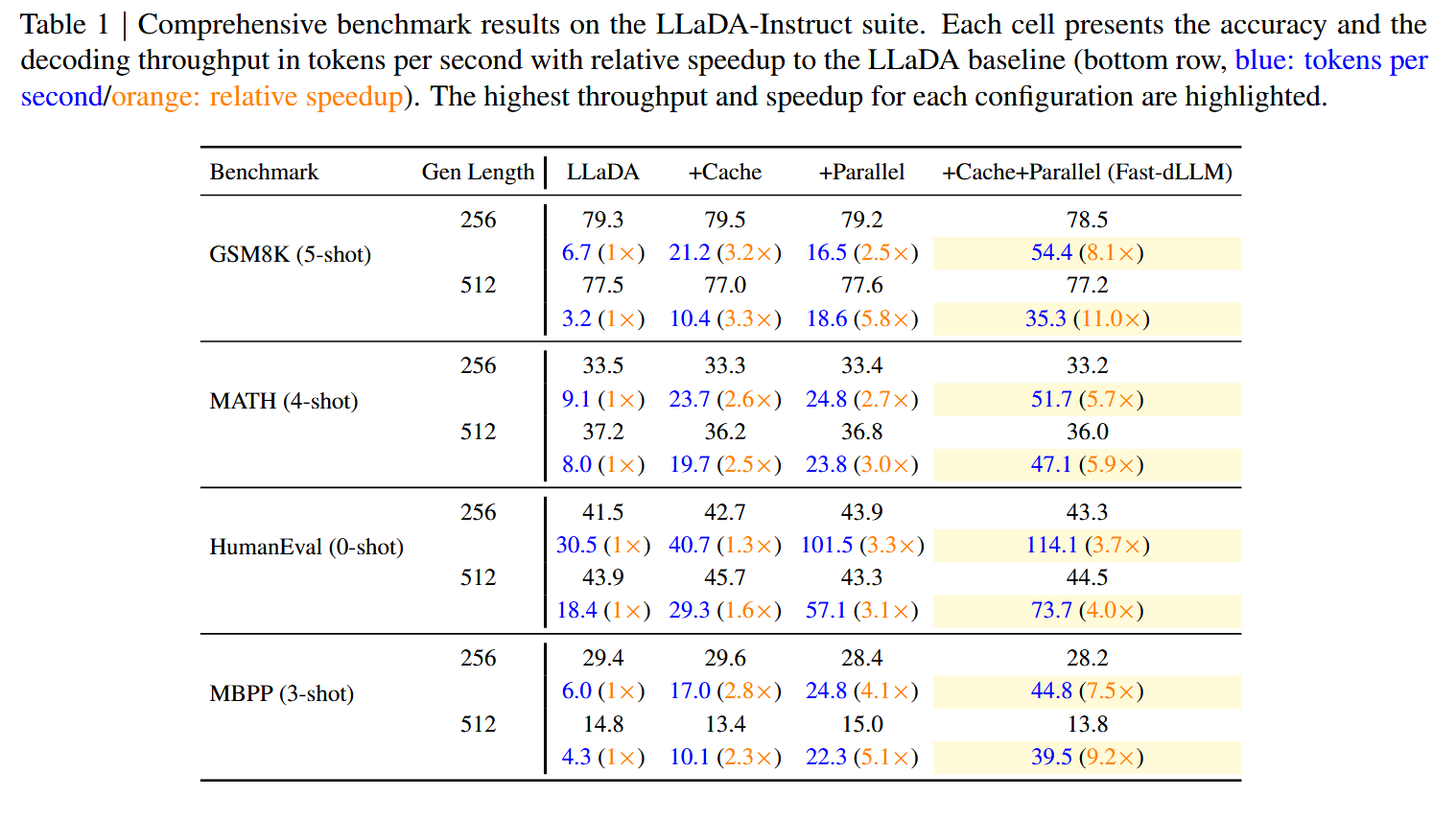
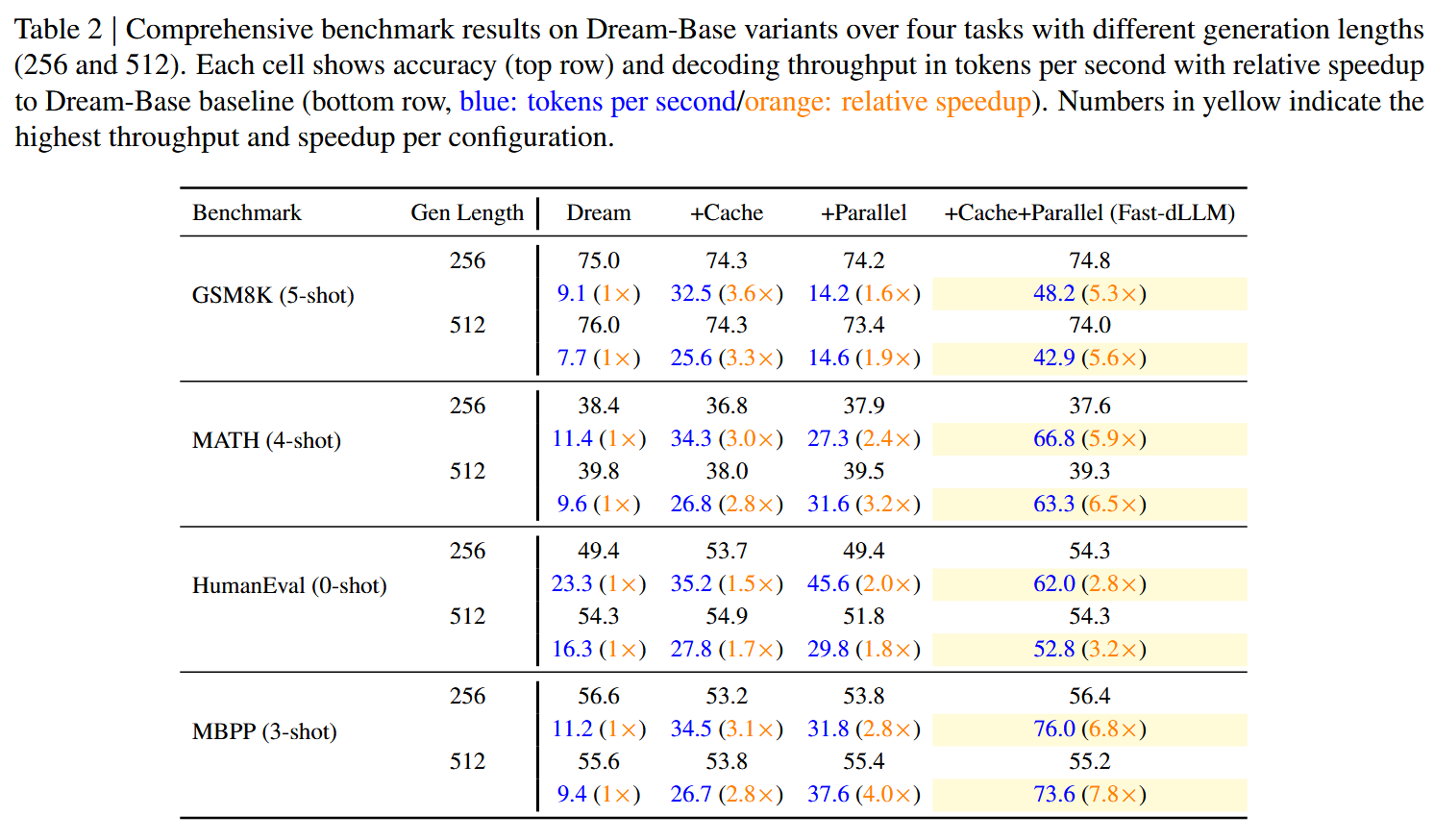
黑色为 Acc,蓝色是 token