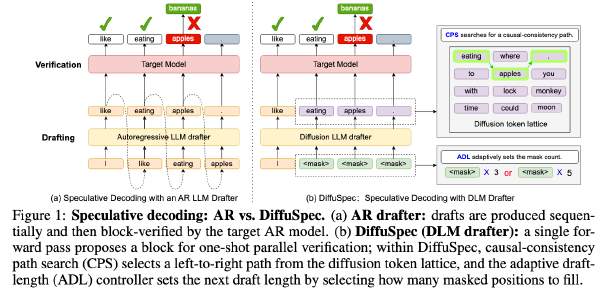
R-STITCH:用于高效推理的动态轨迹拼接#
R-STITCH: DYNAMIC TRAJECTORY STITCHING FOR EFFICIENT REASONING
摘要#
思维链(Chain-of-thought, CoT)能够增强大语言模型(LLMs)的问题求解能力,但由于其较长的自回归推理轨迹,带来了显著的推理开销。现有的加速策略要么通过提前终止或压缩来缩短推理路径,要么采用较小模型进行投机解码(speculative decoding)。然而,当模型间一致性较低时,投机解码的增益有限,并且严格强制执行 token 级别的对齐,忽略了这样一个观察:某些小模型在正确时能够生成显著更简洁的推理轨迹,从而可能减少推理长度。我们提出了 R-Stitch,一种无需训练的混合解码框架,利用 token 级别的熵作为不确定性的代理,在小型语言模型(SLM)与大语言模型(LLM)之间动态分配计算任务。我们的分析表明,高熵 token 更容易引发错误,这启发了我们设计一种基于熵的路由策略:让 SLM 高效处理低熵 token,而将不确定性较高的 token 交由 LLM 处理,从而避免完全回滚并保持答案质量。我们进一步扩展该设计,提出 R-Stitch+,其学习一种自适应路由策略,能够超越固定阈值动态调整 token 预算。通过同时降低每个 token 的解码复杂度和生成 token 的总数,我们的方法实现了显著的加速,且准确率损失可忽略不计。