INFTYTHINK:打破大型语言模型长上下文推理长度限制#
InftyThink: Breaking the Length Limits of Long-Context Reasoning in Large Language Models
摘要#
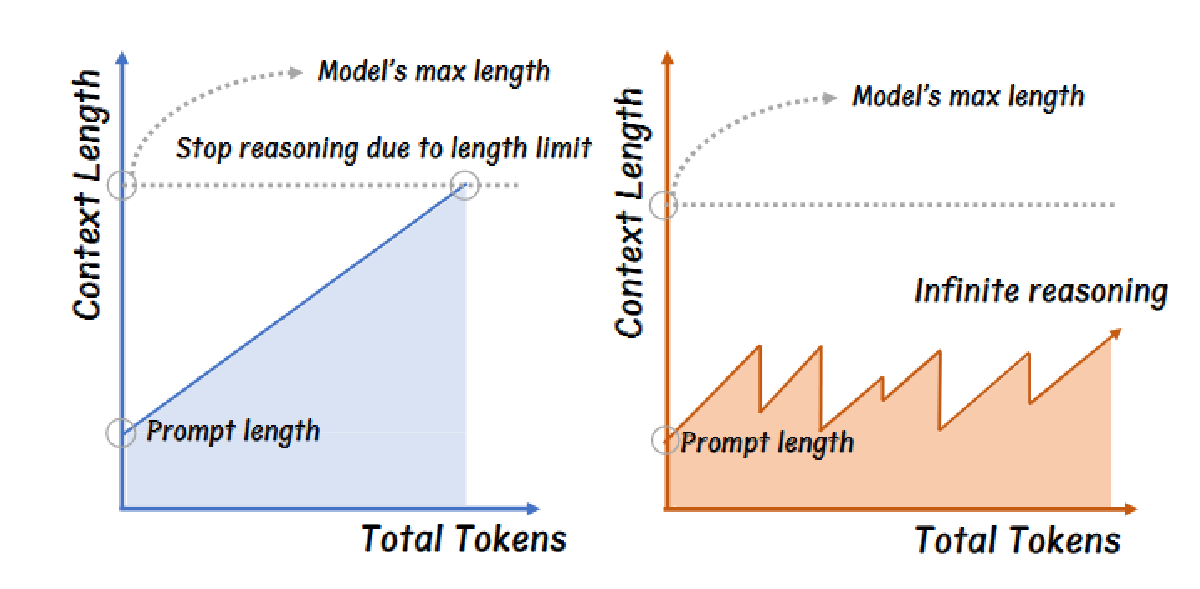
大规模语言模型的高级推理在具有挑战性的任务上性能优异,但当前占主导地位的长文本推理范式存在关键局限性:计算复杂度随序列长度平方增长,推理受最大上下文边界限制,以及超出预训练上下文窗口后的性能下降,而且现有方法主要压缩推理链而未解决根本性的规模问题。为了克服这些,我们提出了 INFTYTHINK 方法,该方法将单一推理转化为带有中间摘要的迭代过程。通过交织简短的推理片段与简洁的进度摘要,我们的方法能够在保持计算成本有界的同时实现无限推理深度。这形成了一种特有的锯齿形记忆模式,与传统的推理方法相比,显著降低了计算复杂性。此外,我们开发了一种方法,将长上下文推理数据集重构为我们的迭代格式,将 OpenR1-Math 转换为 333K 个训练实例。跨多种模型架构的实验表明,我们的方法在降低计算成本的同时提高了性能,其中 Qwen2.5-Math-7B 在 MATH500、AIME24 和 GPQA_diamond 基准测试中展示了 3-13% 的性能提升。我们的工作挑战了推理深度与计算效率之间假设之间的权衡,提供了一种无需架构修改的更具可扩展性的复杂推理方法。
Motivation#
在 CoT 的时候,LLM 往往表现出 over-thinking 的迹象,导致其生成出远远超过解决问题所需的实际 token 数量,会撞上以下三个效率瓶颈:
- 过多的 token 造成了大量的内存和处理开销
