
LightThinker: 每个想法压缩成两个 token#
如果 lt 确实靠谱
改进:thinking 拆解(原文比较粗暴)
LightThinker: Thinking Step-by-Step Compression
摘要#
大型语言模型(LLMs)在复杂推理任务中表现出色,但它们的效率受到与生成长序列相关的大量内存和计算成本的阻碍。在本文中,我们提出了一种名为 LightThinker 的新方法,该方法使 LLMs 能够在推理过程中动态压缩中间思维。受到人类认知过程的启发,LightThinker 将冗长的思维步骤压缩为紧凑的表示形式,并丢弃原始推理链,从而显著减少存储在上下文窗口中的令牌数量。这是通过在数据构建时训练模型何时以及如何进行压缩,将隐藏状态映射到浓缩的主旨令牌,并创建专门的注意力掩码来实现的。此外,我们引入了依赖性(Dep)指标来量化压缩程度,通过测量生成过程中对历史令牌的依赖来衡量。在四个数据集和两种模型上的大量实验表明,LightThinker 减少了峰值内存使用量和推理时间,同时保持了有竞争力的准确性。我们的工作为在保持性能的前提下,提高 LLMs 在复杂推理任务中的效率提供了新的方向。
动机#
CoT、类 O1 的思考模式(试错、回溯、修正和迭代)等方式可以大幅提高复杂问题解决能力,但是代价是消耗大量 Token。由于 Transformer 架构限制,Attention 的计算复杂度为与上下文长度呈二次增长、KV-Cache 大小与上下文长度呈线性增长,如在 Qwen32B(杨等,2024)的情况下,当上下文长度达到 10^4 时,KV 缓存占用的空间与模型本身相当。因此,token 生成量的增加导致内存开销和计算成本急剧上升,严重限制了 LLMs 在长文本生成和复杂推理任务中的实际效率。

动机源自两个观察到的现象:
- llm 生成的 token 同时具备确保语言流畅和标记思路的作用(所以想砍掉确保语言流畅的功能)
- 人类思考时往往只写下关键步骤(下图黄色部分),但是其他思考过程放在脑子里面(相当于脑内推理,推理到一个关键节点是压缩成一个关键步骤,并写下)

背景(wxy 学习用)#
慢思考 Slow Thinking#
CoT、O1 的 reasoning 以及 R1 的尝试 + 反思 + 回溯 + 修正策略,但是 O1-like 的模式提升更大,这种慢思考能力可以使用 SFT 构造的数据注入模型来产生,但是输出 token 大大增加
推理挑战 Inference Challenges#
详见摘要,token 长了 Attention 计算复杂度二次方增长,Cache size 线性增长
方法#
大致过程:#
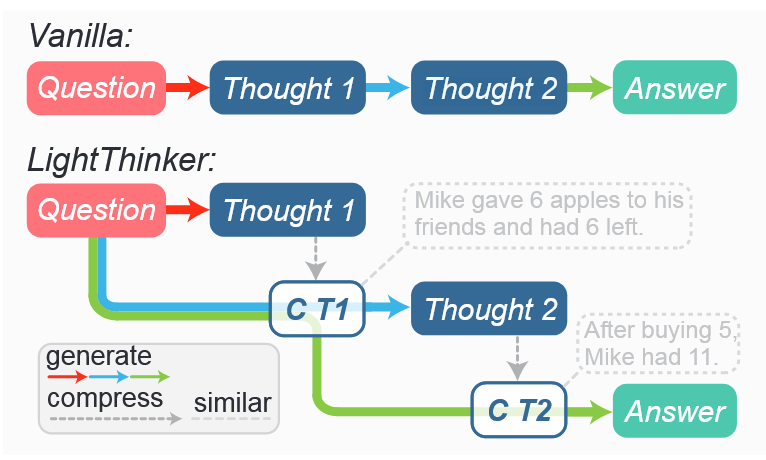
核心思路:#
训练 llm 动态压缩推理过程中的当前的想法
核心问题:#
压缩哪里?#
一种方法是固定个 token 后压缩,容易实现但是这样可能会忽略语义边界;另一个方法是每到一个思维(一个句子或一个段落)结束压缩。
如何压缩?#
一种方法是文本压缩,把当前的思考压缩成短文本或连续的向量。需要额外的编码模型,增加了计算开销。
另一种方法是隐藏状态压缩,将当前思维压缩成几个特殊 token(gist tokens)
通过构建数据集来解决压缩哪里的问题,通过基于 thought 的 attention mask 解决如何压缩的问题
思路:#
数据重构:#
对于已有的一个数据集,将 output 分成 k 个子序列(可以在 token 水平或 thought 水平上分),然后往子序列之间条件特殊 token(
在 X 不变的情况下,数据集中的输出变成了下面的样子:
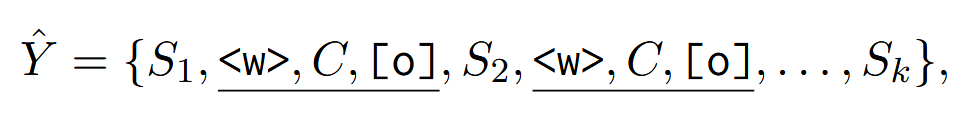
X 代表输入的 token,D 是推理的 dataset,内含 |D| 个样本,x 和 y 分别代表问题和输出。SFT 过的 D 能显著增强 LLM 的推理能力(Team, 2025; DeepSeek-AI et al., 2025)
为了简单,假设
基于思维的 Attention Mask 构造#

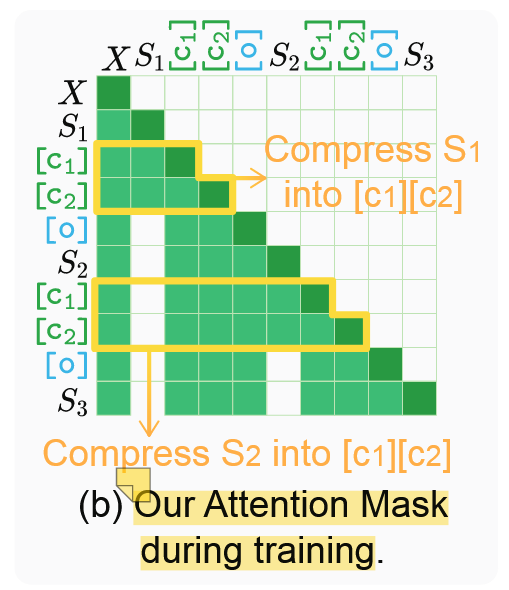
在生成过程中,[o]只能关注 X 和被压缩的 token(因为 S_i 被 mask 掉了)
训练#
最大化下面的值:θ 是 llm 的参数
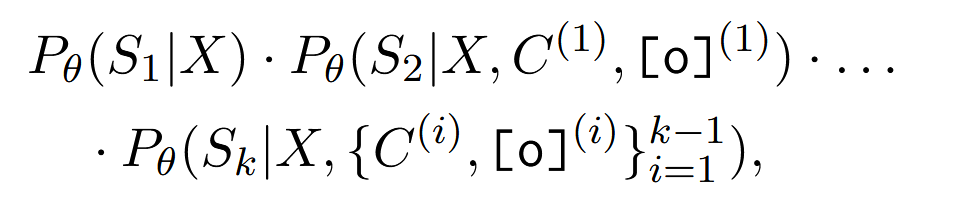
在训练过程中,LLM 不允许预测输入 X 以及特殊标记 C 和[o]。训练样本来自 D_h,我们使用注意力掩码来鼓励 LLM 学习压缩和解析压缩内容。整个训练过程仍然基于下一个标记的预测。
讨论#
什么数据被压缩了?#
感觉有点答非所问 目的不是无损压缩,而是尽可能保留重要信息
与 AnLLM 的不同#
- LightThinker 引入了[o]这个 token 用于生成后续内容,而 AnLLM 使用[c]同时代表压缩历史信息和生成后续内容
- AnLLM 只能访问压缩过程中的当前思维(S_i)。而 LightThinker 允许访问 X、历史压缩内容、以及压缩过程中的当前思维,从而增强了上下文理解。消融实验表明,这些设计显著提高了性能。
实验#
5 个 baseline:在 Bespoke-Stratos-17k 数据集上全量微调过的 Qwen2.5-7B 和 Llama3.1-8B(Vanilla);使用 H2O(training-free 方法)加速 Vanilla;基于特定策略保留重要 KV-Cache 的 SepLLM 加速 Vanilla;AnLLM;CoT+instruction Model;CoT+R1-Distill。
在 GSM8K、MMLU、GPQA、BBH 这些数据集上随机取样一些数据进行评估,评估有效性(Acc)和效率(Time、Peek——推理过程中上下文中的最大标记数、Dep——生成的每个标记对前一个标记的依赖总和)
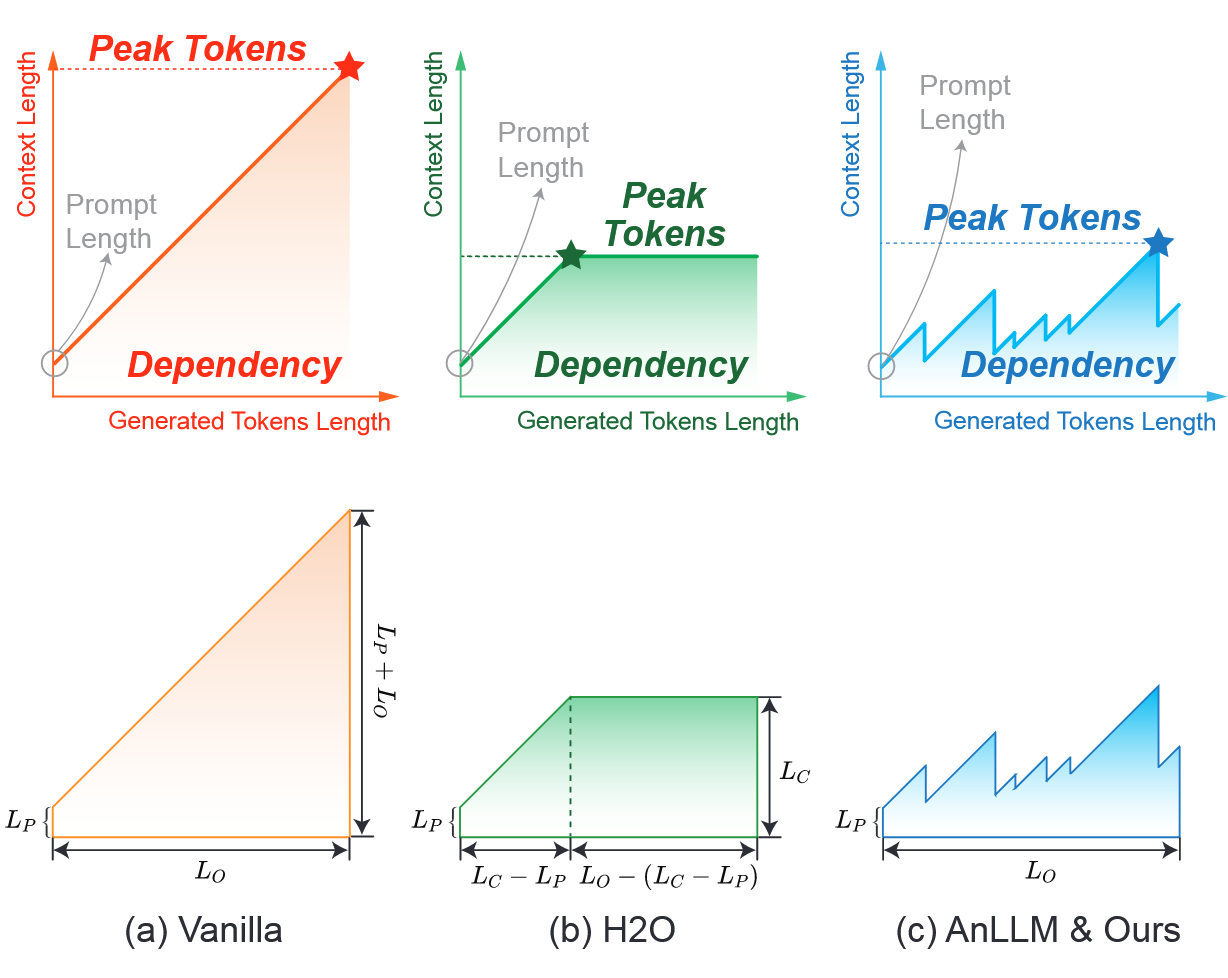
设计了两个分割 Y 的方法(详见数据重构)
- token 水平:每 6 个 token 压缩成 2 个 token(还是固定数量的压缩,能不能改成动态,比如训一个 bert 或者简单点 gru 判断当前是否可以压缩了等等)
- thought 水平:每个段落压缩一次(以\n\n 分割)。对于 Qwen,压缩成 9 个 token;对于 LLama,压缩成 7 个(能不能考虑考虑压缩成动态个 token)。decoder 使用最大 output 为 10k 个 token 的贪婪 decode
有效性#
最优,次优
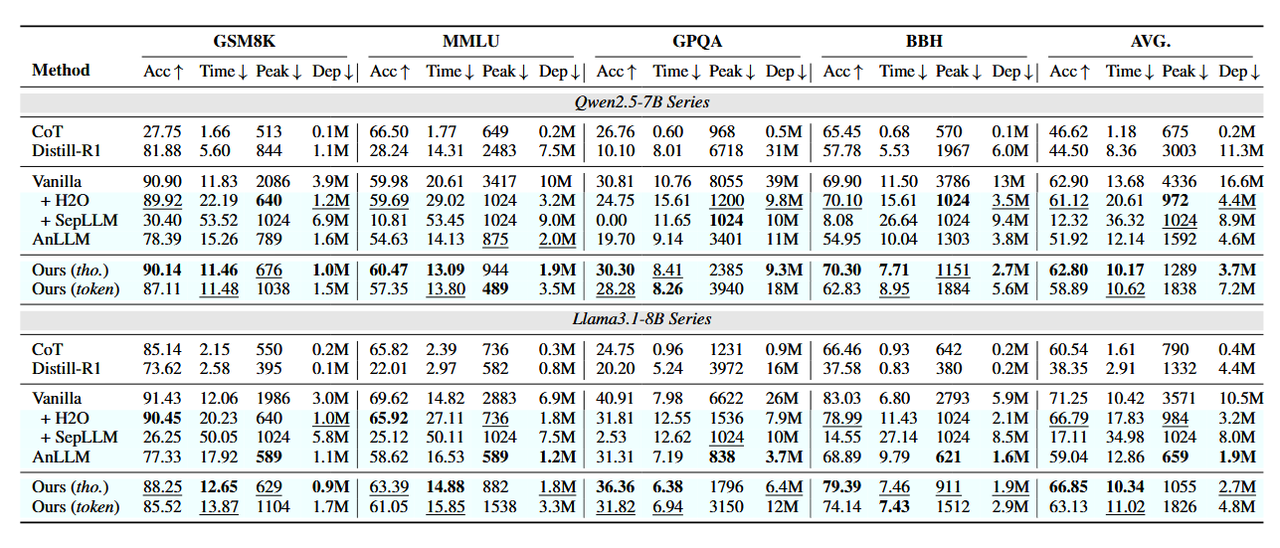
token 水平的 Acc 相比较于 Vanilla 都降了
效率#
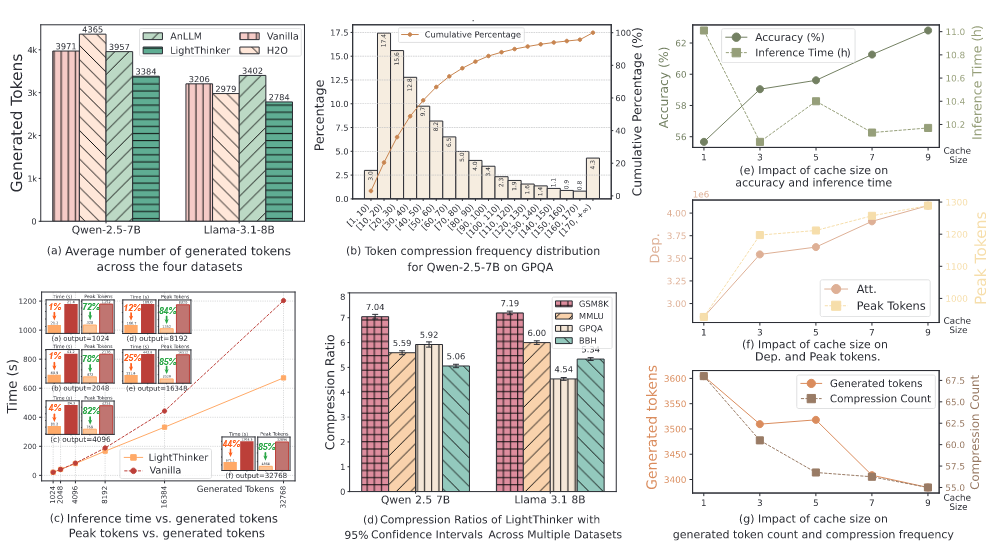
当前压缩方法对数字并不敏感**(也是可以考虑的一个点)**
这是 Solution 中的错误,最开始是 8000,但是到后面变成了 4000

Limitation#
- 实验采用的是全量微调,未尝试 LoRA 或 QLoRA+LightThinker 的组合
- LLama 系上显著性能下降
- [c]的数量是固定的,不确定某个固定数量的[c]的泛化能力
- 分段方法设计过于简单