Saber:一种针对扩散语言模型的自适应加速与回溯增强的高效采样方法#
Saber: An Efficient Sampling with Adaptive Acceleration and Backtracking Enhanced Remasking for Diffusion Language Model
摘要#
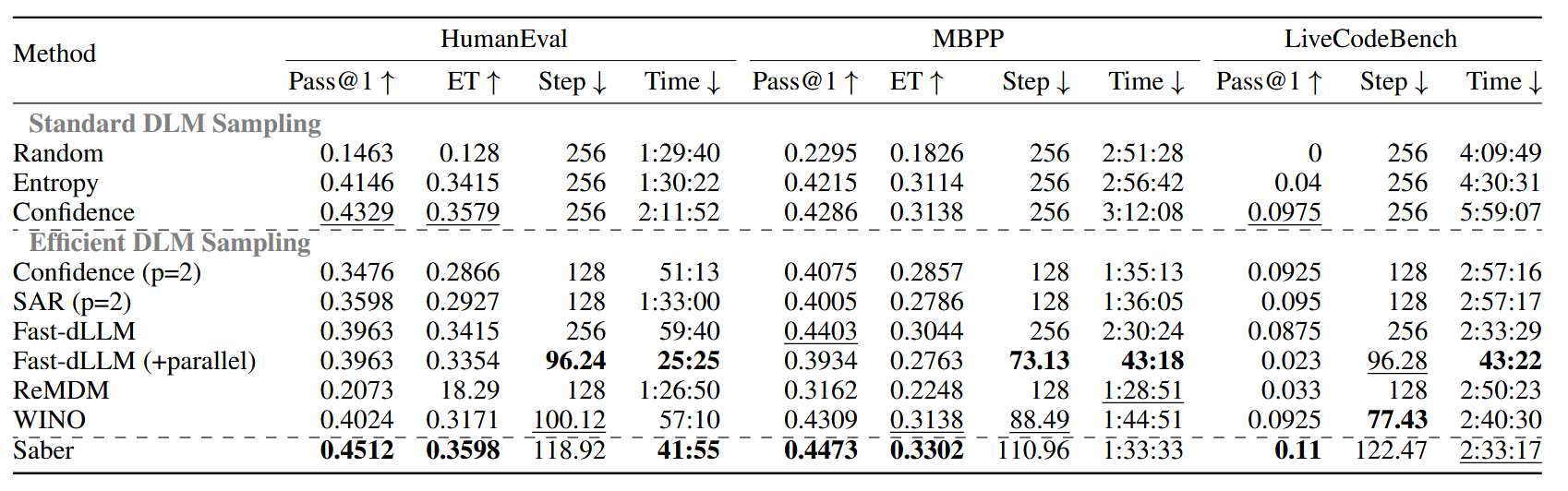
扩散语言模型(DLMs)正作为一种强大且有前景的替代方案,逐渐取代主流的自回归范式,在并行生成和双向上下文建模方面具有固有优势。然而,在代码生成任务中,由于更强的结构约束,DLMs 的性能受到推理速度与输出质量之间关键权衡的显著阻碍。我们观察到,通过减少采样步骤来加速代码生成过程通常会导致性能的灾难性下降。在本文中,我们引入了一种新的无需训练的采样算法——自适应加速与回溯增强重掩码(即 Saber),用于 DLMs 以在代码生成中实现更好的推理速度和输出质量。