LCIRC: 长文档循环压缩方法 (LLM Training Free)#
LCIRC: A Recurrent Compression Approach for Efficient Long-form Context and Query Dependent Modeling in LLMs
Accepted to NAACL 2025 Main
Check h 的 size
摘要#
虽然大型语言模型(LLMs)在生成连贯且上下文丰富的输出方面表现出色,但其高效处理长篇上下文的能力受限于固定长度的位置嵌入。此外,处理长序列的计算成本呈二次增长,这使得扩展上下文长度变得困难。为了解决这些挑战,我们提出了带有循环压缩的长篇上下文注入(LCIRC),这是一种通过循环压缩实现对超过模型长度限制的长篇序列高效处理的方法,而无需重新训练整个模型。我们进一步引入了查询依赖的上下文建模,该方法有选择性地压缩与查询相关的信息,确保模型保留最相关的上下文内容。我们的实证结果表明,查询依赖的 LCIRC(QD-LCIRC)显著提升了 LLM 处理扩展上下文的能力,使其非常适合需要全面上下文理解和查询相关性的任务。
动机#
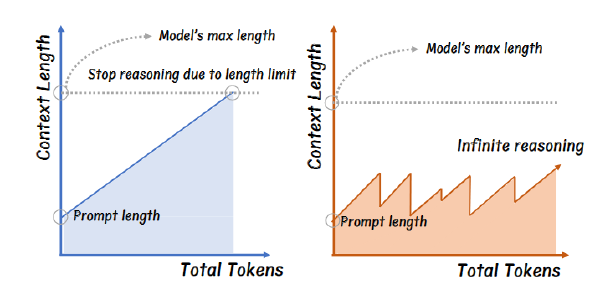
当上下文超出模型最大长上下文会导致遗忘先前信息
二次方计算复杂度高,所以单纯增加上下文是不可取的
方法#
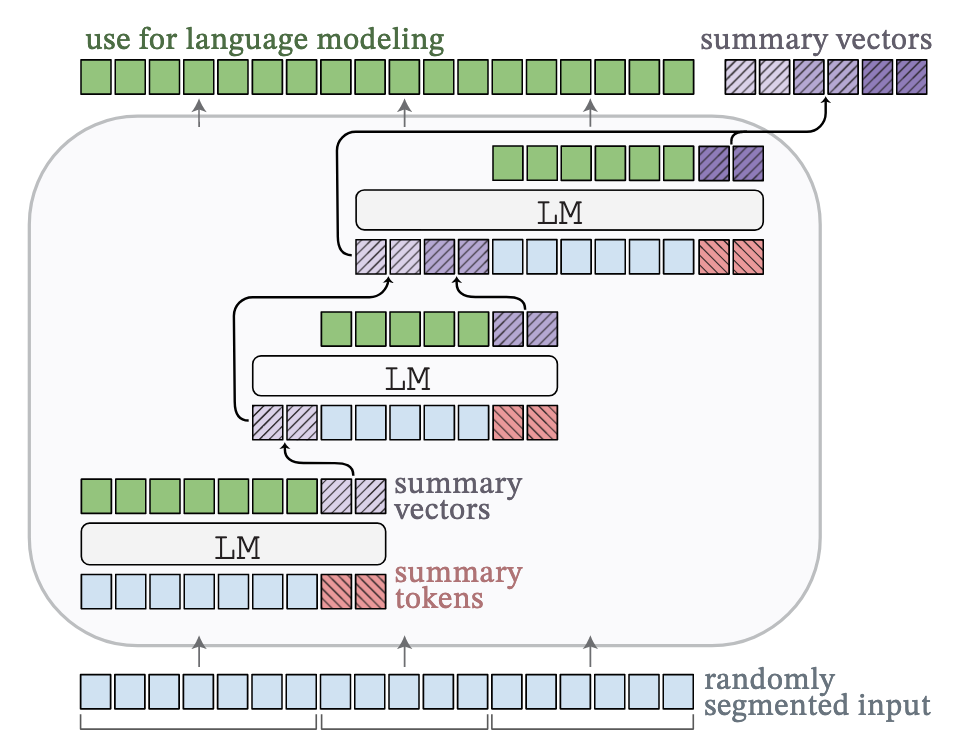
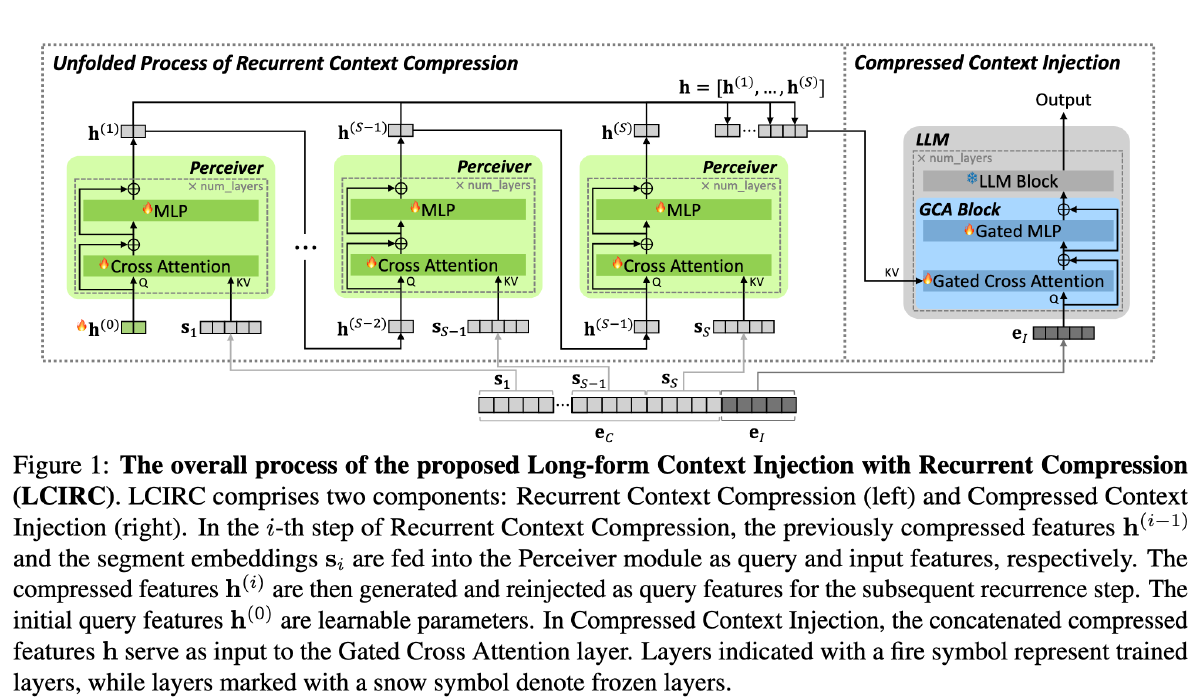
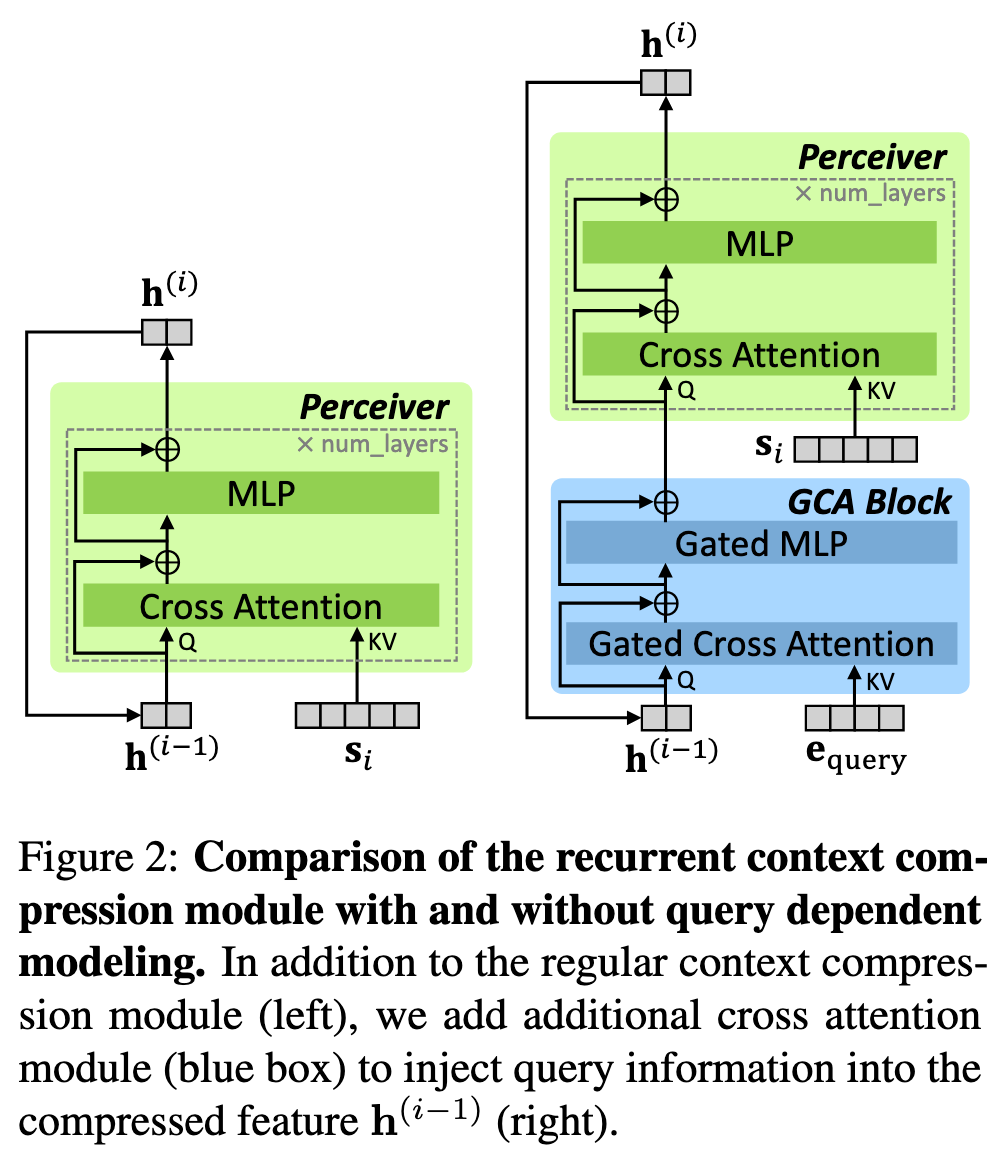
下图中带 🔥 的部分为训练的部分,带 ❄️ 的部分是冻结的部分,简单而言,除了 LLM 本身,都在训练
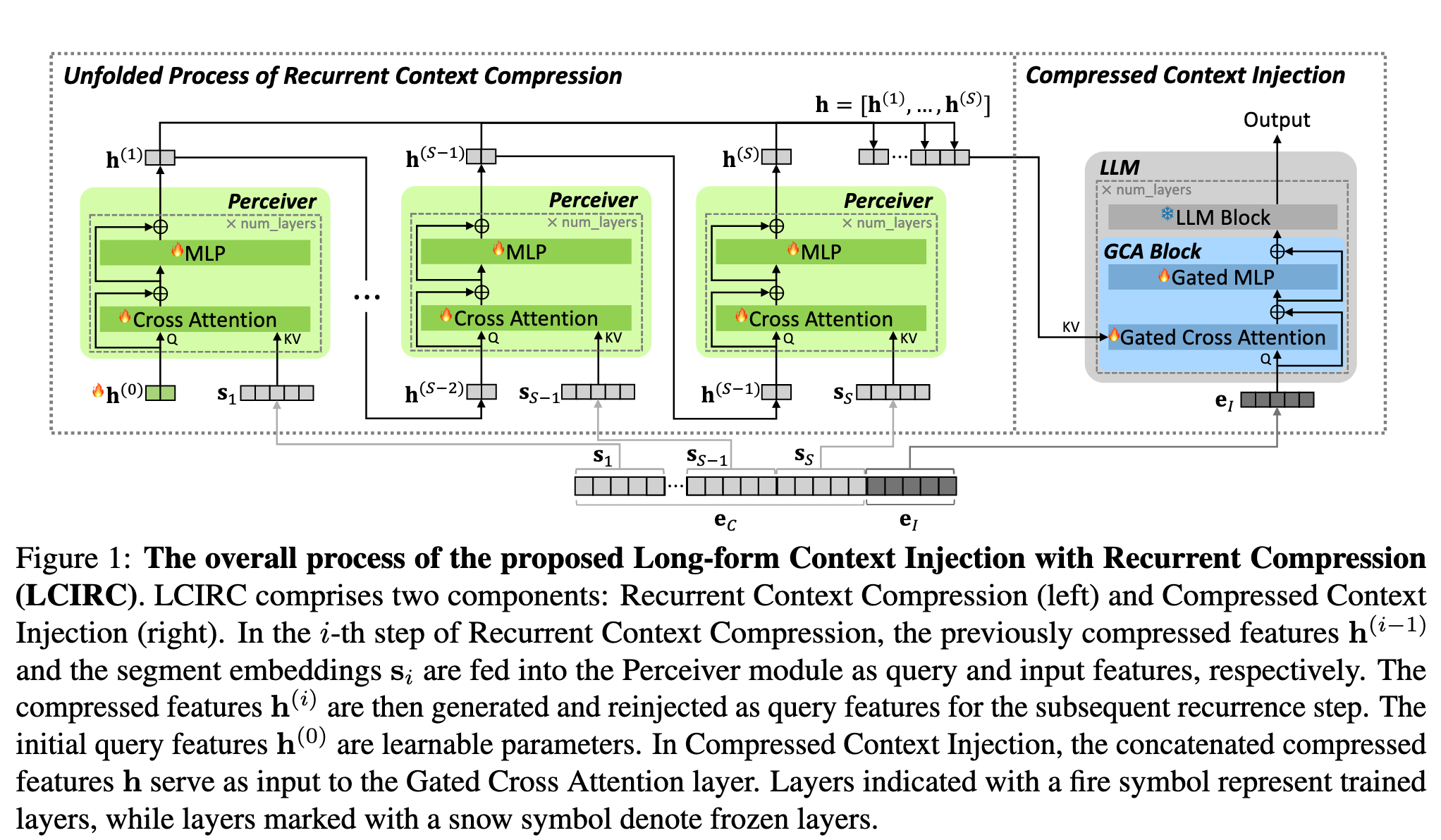
