Pause Token:隐式 CoT#
Think before you speak: Training Language Models With Pause Tokens
摘要#
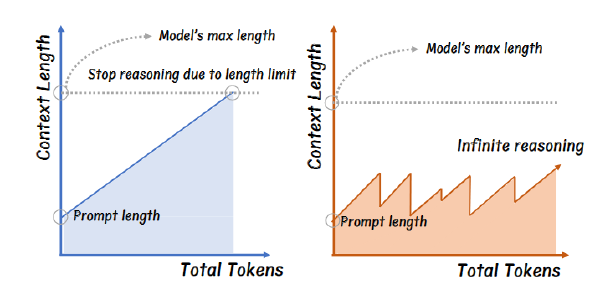
基于 Transformer 的语言模型通过连续生成一系列 token 来生成响应:**第(K + 1)个 token 是通过对每层的 K 个隐藏向量进行操作的结果,每个 preceding token 对应一个隐藏向量。但如果我们在模型输出第(K + 1)个 token 之前,让它处理比如说 K + 10 个隐藏向量会怎样?**我们通过在语言模型上进行带有(可学习的)暂停 token 的训练和推理来实现这个想法,将暂停 token 序列附加到输入前缀中。然后,我们延迟提取模型的输出,直到看到最后一个暂停 token,从而允许模型在承诺给出答案之前处理额外的计算。我们在 C4 数据集上使用因果预训练对参数量为 1B 和 130M 的仅解码器模型进行了 pause 训练,并评估了下游任务,包括推理、问答、一般理解和事实回忆。我们的主要发现是在模型既经过预训练又经过微调的情况下,推理时间延迟在我们的任务上显示出增益。对于 1B 模型,我们在八个任务上观察到了提升,其中最显著的是 SQuAD 问答任务上的 EM 得分提高了 18%,CommonSenseQA 上的提升了 8%,GSM8k 推理任务上的准确率提高了 1%。我们的工作引发了关于将延迟下一个 token 预测作为广泛应用的新范式的概念性和实践性未来研究问题。
动机#
Transformer 生成文本时,通常是基于前 K 个 token,立即预测第 K+1 个 token,其内部每层执行 K 次操作(每个 token 一次)。这种设计在模型架构初始提出时是合理的,但限制了每层的计算宽度。作者提出:**如果模型在输出下一个 token 之前,能够执行更多次操作,会不会获得更好的表达能力?**于是,他们提出通过引入 <pause> token 来打破这个限制
方法#
核心思想#
引入 <pause> token(模型可学习的 token),将其插入输入序列中,延迟模型的输出,从而让模型在每层中额外计算更多 hidden states 用于生成下一个 token。
具体#
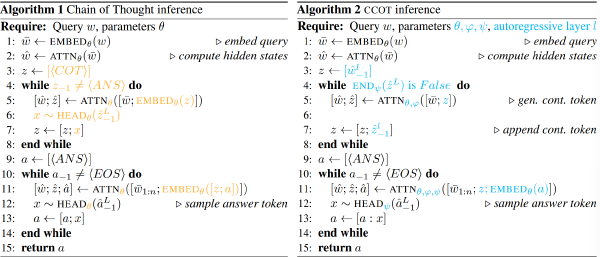
Pretrain with pause token#
由于预训练数据中没有标注哪一部分是答案,所以无法在提取答案前附加 pause token。
问题 推理 答案
问题 答案
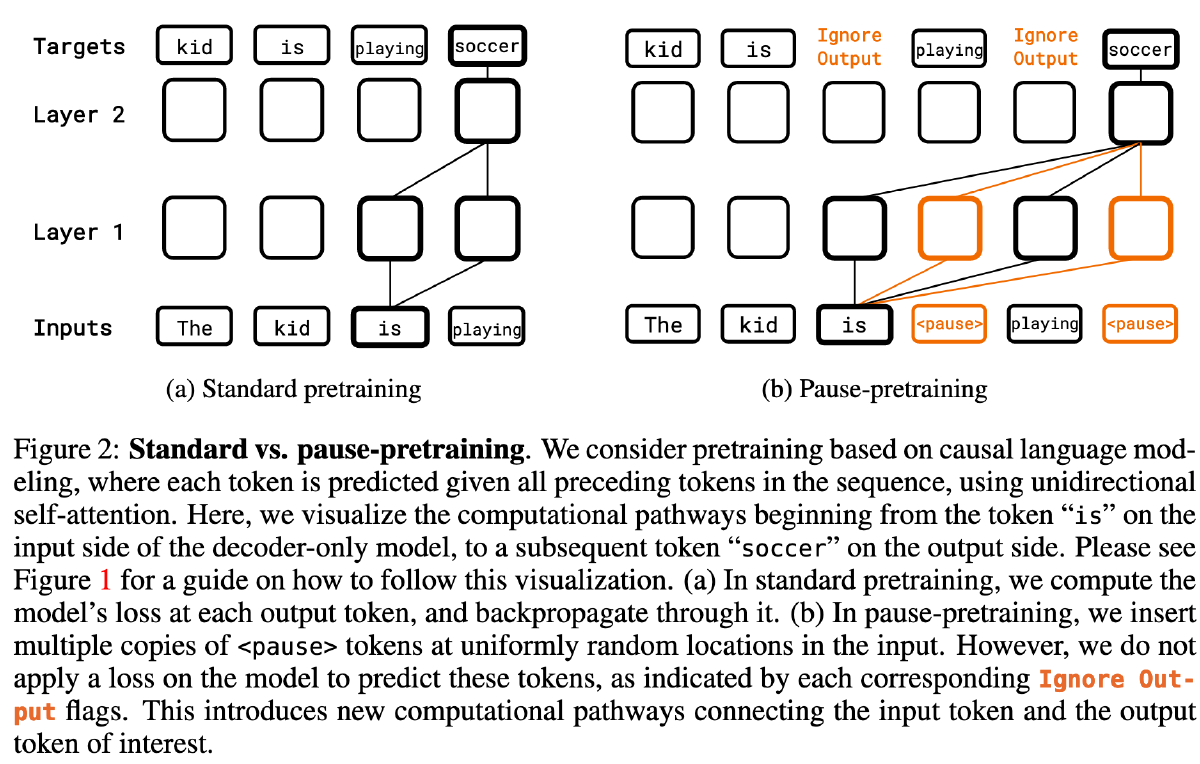
因此作者的做法是对于给定的预训练序列 p 在均匀随机的位置插入 M_pt 个 pause token(如下图 b)。然后,在加入了 pause 的 token 序列上使用标准的 next token prediction loss 来训练模型,同时在计算损失时跳过 pause token。最后,更新模型及其所有 token(包括
我们跳过了对于 pause token 的 loss 的计算,原因在于,我们只希望使用