具体而言,Saber 受到 DLM 生成过程中的两个关键洞察启发:1)随着更多代码上下文的建立,可以自适应地加速;2)需要一个回溯机制来逆转生成的标记。在多个主流代码生成基准上的广泛实验表明,Saber 在主流 DLM 采样方法上平均提升了 1.9% 的 Pass@1 准确率,同时实现了平均 251.4% 的推理加速。通过利用 DLMs 的固有优势,我们的工作显著缩小了代码生成中与自回归模型之间的性能差距。
Motivation#
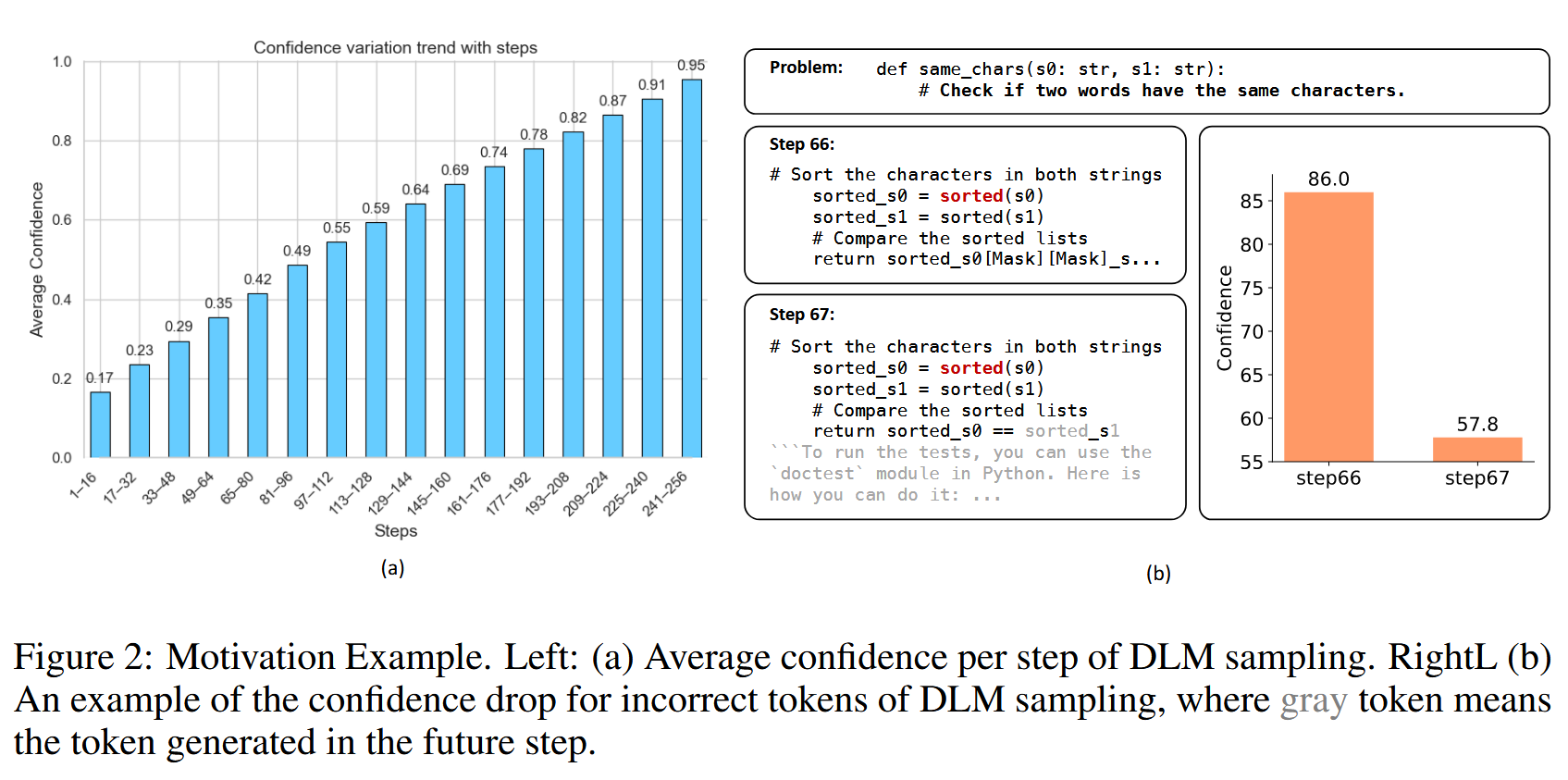
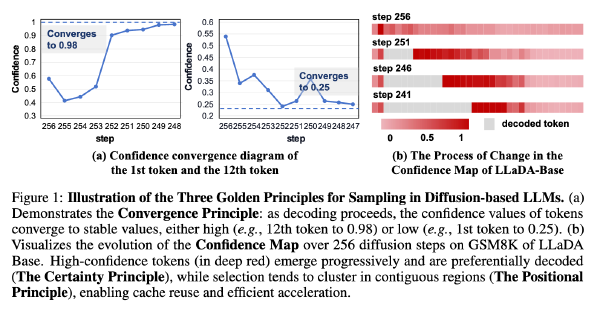
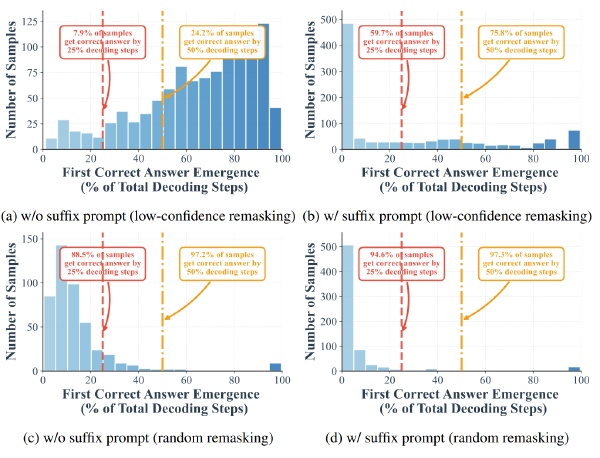
图 a 表明,DLM 生成过程难度逐渐降低。
在最开始时,由于大量 token 是[MASK],DLM 的不确定性很高,但随着逐渐解码,DLM 的不确定性逐渐降低,可以在这里使用一个自适应的加速策略,在采样初期保持谨慎,在后面逐渐激进
图 b 表明,DLM 生成具有动态上下文
DLM 具有动态的上下文,随着越来越多的[MASK]被解码,DLM 对于已经生成的 token 的置信度会发生变化,DLM 可能会越来越觉得之前生成的某个 token 是错误,但是传统的 DLM 在采样中是不可逆的,无法将一个 unmask 出来的 token 重新 mask
方法#
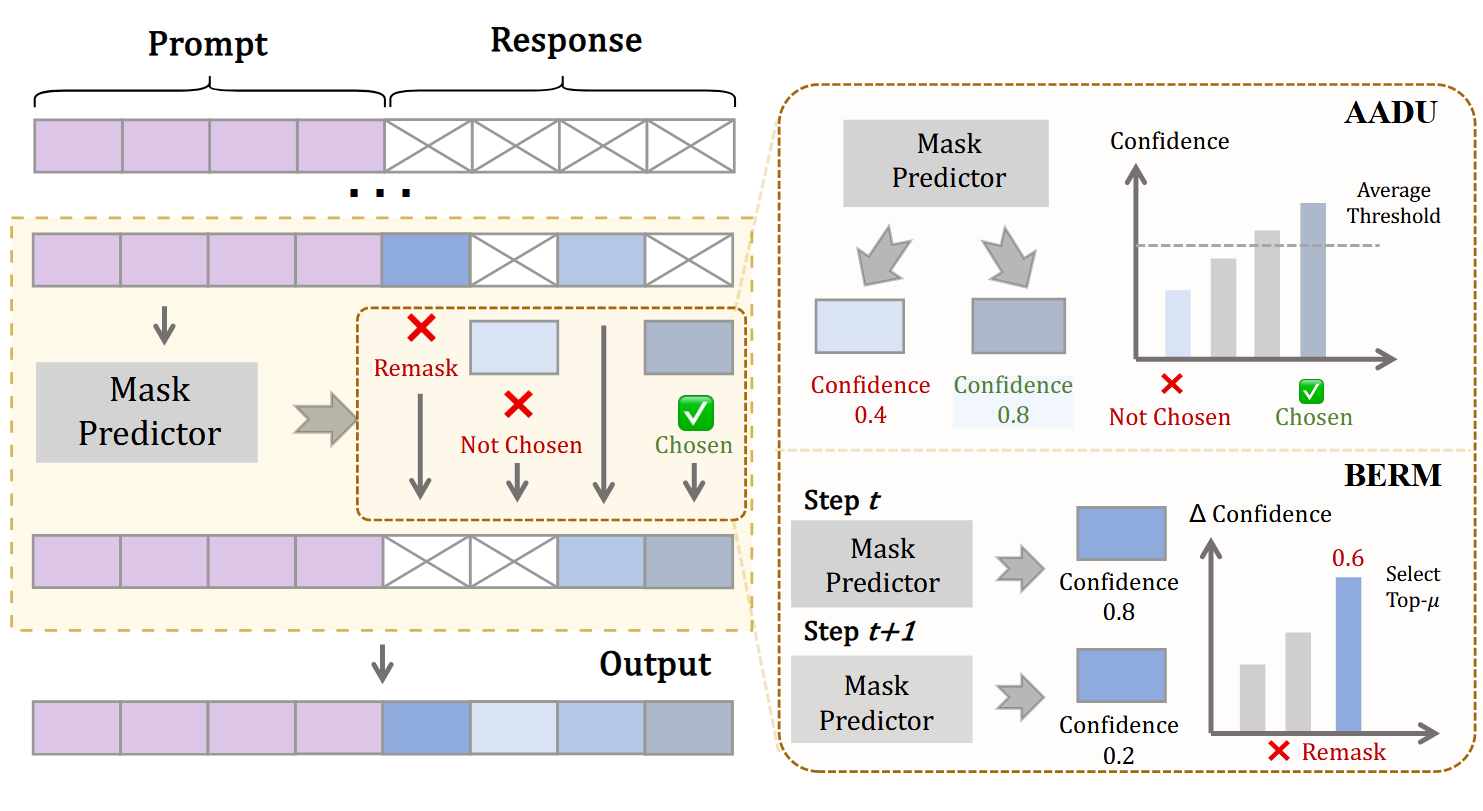
动态 unmask 自适应加速#
动态设置置信度阈值 tau_t,将其设置为之前步骤中 unmask 的 token 的平均置信度,c_max 是一个超参
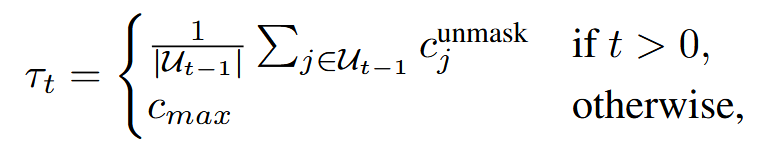