压缩器(绿色部分,Perceiver 架构):每个模块包含一个交叉注意力层,其后是两层带残差连接的 MLP,将 x 输入模型时,x 被随机截断,其中\(e_C\)是未输入模型的那一部分的 embedding。h0 是长度为 k(超参数,实验中设置为 64 和 256)的一组可学习的 query features
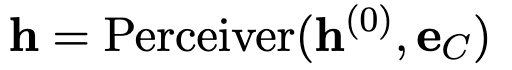
但是由于 \(e_C\)很长,一次性计算出 h 的消耗是很大的,所以采用一种循环的方式计算出 h⬇️,其中 e_C 被分割为 S 个互不相交的段
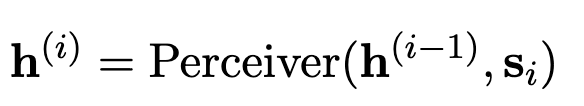
最后,将 h 们连接到一起
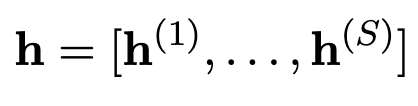
下图是大图中蓝色区域的计算:
a 和 b 是两个标量参数,并且初始化为 0,以保证不损失原有模型性能
e_l 代表最终被保留的序列在第_l_个 transformer 块上的 embeddng,CA 表示 Cross Attention