- 推理过程受到 max_len 限制,常常导致推理被截断,无法得出结论性的答案
- 大多数 llm 在 4~8k 的 context 中训练,当推理超出这个范围的时候性能会下降
现在有以下几个方法来试图解决这种局限性,但是也各有问题:
CoT-Valve 使用 Chain-compression 效果不错,但是需要在训练期间预设压缩率
王新昀:感觉这篇文章可以去读读
TokenSkip 通过评估每个 token 的重要性来减少冗余 Token,但是会影响推理性能
TokenSkip 计算出每个 Token 的重要性,然后按照压缩率将没那么重要的 token 删除,并构建数据集,格式为 问题 [EOS] 压缩率 [EOS] 压缩过的 CoT 未压缩过的答案 然后使用该数据集 LoRA 微调 Instruct Model,Input 为问题和压缩率,Output 为压缩过的 CoT 和未压缩的答案
- LightThinker 使用特殊 token 来动态压缩,但缺乏为每一步自适应确定压缩需求的能力
LightThinker 是将每个 Thought(每个句子或段落,或者林老师提到的让另一个 llm 抽取出每个 thought)压缩成固定个 token,或者是将固定个 token 压缩成更少个固定个 token(比如每 6 个 token 压缩成 2 个 token),具体方法是修改数据集中的 Y 为以下格式: S(一段 thought 或固定个 token) C(压缩成的 token) [o](引导 llm 基于 C 输出的特殊 token)…… 并且通过修改 Attention mask 来使得 llm 在压缩出 C 以后就 mask 掉 S 不去计算,节省计算量
以上这几种方法都是局限在生成一个单一、连续的推理链,贡献仅仅是让 CoT 更加紧凑,但是没有解决实际问题(只是缓解了,但是没解决),所以提出问题:
