Prophet:Diffusion 模型基于置信度的 Decoding 早停#
Prophet: Fast Decoding for Diffusion Language Models
摘要#
扩散语言模型(DLMs)最近作为自回归方法的替代方案出现,提供了并行序列生成和灵活的标记顺序。然而,它们的推理速度仍比自回归模型慢,主要是由于双向注意力的成本以及生成高质量输出所需的大量精炼步骤。在本工作中,我们强调并利用了 DLMs 的一个被忽视的特性——早期答案收敛:在许多情况下,正确答案可以在最终解码步骤之前的一半步骤内被内部识别,无论是在半自回归还是随机重新遮蔽调度下。例如,在 GSM8K 和 MMLU 数据集上,分别有高达 97% 和 99% 的实例仅使用一半的精炼步骤即可正确解码。基于这一观察,我们引入了 Prophet,这是一种无需训练的快速解码范式,能够实现早期提交解码。具体而言,Prophet 使用前两名预测候选之间的置信度差距作为标准,动态决定是否继续精炼或“全部投入”(即一次解码所有剩余标记)。它可无缝集成到现有的 DLM 实现中,开销可以忽略不计,并且不需要额外的训练。在多个任务上对 LLaDA-8B 和 Dream-7B 的实证评估表明,Prophet 将解码步骤数减少了多达 3.4 倍,同时保持了高质量的生成效果。