具体而言,在 DeepSeek-R1-Distill-Qwen-7B 上达到 3.00 倍的峰值加速,在 14B 模型上达到 3.85 倍,在 QWQ-32B 上达到 4.10 倍,同时保持与完整 LLM 解码相当的准确性。此外,该方法自然支持可调节的效率–准确性权衡,可根据不同的计算预算进行定制,无需重新训练。项目地址为 https://caesarhhh.github.io/R-Stitch。
Motivation#
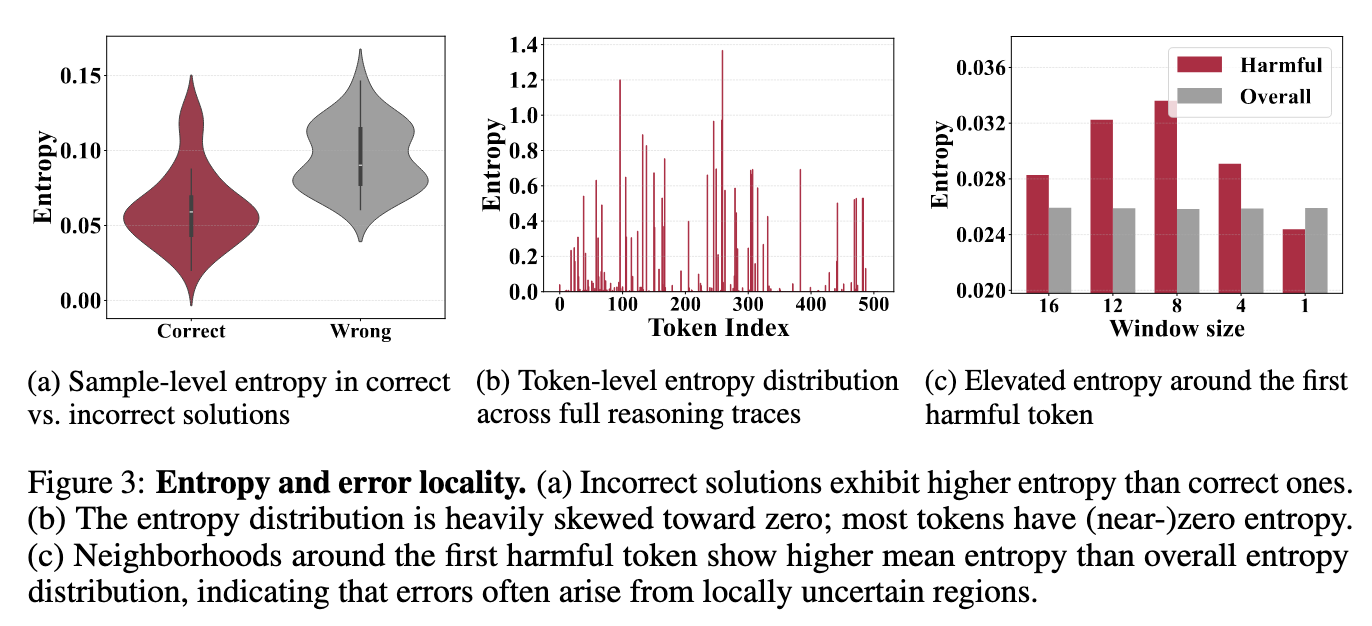
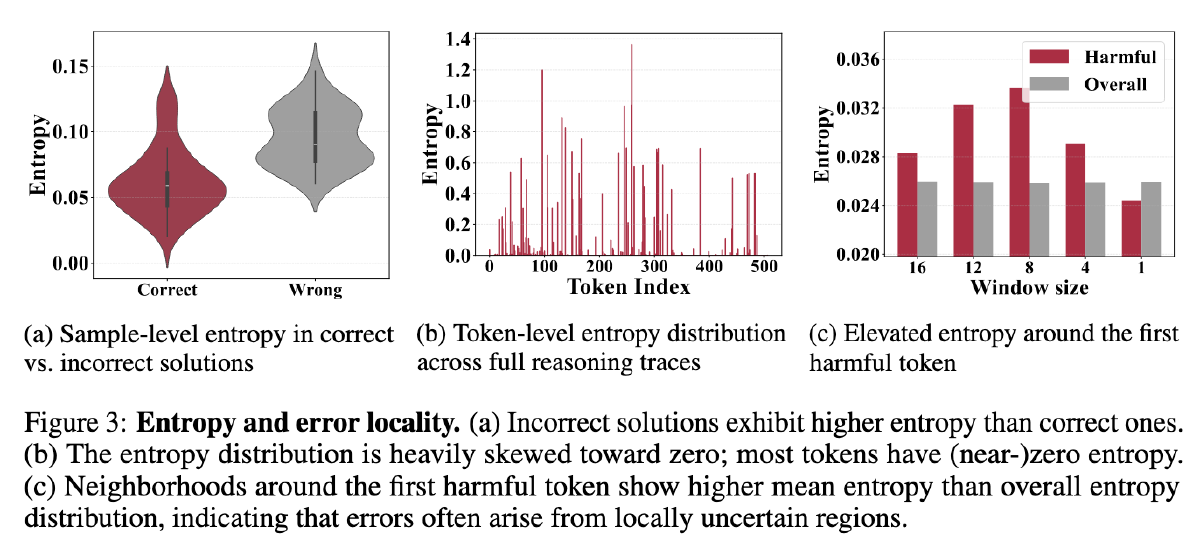
第一张图,Wrong 的答案中,每个 token 的熵总体比较大
第二张图,大多数 token 的熵很低,只有 10% 左右的 SLM 生成的 token 的熵大于 0.1
第三张图,定义有害 token 为首个使得 SLM 由正确转向错误的 token,发现有害 token 的熵要高于局部平均熵
所以可以基于熵,设计设计一个 router
方法#
基于阈值#
设计一个超参数 \(\tau\)
先由 SLM 开始生成,如果发现某个 token 的熵大于\(\tau\),则切换到 LLM;相同的,如果 LLM 生成的某个 token 的熵小于\(\tau\),就切换到 SLM
KV Cache 两个模型单独维护,每次切换就用已生成的问题去填充上新的 KV Cache
基于 RL#
当 SLM 的熵超过阈值时,将当前模型的隐藏状态将被输入到一个轻量级的路由模块,该模块决定是继续使用 SLM 还是切换到 LLM。