我们是否能够彻底重新构想推理过程本身,而不是在单体推理的约束下进行优化?
Contribution#
- INFTYTHINK 将单一的长篇推理转化为带有总结的迭代推理,模仿了人类工作记忆模式,将基于 Transformer 的 llm 二次计算复杂度降低
- 开发了一种技术,将现在的长 context 的数据集重构为迭代推理格式,在保持推理质量的同时,无需架构修改即可实现更高效的计算。
- 性能提高 + 计算成本降低,挑战了推理深度与效率之间公认的权衡
方法#
核心思路#
模型生成部分推理链,总结当前的思考,并在后续迭代中基于这些总结进行构建。
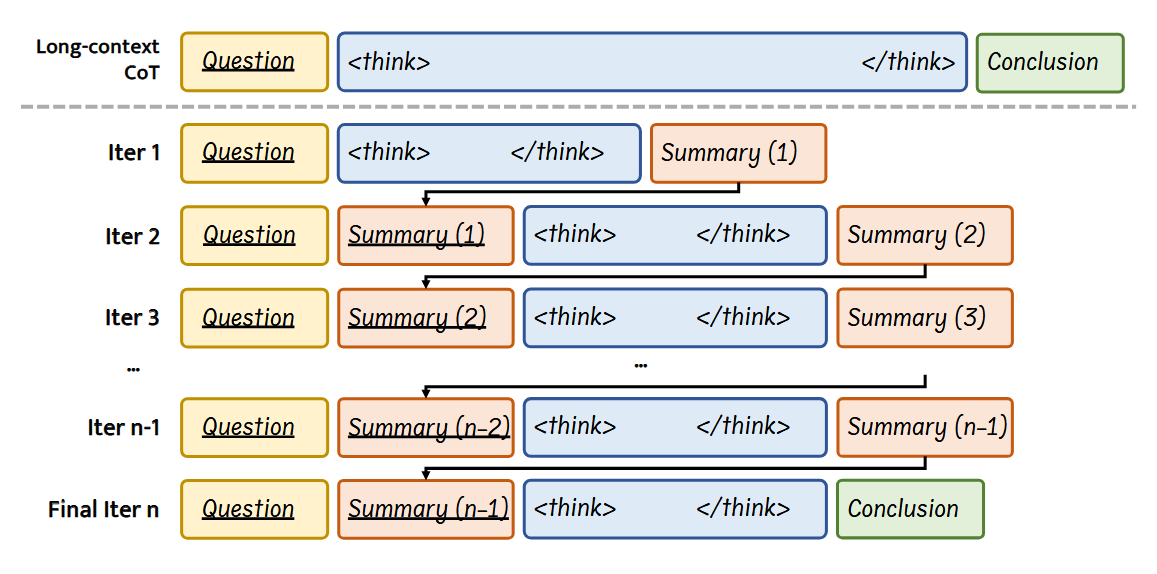
被下划线标记的片段代表作为包含在 prompt 中、将输入 model 的内容,而非下划线部分显示的是模型生成的输出。
每一次 INFTYTHINK 的迭代包括:(1)总结之前的推理进度,(2)在高效的 token 预算内生成一个专注的推理片段,以及(3)生成一个简洁的进度总结。
具体:#
具体就是如核心思路部分所讲,但是在此基础上引入 max_epochs 超参,来限制最大迭代次数。
构建数据集#
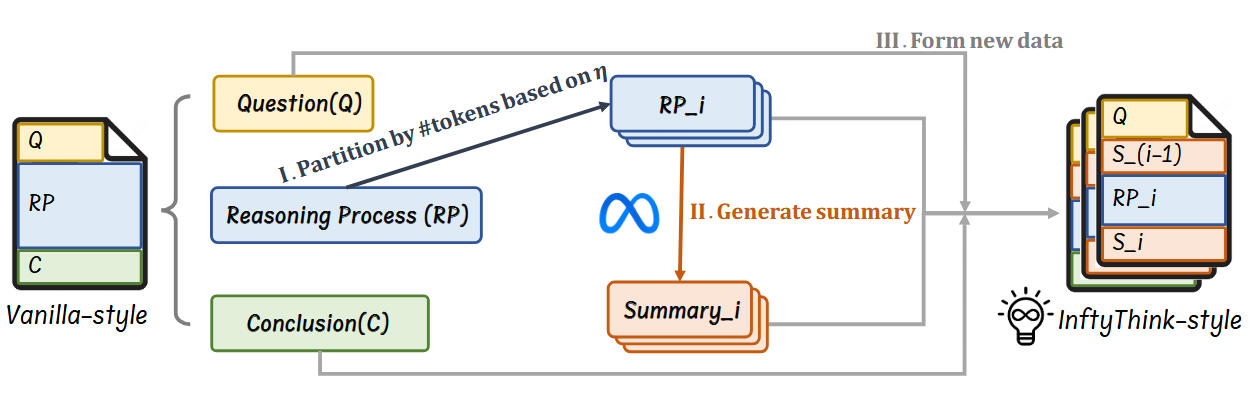
原数据集为 OpenR1-Math,构建过程如上图包含三大阶段:
- 推理分割
分段方法类似 lightthinker,在句子边界或自然段边界分,然后将这些小段按顺序拼接成一个个大段,每个大段不超过 η 个 token,η 是一个超参。

- 总结生成
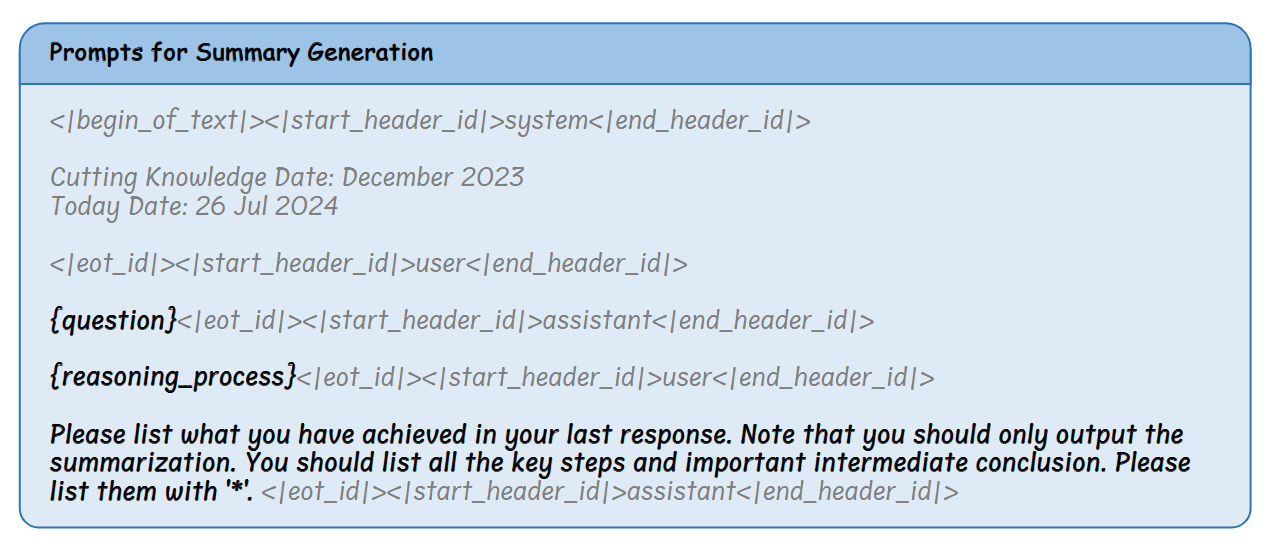