作为一种方式来强制模型计算延迟;要求模型自身生成这些标记只会造成无谓的干扰。
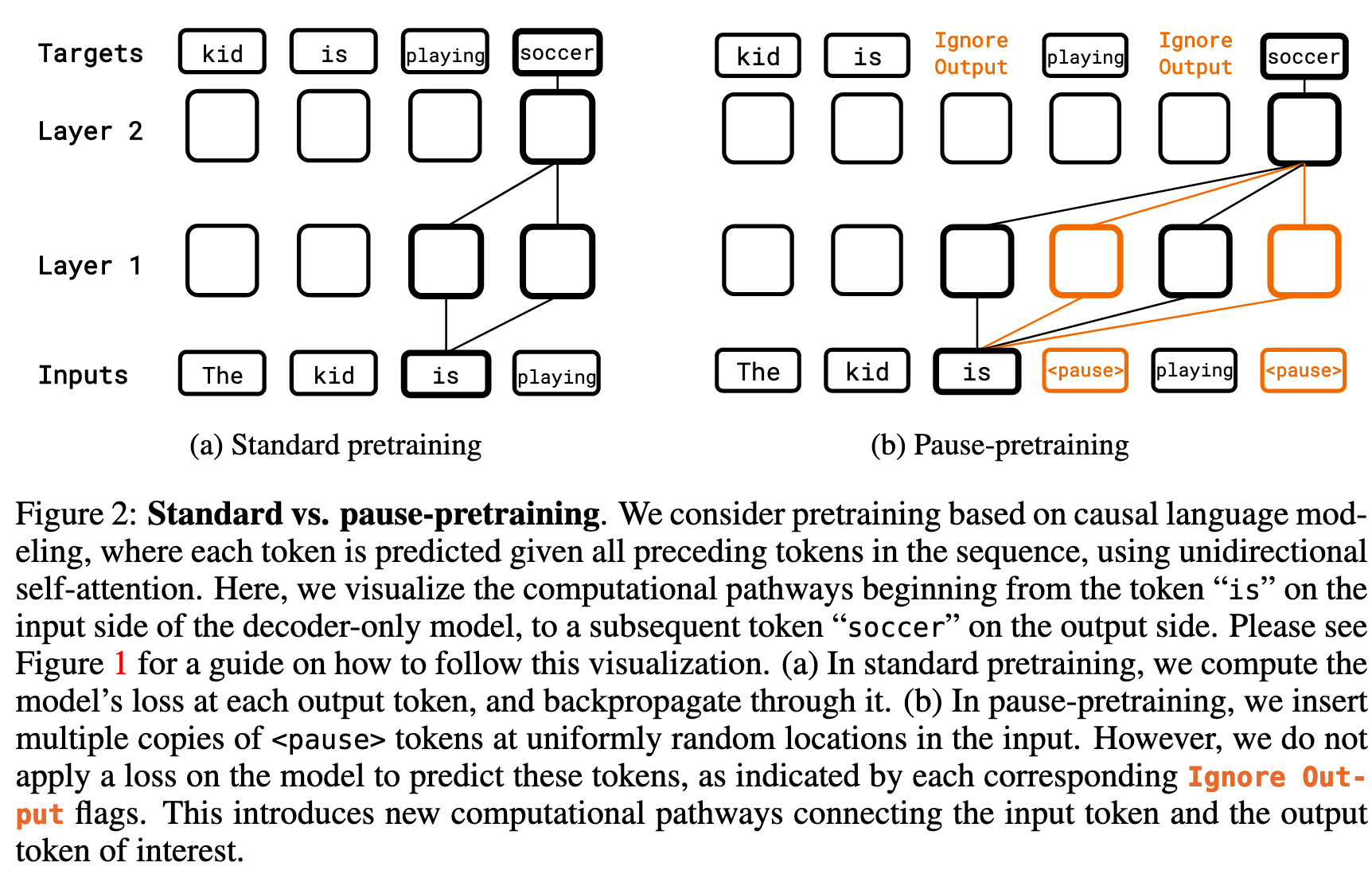
Finetune with pause token#
在微调时,使用了带有 prefix(问题)和 target(答案)的数据(没有上一步的无法区分哪一部分是答案的问题了),于是直接在 prefix 后添加 M_ft(实验中分别设置为 10 和 50)个 pause token 作为新的 prefix,如下图
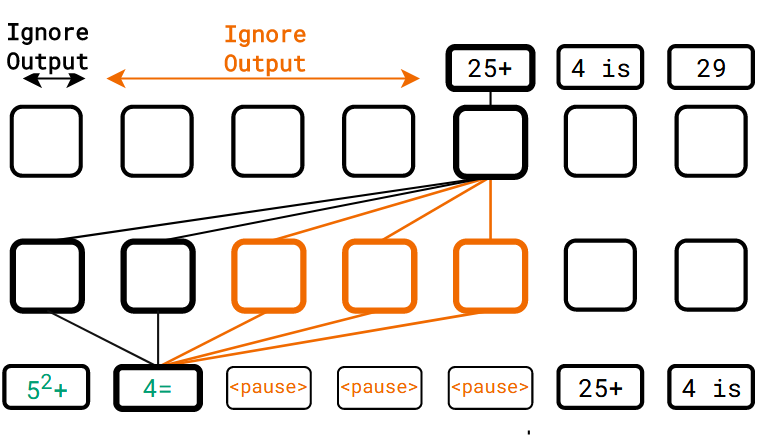
与上一个步骤一样,在看到最后一个
使用上述构建的数据微调模型,更新模型的参数以及整个词汇表的参数,还有生成 pause token 的模块的参数
Pausing during inference#
在推理时,在 prefix 后添加 M_inf(实验中与 M_ft 一致)个 pause token,并忽略模型输出直到计算到最后一个 pause token 才开始输出。