per second,红色是加速比
主实验#
LLaDA:#
Dream#
LLaDA-V#

其他实验#
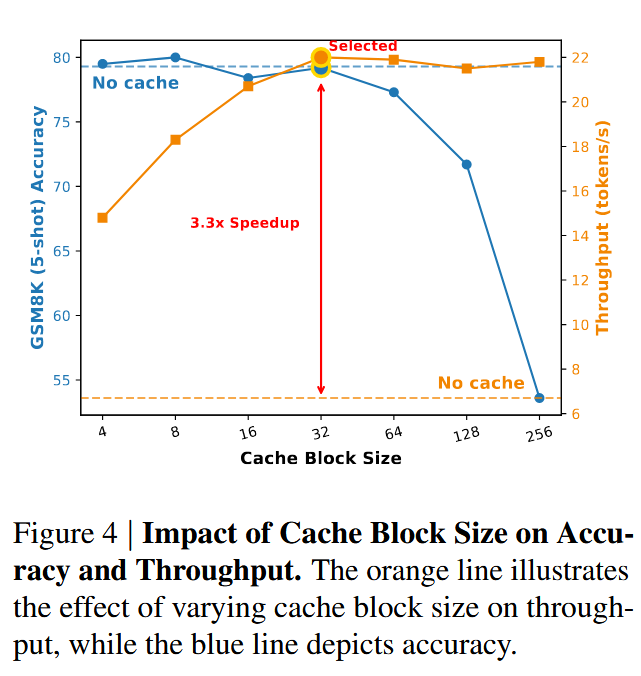
Block Size 的选择#
阈值对于 Acc、Steps 的影响#
DualCache#
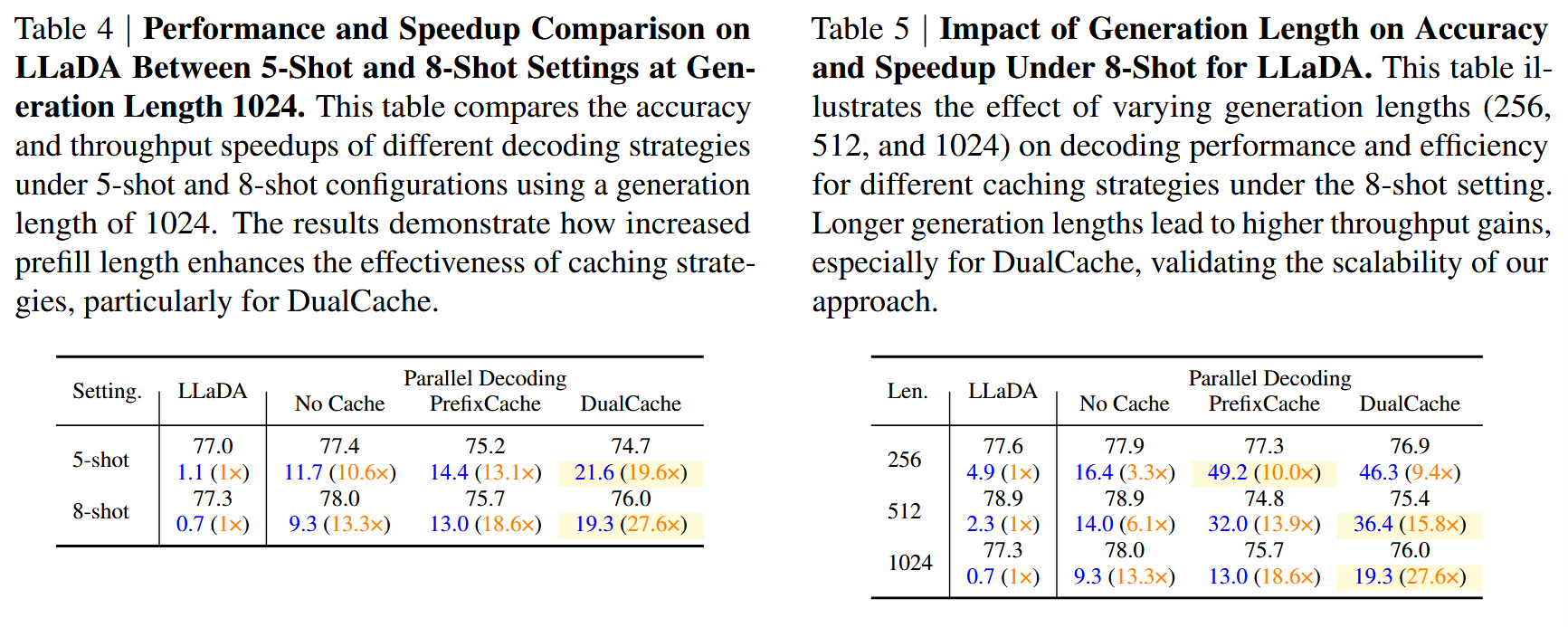
放在文章一开始结果#