这些结果将 DLM 解码重新定义为一个何时停止采样的问题,并证明早期解码收敛为加速 DLM 推理提供了一个简单而强大的机制,与现有的加速技术相辅相成。我们的代码可在 https://github.com/pixeli99/Prophet 公开获取。
Motivation#
- 实际应用中 DLM 仍然慢于 AR 模型,因为缺乏 KV Cache 以及出于性能考虑没法并行拉太大
- 在半 AR remask 和 random remask 的早期阶段,有相当高的比例的样本可以被正确解码。这一趋势在随机重掩码中更为显著。例如,在 GSM8K 和 MMLU 数据集上,分别有高达 97% 和 99% 的实例仅使用一半的精炼步骤即可被正确解码。
几个发现#
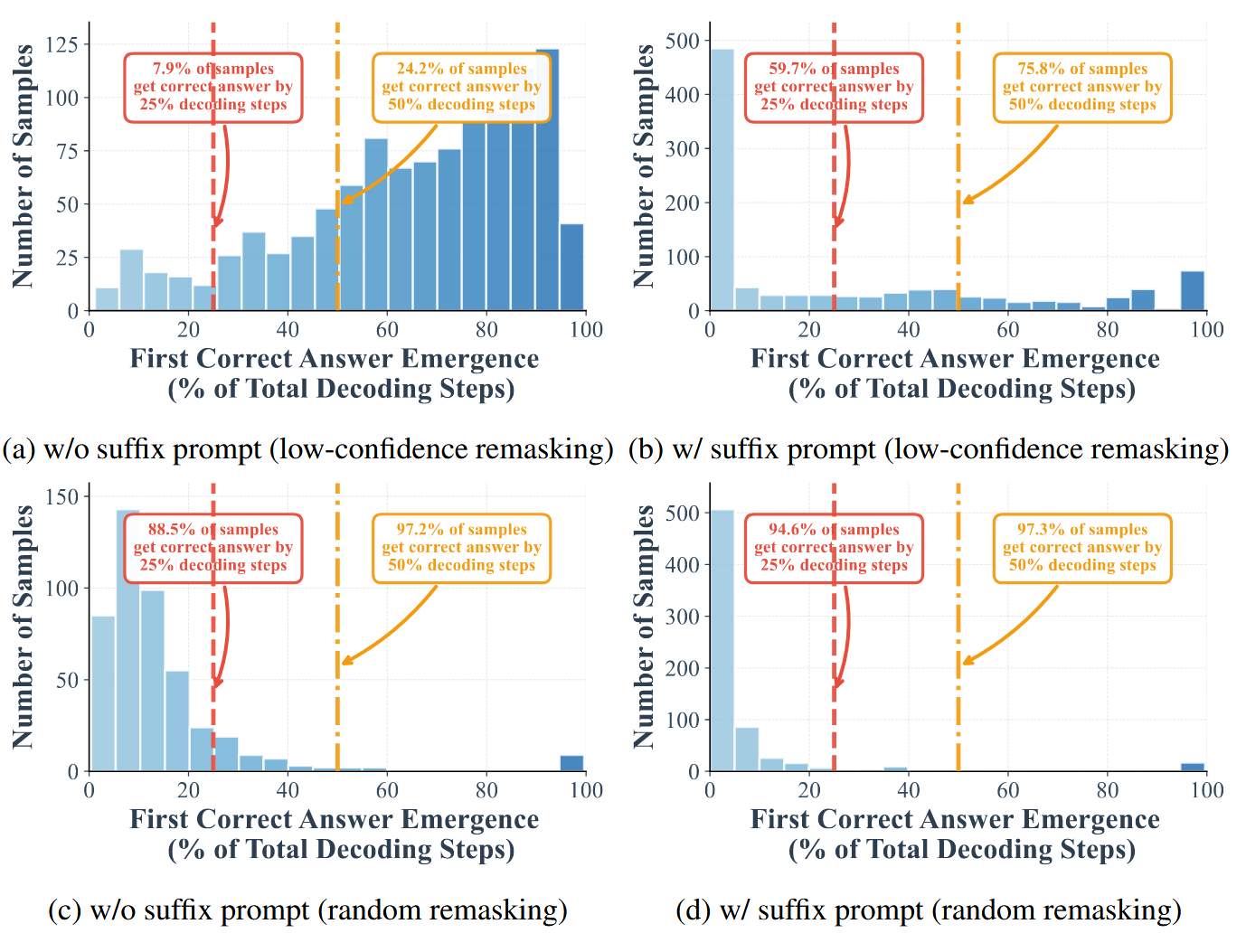
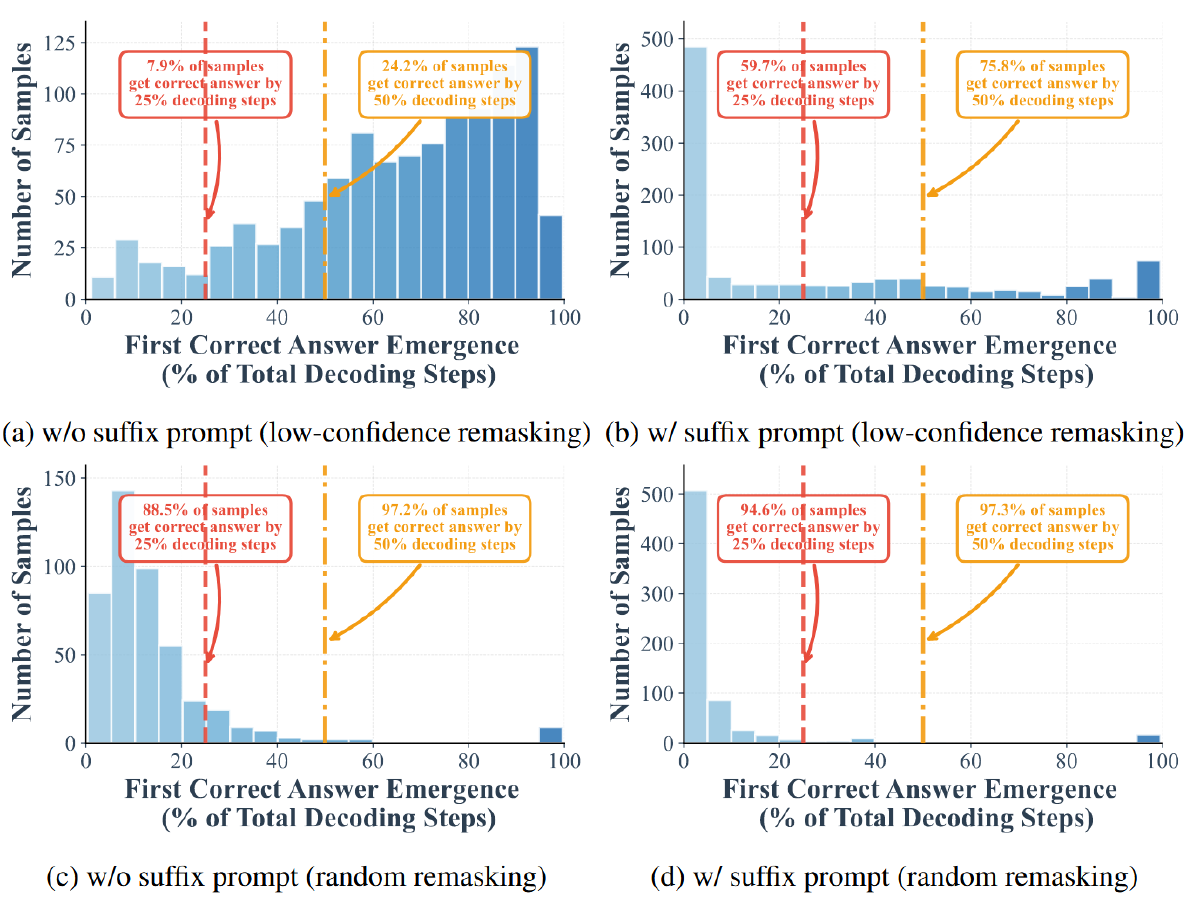
- 在解码的早期阶段,可以正确解码的样本比例较高。对比图 1(a)和图 1-(c)表明,使用低置信度 remask 时,前一半的步骤中已经有 24.2% 的样本被正确 decoding 出来,前 25% 的步骤中已经有了 7.9% 的样本被正确 decoding 出来。但是如何换成随机 remask,前一半的步骤能正确 decoding 出 97.2%,前 25% 步骤能正确 decoding 出 88.5%