总结模型接收的不仅是当前的推理片段 RPi,还包括所有先前片段及其总结,这使得它能够生成保持推理连续性的总结。完整的提示模板:
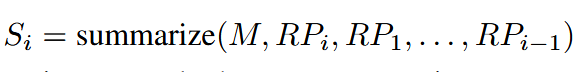
- 构建训练实例
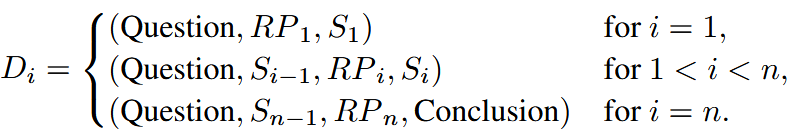
简言之,将每个原始示例转化为 n 个训练实例,其中 n 是推理片段的数量。
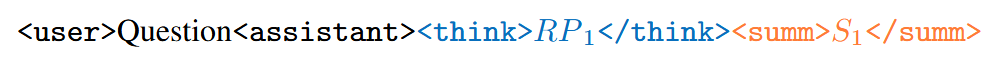

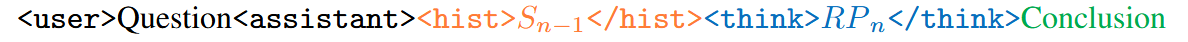
将此方法应用于 OpenR1-Math 数据集,并设置 η = 4096,我们将原始的 22 万个示例扩展为 33 万个训练实例,形成 OpenR1-Math-Inf 数据集。
实验#
基模:Qwen2.5-Math-1.5B、Qwen2.5-Math-7B、Qwen2.5-14B、Qwen2.5-32B 和 Meta-Llama-3.1-8B
操作:分别在 OpenR1-Math 和 OpenR1-Math-Inf 数据集上 Instruction-based fine-tuning。
训练超参:max_len=16384, batch_size=32, warmup=0.03, lr-scheduler=cosine to reach zero
To accelerate training, we pack all SFT samples to the maximum sequence length. Each packed sample retains its original positional embeddings, and attention values are computed independently for each instance.
