HAWKEYE:大小模型协作实现精简 CoT#
Hawkeye:Efficient Reasoning with Model Collaboration
摘要#
链式思维(CoT)推理在增强大型语言模型(LLMs)的推理能力方面展现了显著的有效性。然而,其效率仍面临挑战,因为会生成过多的中间推理 tokens,这引入了语义冗余和过于详细的推理步骤。此外,计算成本和延迟是重要的问题,因为成本随着输出 tokens 的数量(包括中间步骤)增加而上升。在这项工作中,我们观察到大多数 CoT tokens 并非必要,仅保留其中一小部分便足以生成高质量的响应。受此启发,我们提出了 HAWKEYE,这是一种新颖的后训练和推理框架,在该框架中,一个大模型生成简洁的 CoT 指令,以指导一个小模型生成响应。HAWKEYE 通过强化学习量化 CoT 推理中的冗余并提取高密度信息。借助这些简洁的 CoTs,HAWKEYE 能够在显著减少 token 使用和计算成本的同时扩展响应。我们的评估表明,HAWKEYE 仅使用完整 CoTs 的 35% 即可达到相似的响应质量,同时将清晰度、连贯性和简洁性提高了约 10%。此外,HAWKEYE 在复杂数学任务上可加速端到端推理高达 3.4 倍,同时将推理成本降低多达 60%。HAWKEYE 将开源,并且相关模型不久后将可供使用。
动机#
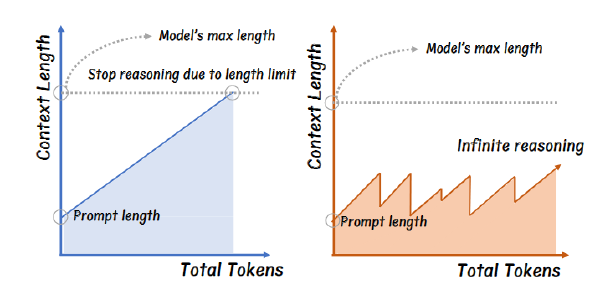
Token 太多了成本太高 ➕ 大多数推理过程的 Token 是冗余的不必要的
关于大多数推理 Token 的不必要性,作者简单举例:对于同一个问题,o1 使用了 40k token 但是 4o 只用了 4k
观察发现#
CoT 包含大量冗余信息#
重复的提示(hints)、填充短语(Well、嗯……,等)、过于细致的步骤
实验设计#
- 让大模型(GPT-4o、Claude 3.5 Sonnet、Grok 3)生成 CoT,并把答案去除仅保留推理步骤
提示词: 你是一位耐心且思维缜密的数学辅导老师。请仔细按照以下问题逐步进行推理,并使用清晰的逻辑和中间计算过程。彻底解释你的思考方式,但不要给出最终答案。 问题:¡在此插入问题¿ 让我们一步步思考。
- 让 LLM 移除上述推理步骤中的冗余信息,实现 CoT 的“压缩”
提示词: 你得到了一个用于解决问题的详细逐步推理(Chain-of-Thought)。你的任务是在保持大约 (compression ratio)% 的原始 tokens 不变的情况下修订该解释。如果需要,可以进行轻微的编辑以澄清或改善风格,但要保留整体结构、意义以及大多数措辞。不要简化或省略步骤。 关键要求是保留原始推理中最重要信息,确保核心逻辑和步骤得到保存。 原始 CoT: < 在此插入原始 Chain-of-Thought> 修订后 CoT:
压缩前后对比及不同压缩率对比



- 将压缩的 CoT 交给小模型(LLaMA3.1-1B, Qwen2.5-0.5B),让小模型基于 CoT 给出最终答案
似乎没给出小模型的 Prompt?