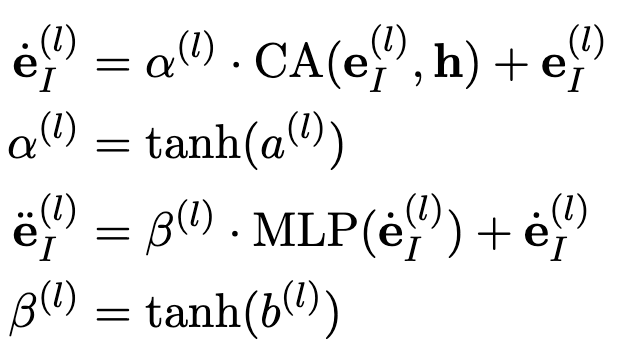
训练阶段#
仅使用超过原模型上下文的数据进行训练,冻结 LLM 模块,仅训练其他模块
推理阶段#
当且仅当上下文超过原模型的上下文限制时激活 LCIRC,否则就是一个正常的普通模型
当激活 LCIRC 时:
- 如果模型的输出的长度在上下文窗口之中——直接输出
- 如果模型的输出又超出了上下文窗口——迭代压缩之前生成的部分,比如压缩一半的最大窗口长度
改进:依赖 Query 的 Context Model#
简单来说,将上方纵览图中的绿色部分换成下图右边部分
改进 + 训练:#
使用 Random Selective BPTT 进行训练,随机选择几个 h 计算 loss(实验部分选了 8 个),这样可以在减少计算量的同时保持模型关注长上下文的能力。
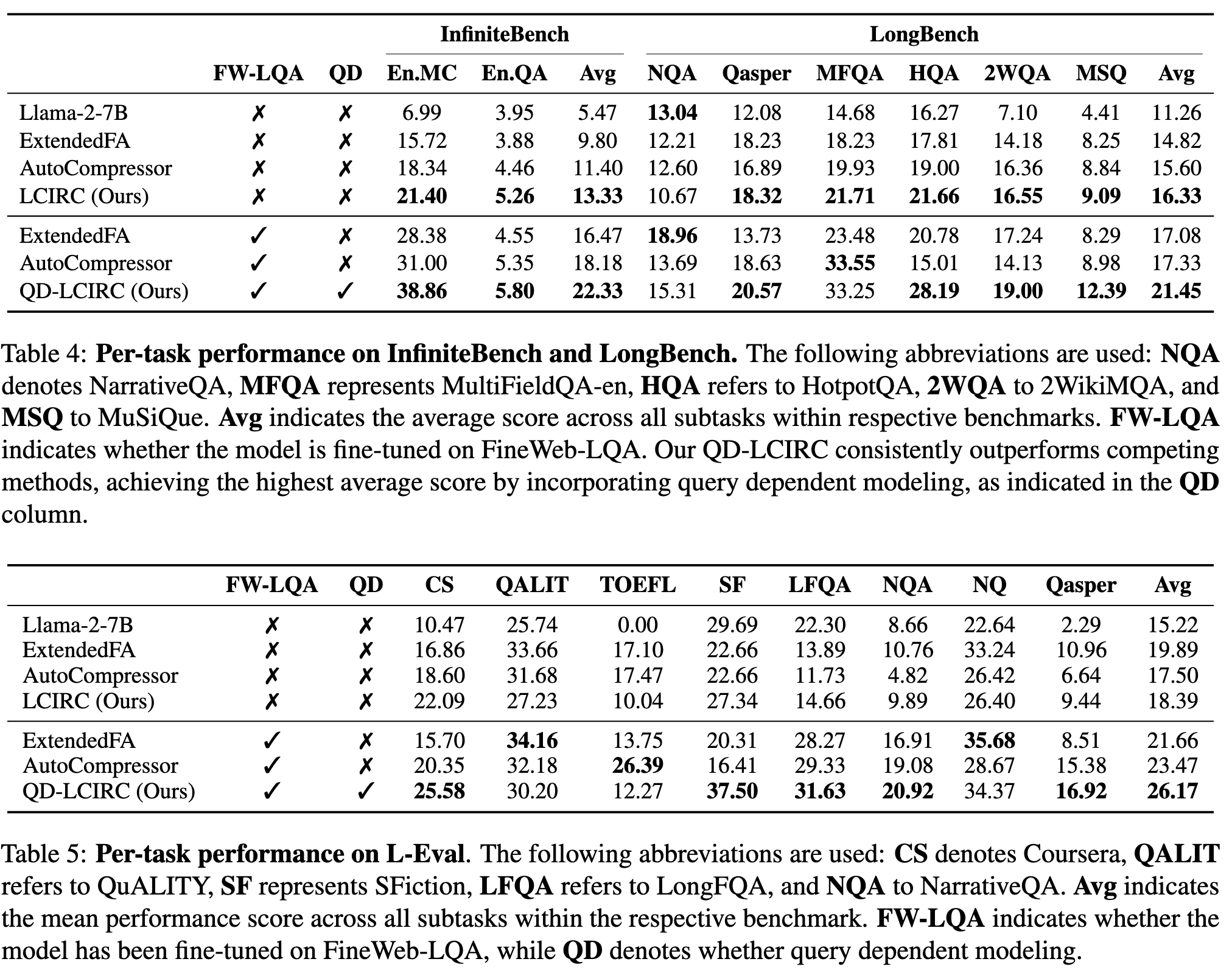
实验:#
数据集:FineWeb-Edu(筛出长度大于 4k 的数据)、FineWeb-LQA(基于 Edu 作者合成的长 QA 数据集)、InfiniteBench(Focuse on 长文本问答和长文本多选)、LongBench、L-Eval
模型:LLaMA2-7B
baseline:原模型(4k)+ 通过修改 RoPE θ 将 token 长度限制扩展到 8K 的 LLaMA2-7B(ExtendedFA,8k)+AutoCompressor(84k)(而 Ours 可以实现 815K)
所有模型均在 FineWeb-Edu 上 Finetune 过,且对于 QD-LCIRC,我们使用 LCIRC 在 FineWeb-Edu 上的预训练权重初始化模型,并在 FineWeb-LQA 上对其进行微调,以实现查询相关的建模。在 baseline 上如果超出了最长上下文则直接截断
其他#
AutoCompressor: