LLM 在连续 Latent 空间中推理#
Training Large Language Models to Reason in a Continuous Latent Space
摘要#
大型语言模型(LLMs)受限于“语言空间”,通常通过思维链(CoT)来表达推理过程以解决复杂的推理问题。然而,我们认为语言空间并不总是最优的推理选择。例如,大多数 token 主要用于文本连贯性而非推理,而一些关键词元需要复杂的规划并对 LLMs 构成巨大挑战。为了探索 LLMs 在不受限潜在空间中的推理潜力,而不是局限于自然语言,我们引入了一种新的范式——椰子(Chain of Continuous Thought,Coconut)。**我们利用 LLM 的最后一个 作为推理状态的表示(称为“连续思维”)。我们将其直接作为下一个 token 输入 llm。**实验表明,椰子能够在多个推理任务中有效增强 LLM 的表现。这种新颖的潜在推理范式导致了高级推理模式的涌现:连续思维能够编码多个替代的下一步推理步骤,使模型能够在推理过程中进行广度优先搜索(BFS),而非像思维链那样过早地锁定单一确定路径。在某些需要大量回溯的逻辑推理任务中,椰子的表现优于思维链,并且在推理过程中使用的思考 token 更少。这些发现展示了潜在推理的潜力,并为未来研究提供了宝贵的见解。
动机#
CoT 中大多数 token 仅仅保持行文流畅,对于实际推理过程没啥作用。但是 LLM 为预测每个 token 分配了几乎相同的算力。理想的情况是能够在没有任何语言约束的情况下自由推理,仅在必要时将其发现转化为语言。
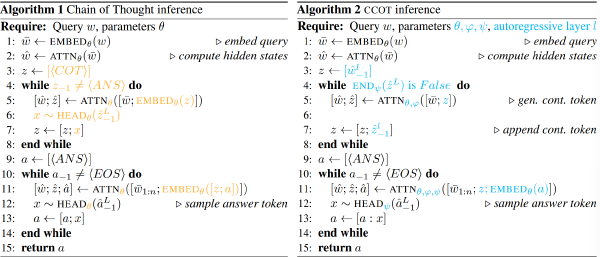
方法#
核心思路#
训练阶段#
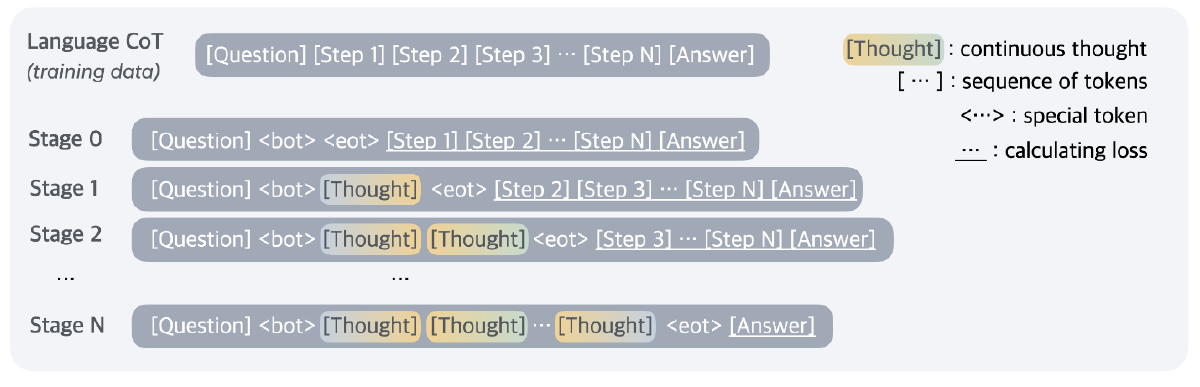
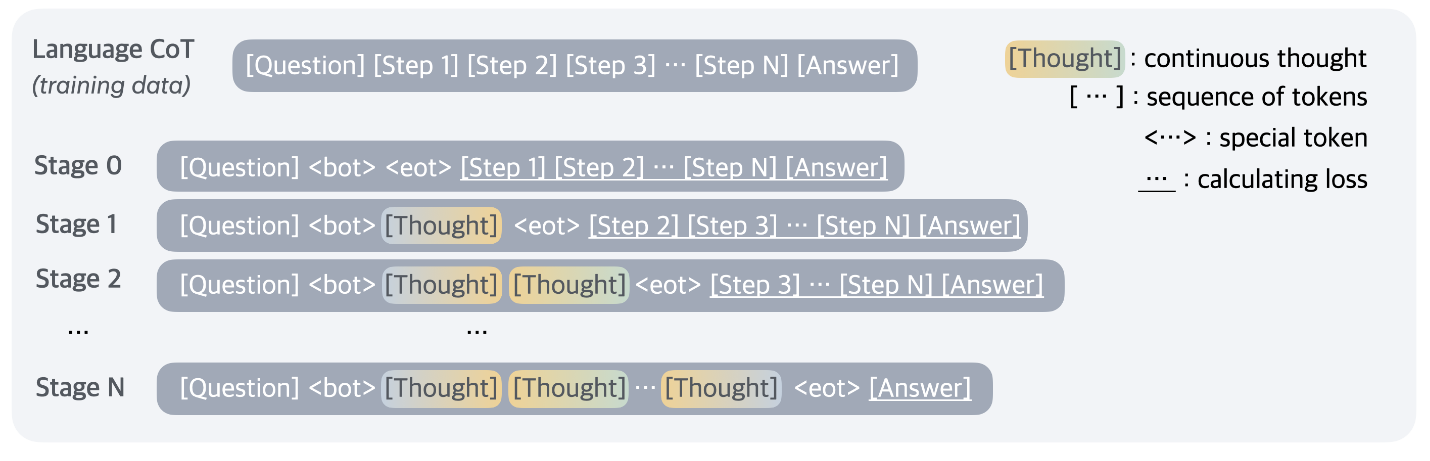
训练分为多个阶段:
初始阶段(Stage 0):在常规 CoT 上训练
第 k 阶段(Stage k):CoT 中前 k 个推理步骤的文本替换成 k * c 个连续思维(thought token),其中 c 是一个超参数,表明每个 step 替换成多少个 token
训练过程中舍弃了 Question 和 thought 的损失
推理阶段#
将最后一个隐藏状态作为下一个输入的 embedding
关于什么时候结束 thought 作者提出两种方案,一种是在 thought 上训练一个二分类器,另一种是将 thought 填充到固定长度。作者发现两种方式的表现都很不错,为了简化实验后续采用第二种方式