在 MATH500、AIME24 和 GPQA_diamond 上评估,
评估超参:对于 baseline max_len=16384,对于 inftythink,max_epochs=50,max_len=8192
其他:每个评估案例以 0.7 的 temperature 跑 16 次,并计算平均 acc
总 Acc#
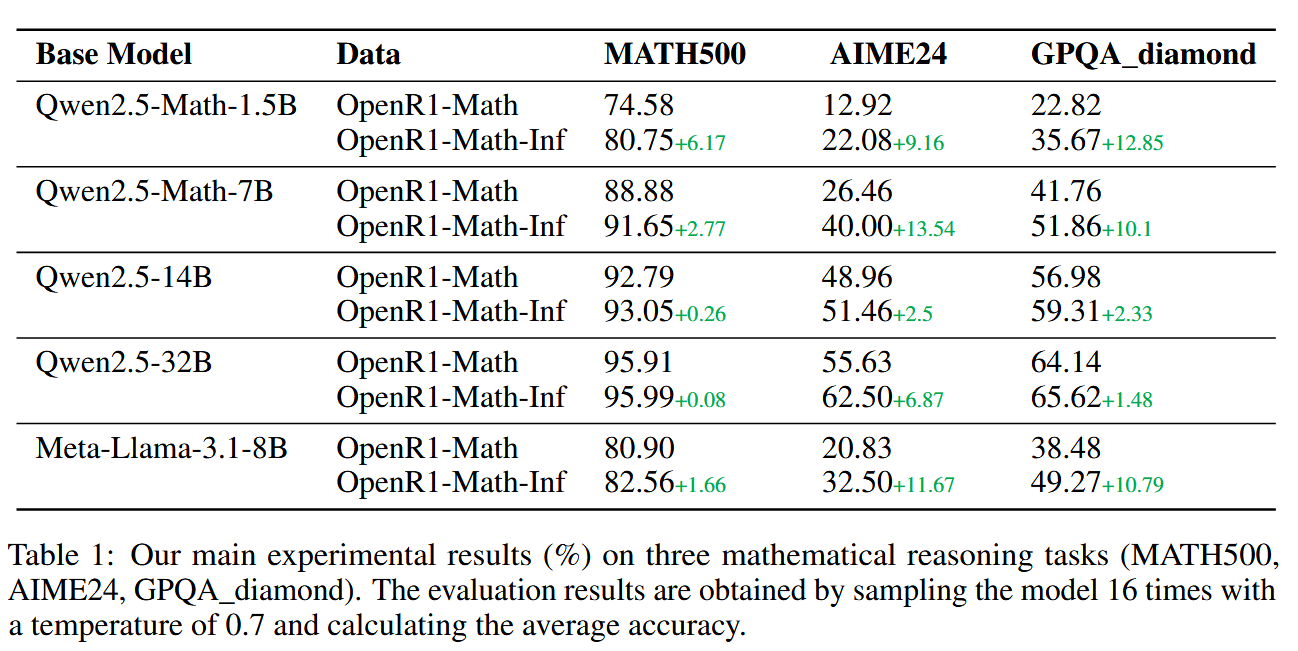
对小模型影响更为显著
对 GPQA 和 AIME24 数据集效果更明显,因为这两个数据集中问题比较复杂,通常需要超过标准上下文窗口的更长的推理链。
token 数量和 Acc 关系#
在 Qwen2.5-Math-7B 上进行
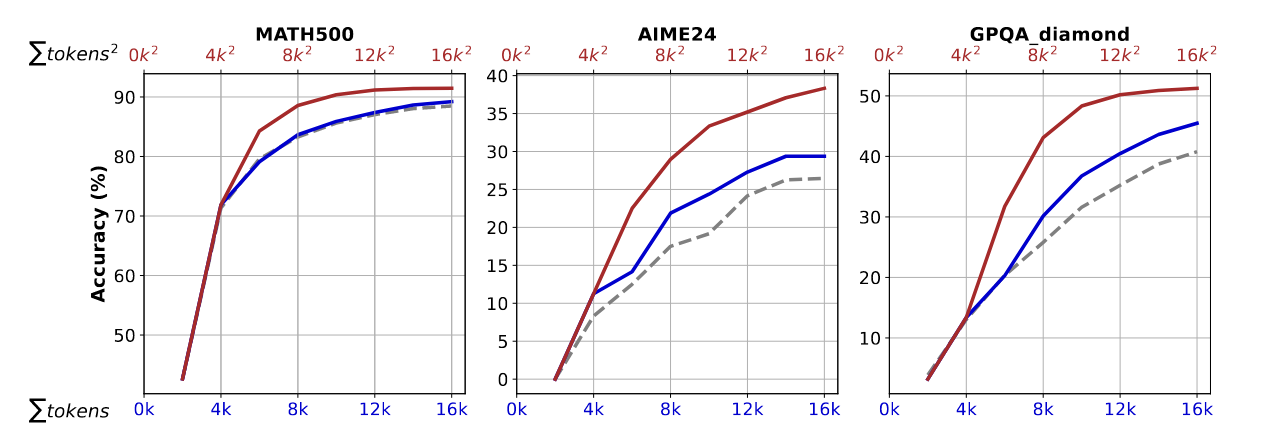
蓝线表示模型计算的总 token 数: \(\sum{token}\)
红线表示在多次推理迭代中计算的标记数的平方和: \(\sum{token^2}\)
灰线是 baseline,同时表示在两个维度上传统长上下文推理的效果。
灰蓝对比展示模型在推理一定数量的 token 时的准确性趋势,灰红对比是为了突出 token 的计算成本(n^2 的复杂度)和 acc 的关系
超参 η 的选择#
较大值会减少迭代次数,但增加每次迭代的计算成本,而较小值则能更均匀地分配计算,但可能会使推理碎片化。
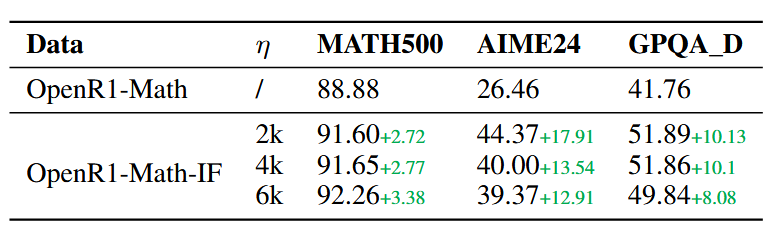
所有 η 均优于 baseline,但是没有一个通用的最优 η
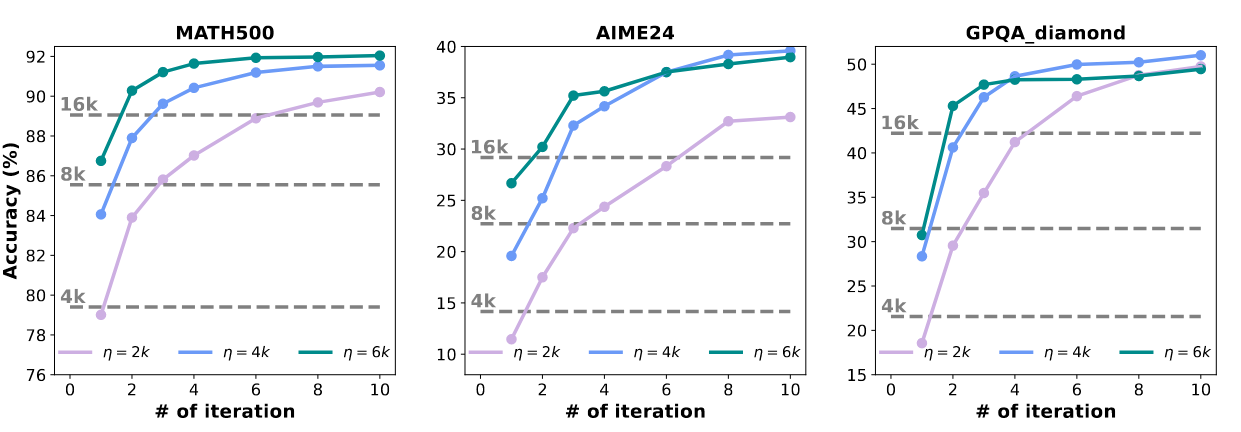
在 AIME24 这一具有挑战性的基准测试中,所有(η)设置下,从第 1 次迭代到第 10 次迭代,性能稳步提升,表明复杂问题从超越传统上下文限制的扩展推理中获益匪浅。
特定基准的缩放属性:迭代过程中改进的速度和程度因基准难度而显著不同。在 MATH500 上,性能曲线在 4-6 次迭代后趋于平坦,表明对于更简单的问题,收益递减。相比之下,AIME24 和 GPQA_diamond 在迭代到 10 次时仍显示出持续的改进,这表明问题复杂性直接影响了从额外的推理迭代中获得的益处。
即使在较小的上下文设置(η)=2k 下,INFTYTHINK 最终在所有基准测试中达到了与较大(η)值相当的性能。这在 AIME24 上尤为明显,到第 10 次迭代时,(η)=2k 配置的性能接近(η)=6k 的性能,尽管使用的推理片段大小仅为三分之一。这表明有效的摘要即使在频繁压缩的情况下也能保留关键的推理信息。