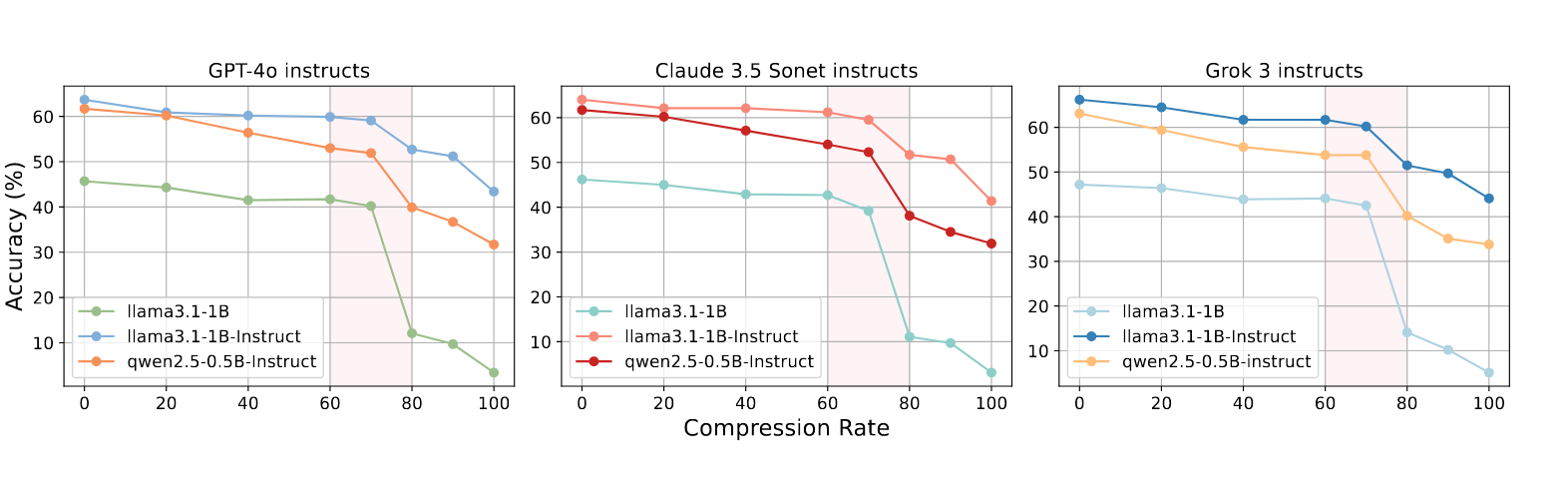
发现压缩率在 70%(仅保留 30% 推理步骤)的情况下仍能保持优异性能
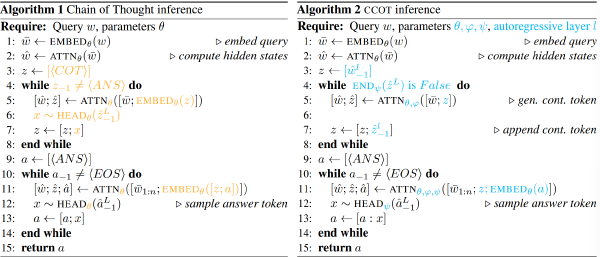
方法#
HAWKEYE:后训练#
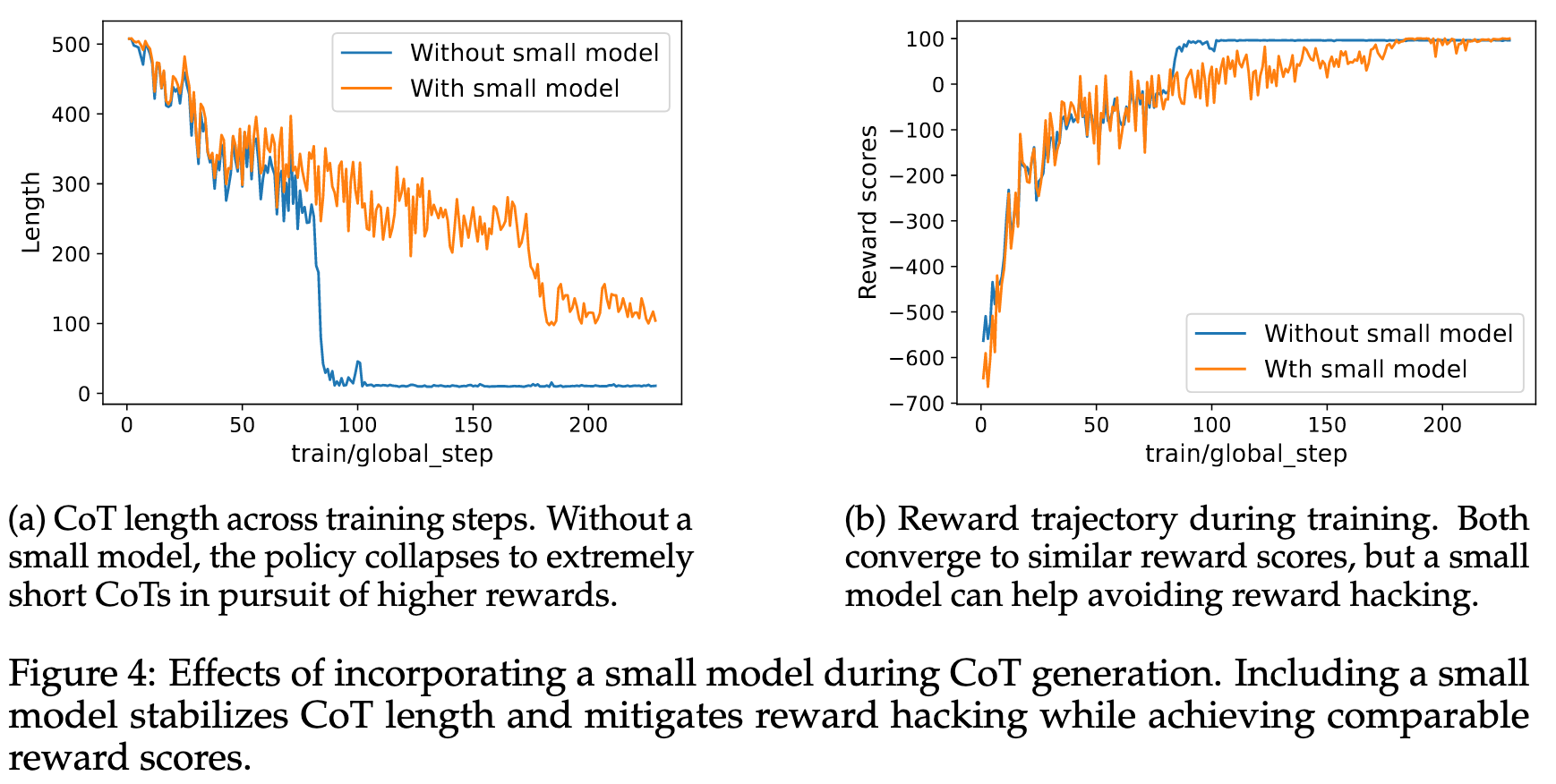
基于上述观察到的现象,使用 GRPO 训练,长度惩罚初始设置为 0.3,并对超过该阈值的 token 数量施加一个与其成比例的二次方惩罚。

上图中的 s 是一个固定的 instruction prompt
更新的是 Model A(生成 CoT 的大模型)的参数,基于 CoT 得出最终答案的 Model B(小模型)的参数不动。依据小模型给出的最终答案评分
如此设计的优势:#
- 让 Model A 生成更少的 CoT
- 防止 Model A 绕过推理过程直接给出答案来“作弊”
对于 2,如果没有小模型(Model B),大模型会直接给出答案(答案正确 + 输出短)来获取最高的分数
HAWKEYE:推理#

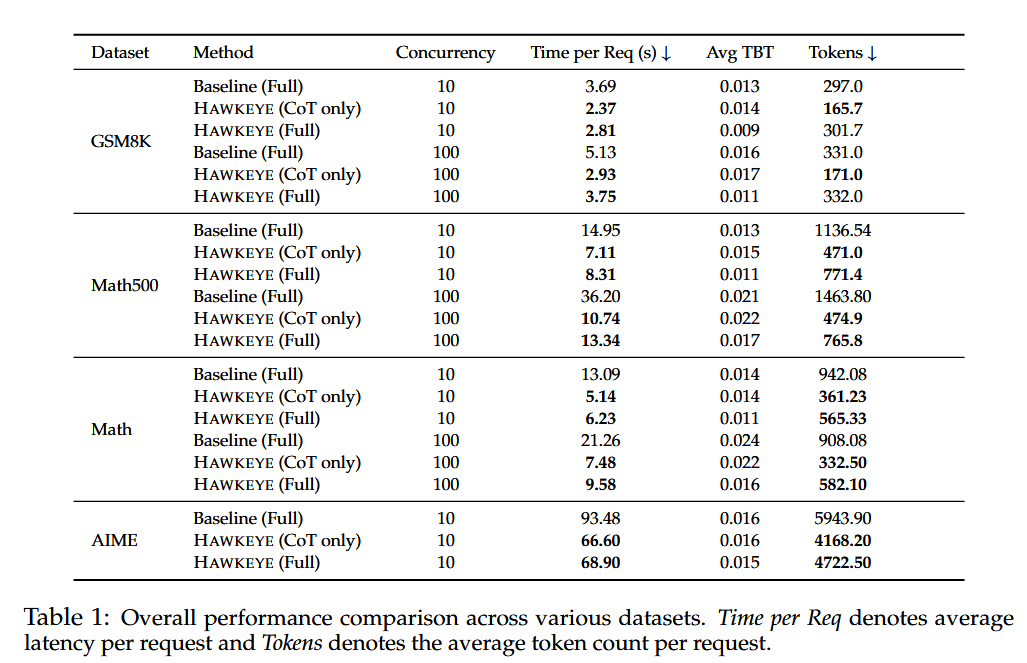
实验#
硬件:
baseline:Deepseek-R1-Distilled-Qwen-7B、Qwen2.5-0.5B
模型:Deepseek-R1-Distilled-Qwen-7B-Hawkeye + Qwen2.5-0.5B