- 作者添加了后缀提示“Answer”,显著提高了早期 decoding 的效果,在在随机 remask 下,25% 的步骤已经可以正确 decoding 出 94.6% 的 token 了
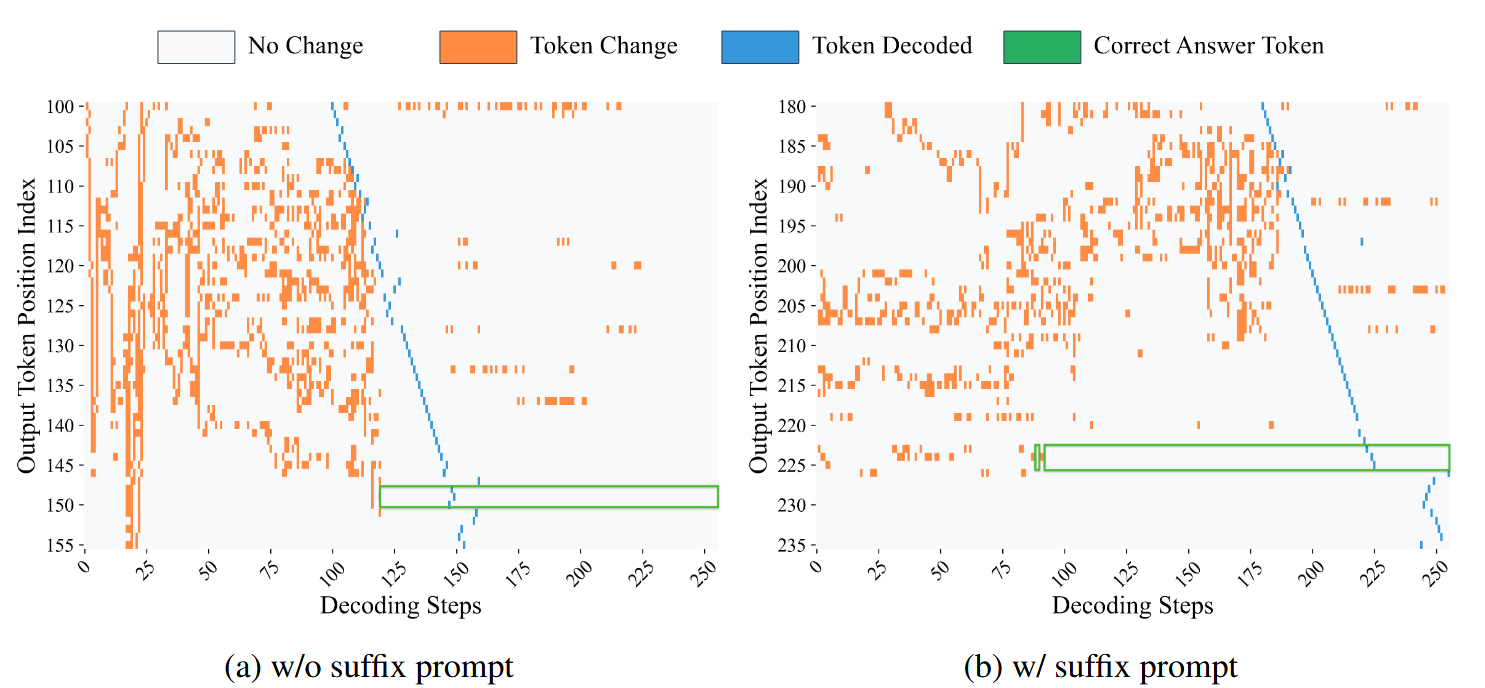
- 图 2 表明,大部分非答案 token(绿框上下的 token)在最终确定前频繁波动,但是答案 token(绿框中的 token)倾向于较早期就趋于稳定(左图是到一半的步骤时,答案 token 就停止变化了,右图是不到一半时就停止变化了,所以有至少一半的步骤是不需要的)
方法#
Prophet,Trainingfree,在模型预测稳定后立即预测答案,并一次性 decoing 所有剩余 token
每次 forward,diffusion 模型会生成一个 shape 为 \(seq\_len \times vocab\_size\)的 logit 矩阵,对于每个位置,取出其中最高 logit 值 \(L_{t,i}^{(1)}\)和次高 logit 值\(L_{t,i}^{(2)}\),并作差