实验#
模型:选择 1B 和 130M 的 decoder-only 的模型
数据集:C4 英文混合数据集上进行预训练
2048 + 10 - 10
数据集预处理:在序列长度(2048)的 10% 位置随机插入
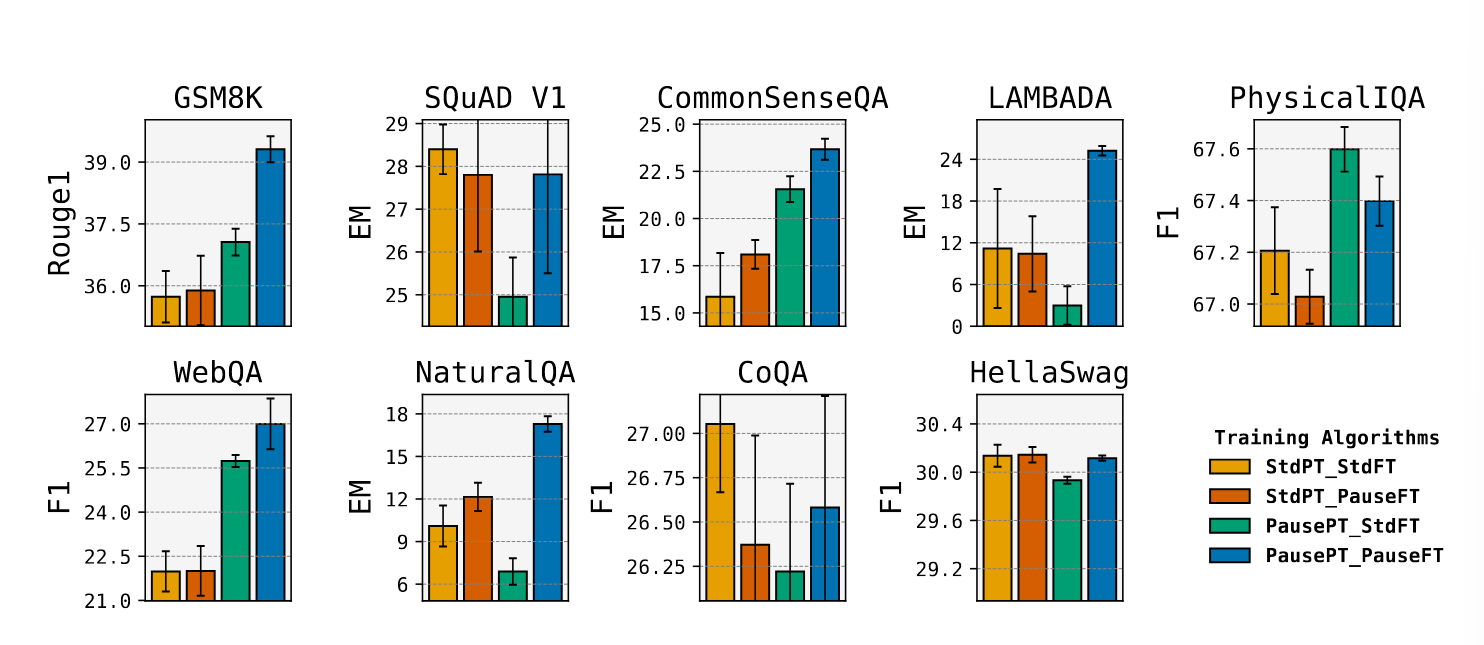
1B 模型:
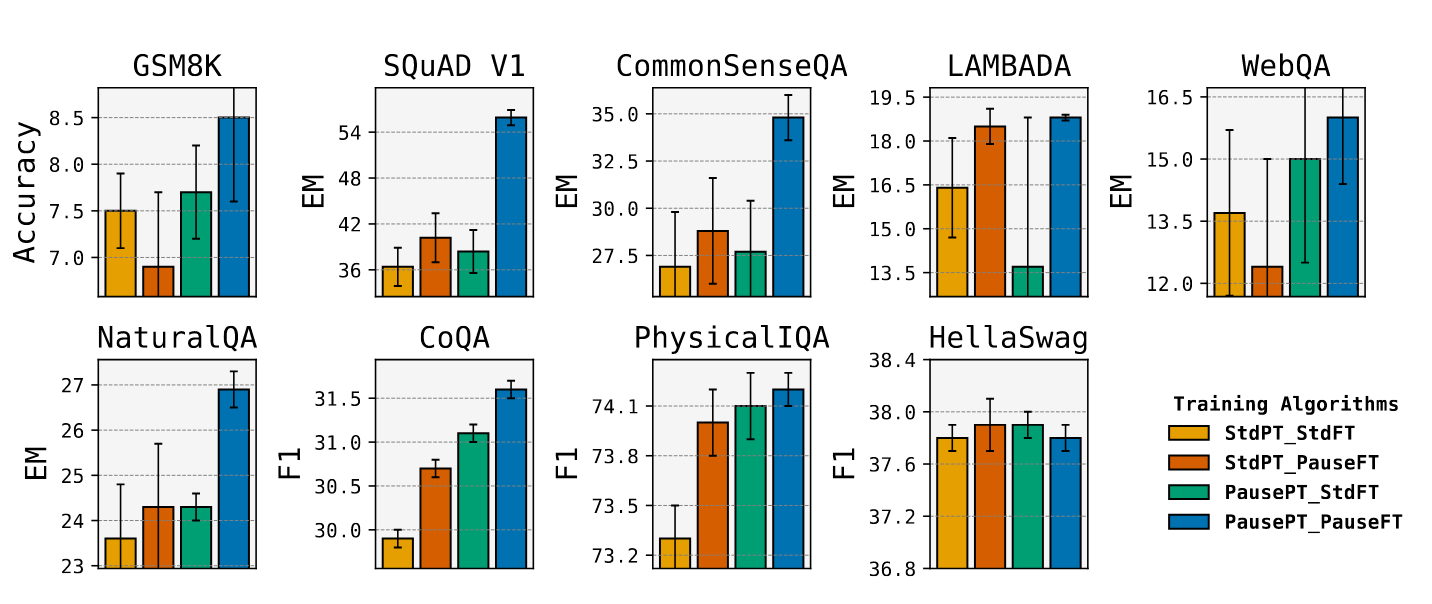
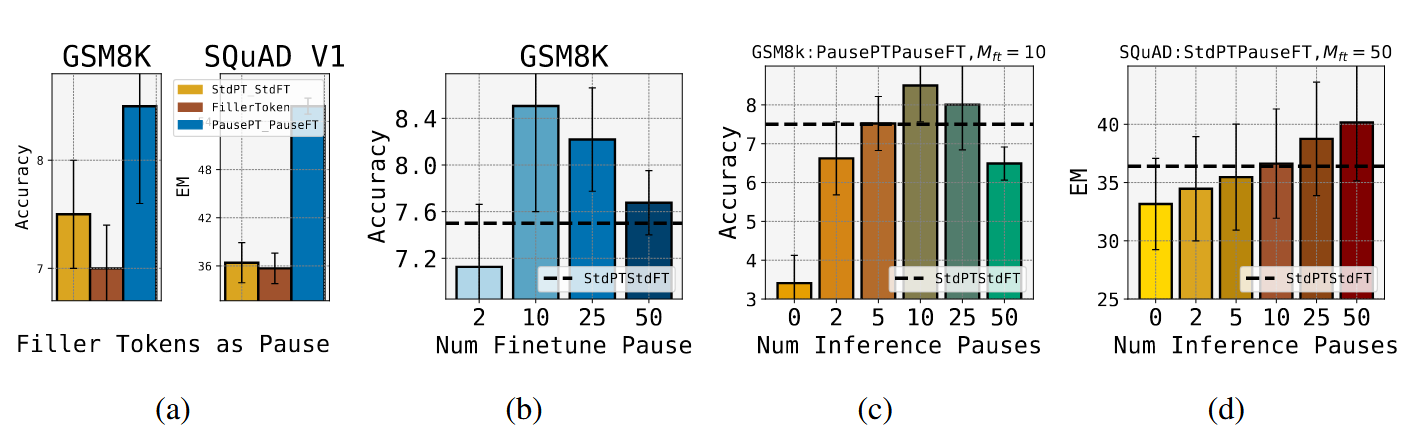
1B 模型除了 HellaSwag 数据集上,Pause 预训练-PauseFT 的组合(蓝色)均优于标准预训练-标注 FT(黄色)的组合
但是在 130M 模型上,只有 6 个数据集优于 baseline:
下图:
A. 对比 baseline 和填充省略号…而非
B. 不同下游数据集上有适合的不同 M_ft 数量
CD. 当 M_inf 不等于 M_ft 的时候,模型相比较与 baseline 的表现