数据集:MATH, MATH500, GSM8K, AIME
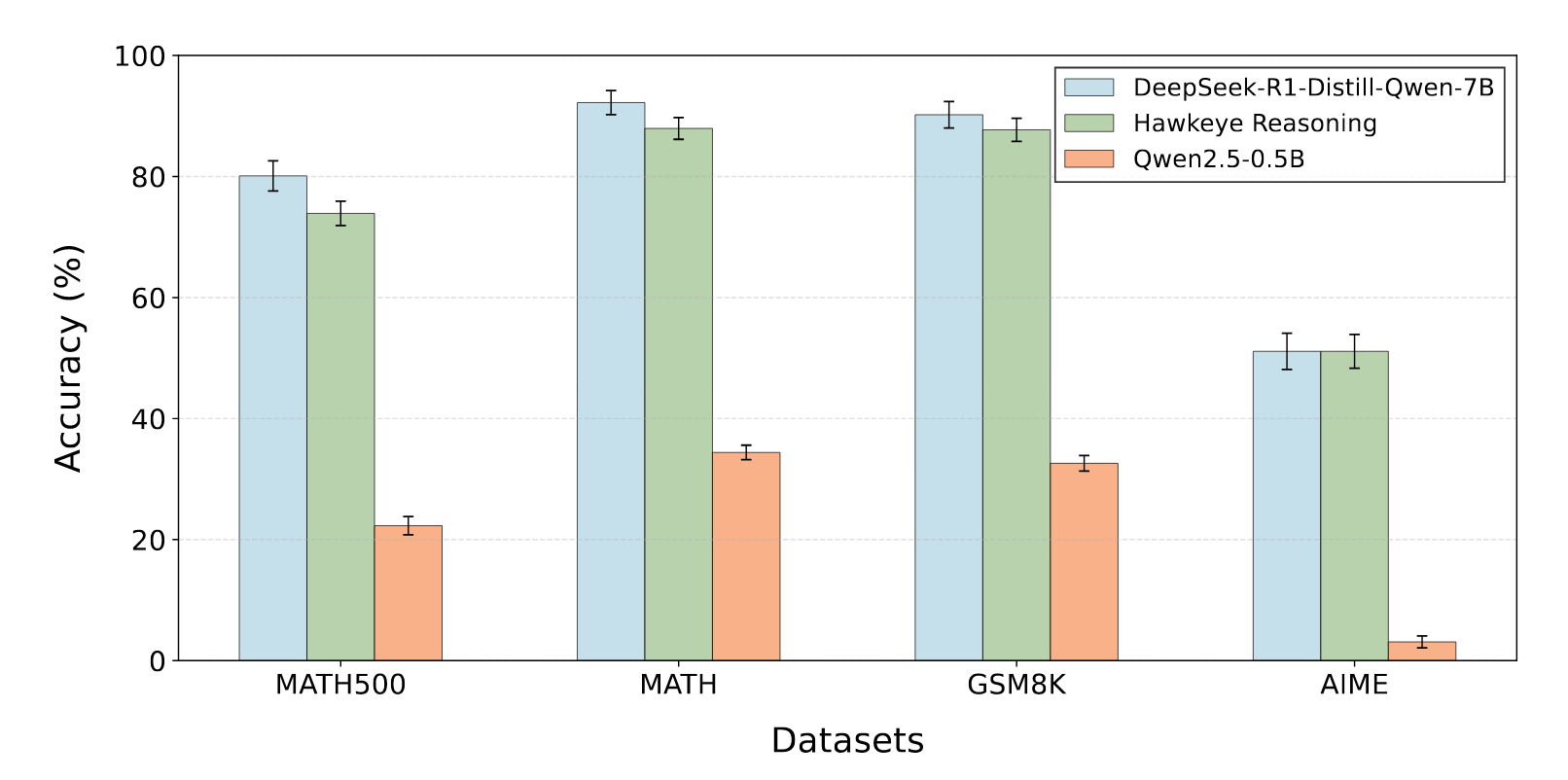
Hawkeye 稍稍下降,但是相差不大
优秀闭源大模型对于 DeepSeek 和 Hawkeye 的评分:
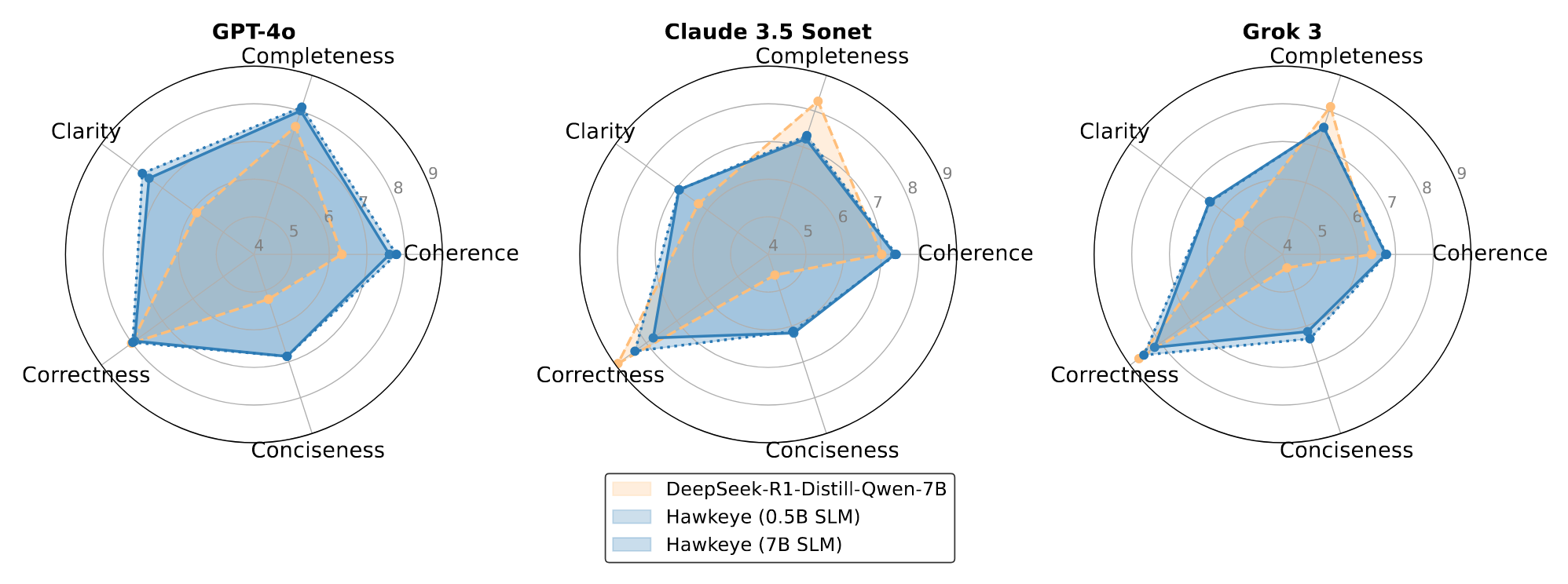
相差不大甚至略胜一筹,且发现将 SLM 从 0.5B 调整到 7B 提升不明显