$$ g_{t,i}=L_{t,i}^{(1)}-L_{t,i}^{(2)} $$设计三个阈值超参 \(\tau_{hight}、\tau_{mid}、\tau_{low}\) ,分别对应所有 decoding 步数的前 1/3、中 1/3 和后 1/3,如果 \(g_{t,i}>\tau\)则把这个 token 确定下来(greedy,选 logit 最大的)。随着解码步数的增大,即:
$$ \tau_{hight}\gt\tau_{mid}\gt\tau_{low} $$实验#
模型: LLaDA-8B、Dream-7B
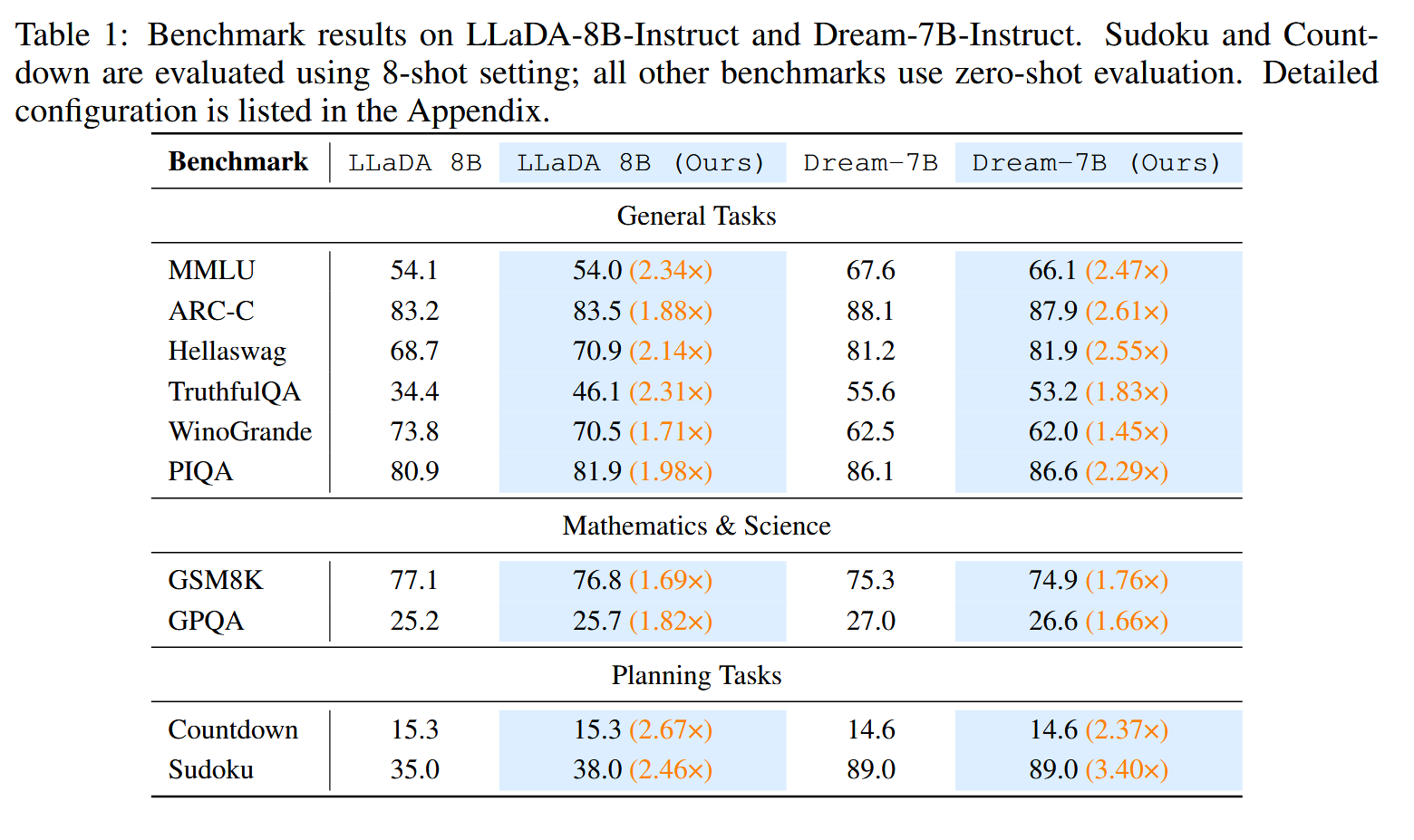
比较 3 种 decoding 策略,Full 代表标准的 diffusion,完整的步数 budget 为 50,Half 是一个简单的 baseline,将 budget 设置为 25,Prophet 为作者的方法, \(\tau_{hight}=8.0, \tau_{mid}=5.0, \tau_{low}=3.0\)
数据集:MMLU、ARC-Challenge、HellaSwag、TruthfulQA、WinoGrande、PIQA、GSM8K、GPQA、Countdown、Sudoku
采用贪婪解码
Acc 基本持平甚至,速度 1.6x~3.4x