实验#
主实验#
模型:GPT-2
任务:数学推理、逻辑推理
数学推理#
数据集:在 GSM8k 合成的数据(自带 step)
超参数:设置 c=2,也就是每个 step 被抽象为 2 个 thought;在 Stage 3 后面添加一个 Stage 3+1,移除了后续所有的语言推理链,thought 和 Stage 3 完全相同
逻辑推理#
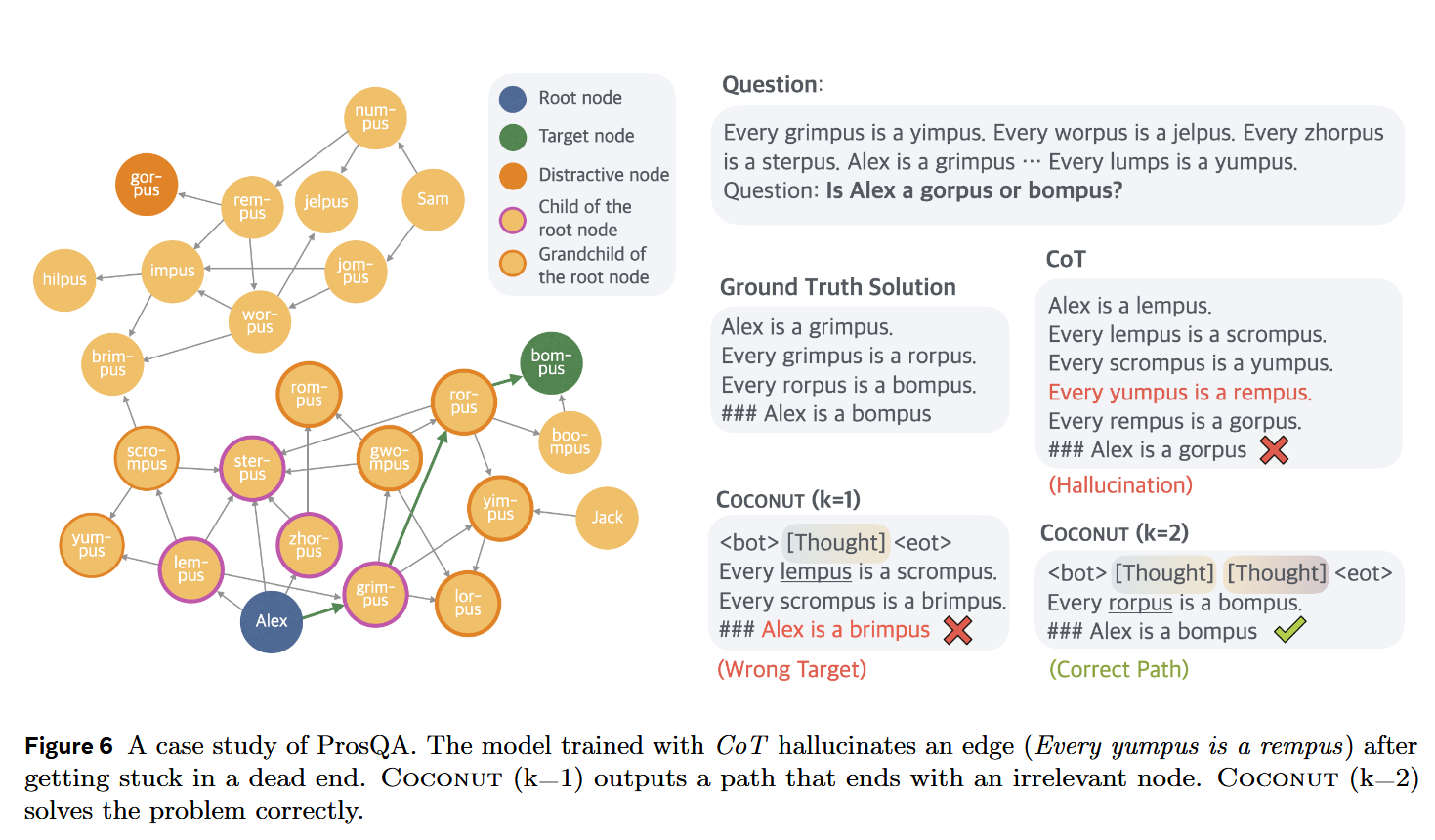
数据集:ProsQA(Proof with Search Question-Answering) 和 ProntoQA
我们使用 5-hop ProntoQA(Saparov 和 He,2022)问题,并采用虚构的概念名称。对于每个问题,随机生成一个树状结构的本体,并以自然语言描述为一组已知条件。模型被要求根据这些条件判断给定陈述是否正确。这作为更高级推理任务(如自动化定理证明,Chen 等人,2023;DeepMind,2024)的一种简化模拟。
超参数:设置 c=1,也就是每个 step 被抽象为 1 个 thought;一共 6 个 Stage,最后一阶段没有可读的 CoT,都是 thought
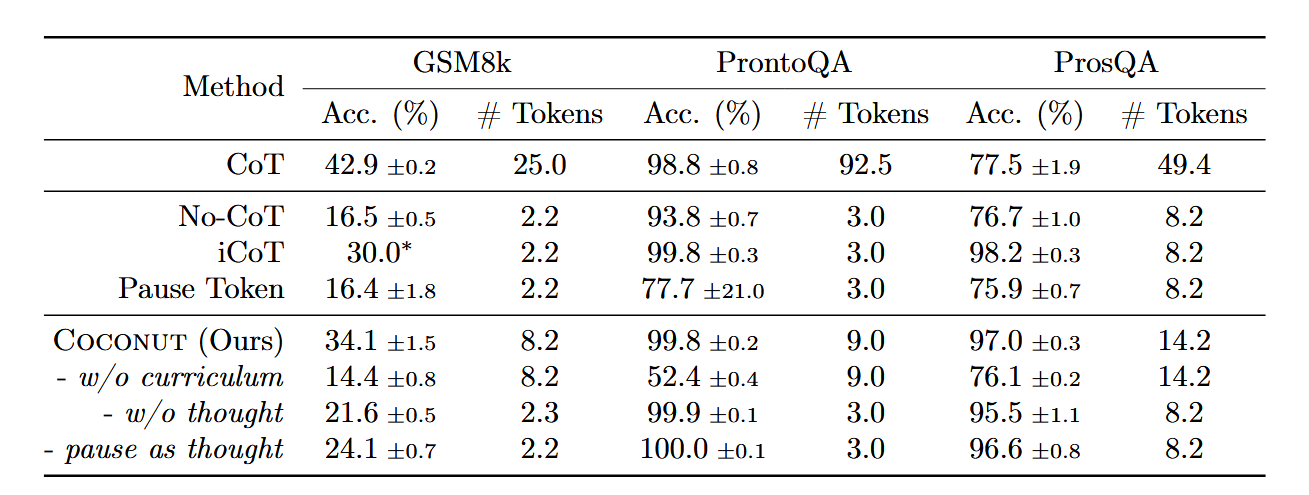
iCoT:该模型采用语言推理链进行训练,并遵循一个精心设计的 schedule,以“内化”CoT。随着训练的进行,推理链起始部分的标记逐渐被移除,直到只剩下答案。在推理阶段,模型直接预测答案。
表格中 COCONUT 下方的斜体字是 COCONUT 方法的其他变体
w/o curriculum 是不采用多阶段训练,直接使用最后一阶段的数据
w/o thought 是不使用任何 thought token,但是推理内容还是被逐步移除了(需要读一下 iCOT)
pause 是采用
数据集格式:

其他发现#
超参数 c 的选择#
c 越高,acc 越高
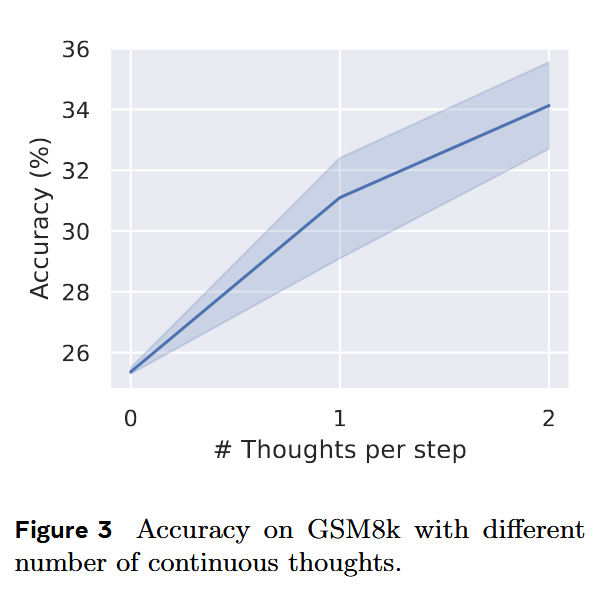
在两个逻辑推理任务上,CoT 对于 No-CoT 提升并不明显#
GSM8k 和 ProntoQA 由于直观的问题结构和有限的分支,对于下一步预测相对简单。相比之下,ProsQA 随机生成的有向无环图(DAG)结构显著挑战了模型的规划能力。latent 推理在需要大量规划的任务中具有明显优势。
超参数 k(thought 的个数)的选择#
ProsQA
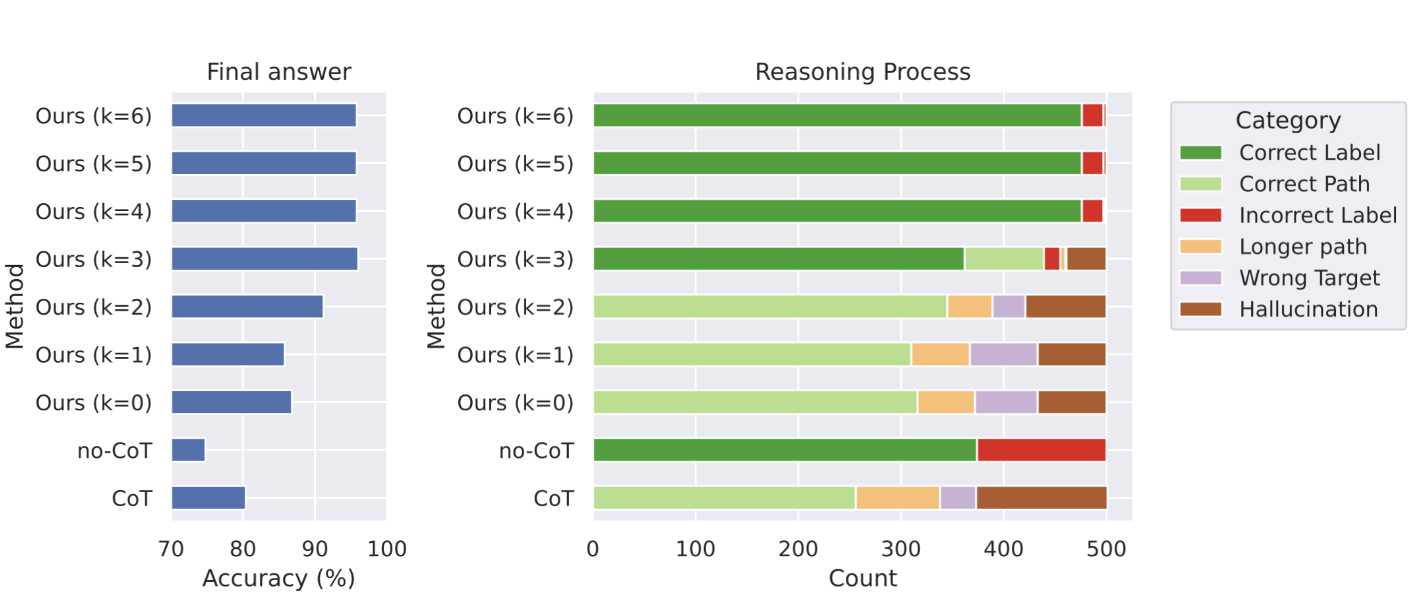
Coconut 变体#
结论#
- 哪怕是让 COCONUT 直接生成完整的思维链,其效果还是优于 CoT。因为 CoT 的训练目标在立刻生成下一步,模型“近视”;但是 COCONUT 的训练后期,前几步被隐藏了,模型更加关注未来的步骤,所以增强了其提取规划能力
实验#
在 ProsQA 上测试了 k 从 0 到 5 的所有 Coconut 变体,仅在推理过程中修改 k,没有重新训练模型
设计两组评价指标,一种是判断最终答案正确与否,另一种是判断路径正确与否
关于路径,作者提出有 6 种:
- 正确路径(Correct Path):达到正确答案的最短路径之一()
- 长路径(Longer Path):对了,但是路径更长
- 幻觉(Hallucination):路径中存在不存在的边、或路径断了
- 错误目标(Wrong Target):所答非所问
对于 k=0 或者 CoT,由于这两者会生成推理路径,则直接使用前 4 以上方法分类即可
对于 k>0,由于仅仅使用语言输出部分路径,则:如果能补全成完整的正确的推理,则分类为正确路径;也用类似的方法可以分类为长路径和错误目标;如果没法补全成完整的正确推理,就分类为幻觉
- 正确
- 错误
对于 no-Cot 和较大的 k(输出的推理少),采用以上两种分类方案
这六种类别涵盖了所有情况且无重叠。