具有较大 (η) 值 (6k) 的模型在所有基准测试的早期迭代中始终优于较小分段 (2k) 的模型。然而,这种优势在后期迭代中逐渐减弱,有时甚至逆转,特别是在 GPQA_diamond 上,(η)=4k 最终超过了 (η)=6k。这表明,虽然较大的分段在初期提供了优势,但它们可能使模型陷入难以修正的推理路径,而较小的分段则允许在多次迭代中进行更灵活的探索。
与其他扩展上下文的方法(RoPE)对比#
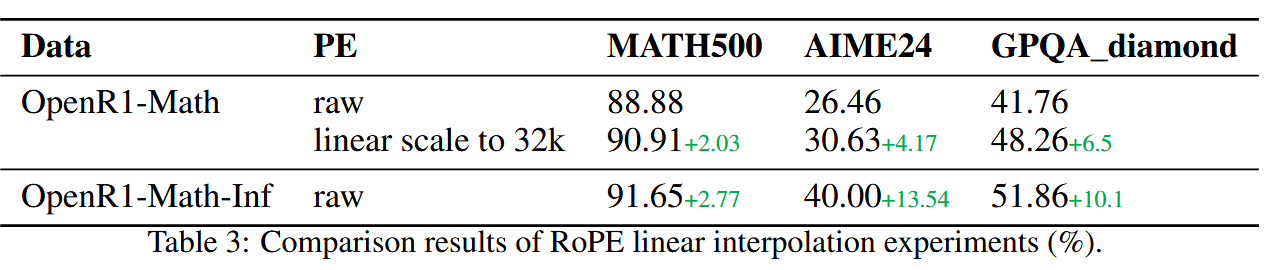
作者认为 Inftythink 与人类思考过程吻合 + 实现了自适应推理深度
但是推理质量在很大程度上依赖于模型的摘要能力 + 将推理分割成多个部分可能会打断某些问题类型中保持完整推理链的有益连贯思维流程 + 引入了额外的推理步骤增加延迟
未来方向:
- 整合强化学习技术如 GRPO 可以帮助模型更好地学习何时以及如何进行总结,可能会在迭代过程中提高信息保留率。
- 探索基于问题复杂性的可变长度推理片段,可以进一步优化计算效率与推理连贯性之间的权衡
- 将 INFTYTHINK 应用于多模态推理任务,可以将其适用性扩展到需要整合视觉、文本和数值推理的领域
- 研究如何在 INFTYTHINK 框架内并行化不同的推理路径,可以进一步加快复杂问题的解决速度。
我的思考#
感觉和 Lightthinker 有一样的缺陷,划分的 thought 不是真 thought
能不能在隐藏状态实现 Inftythink?