RL 的奖励包含两部分,acc 分数和效率分数
效率分数包含 Prefill 部分和 Decode 部分,其中 Prefill 部分的函数如下(abcd 是常数):
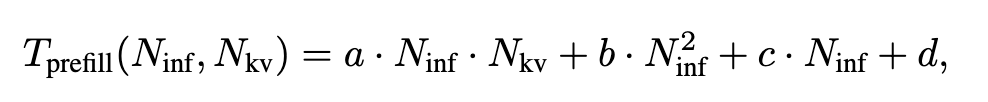
N_inf 是输入的 token 数量,N_kv 是当前阶段 KV Cache 的长度
Decode 部分的函数如下(cd 和上面的 cd 不一样,但是也是常数):
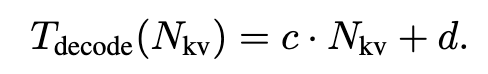
作者使用 SLM 和 LLM 在小批量数据集上测试了一波,用于拟合 T_prefill 和 T_decode 函数,后续直接基于这两个函数计算效率分数
所以总体的奖励函数是:
$$ R=r_{acc}+r_{eff}=r_{acc}-\lambda r_{acc}\hat{L}=r_{acc}-\lambda r_{acc}T_{prefill}T{decode} $$但是要注意的是,当且仅当回答正确时,才对于 eff 进行惩罚,防止模型为了追求速度而放弃精度
使用 DAPO 优化
实验#
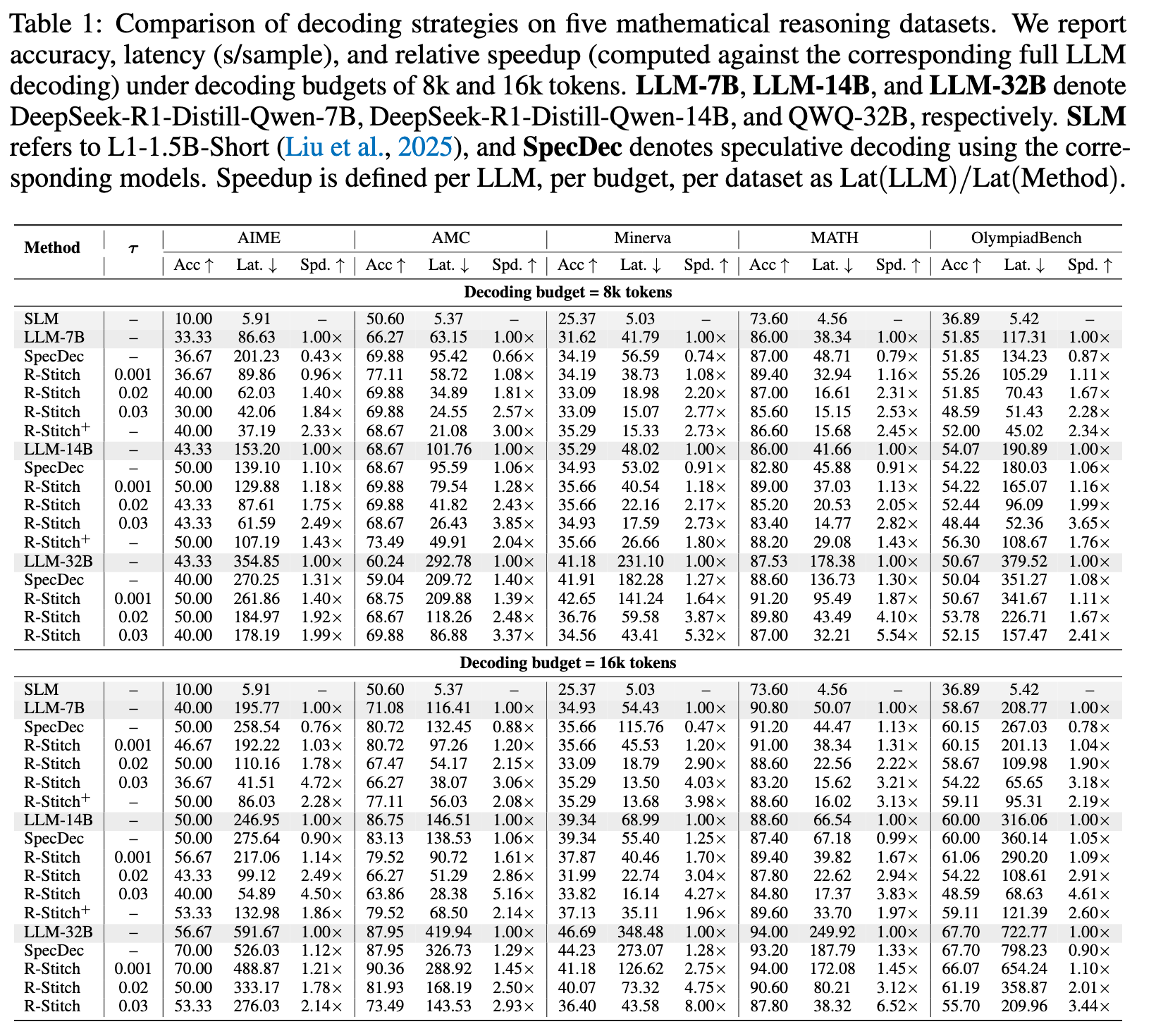
数据集:OlympiadBench、AIME、Minerva、AMC、MATH
模型:
- LLM:Deepseek-MATH-R1-Distilled-Qwen-7B、14B、QwQ-32B
- SLM:L1-1.5B-Short
超参数:lambda=5e-6,batchsize=32,rollout group size 8.