如果某些 token 的置信度超过 tau_t,就并行解码出来,作为 Draft,记作 D_t
Remask#
先基于上一步 decode 的激进程度,判断这一步需要 remask 的 token 数量,mu 是一个超参
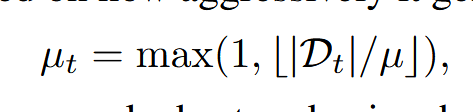
然后计算先前已有的 token 的置信度变化(不包括刚刚 decode 出来的 token):
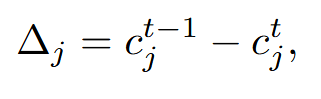
选出 top-mu_t 的 token,将其重新回退为[MASK]
实验#
A6000(48G)、LLaDA-8B-Instruct,max_new_tokens 设置为 256、block_size 设置为 128
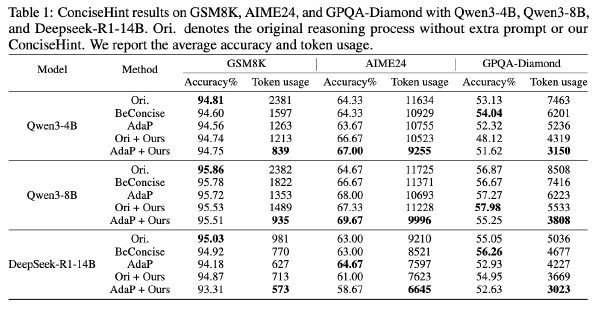
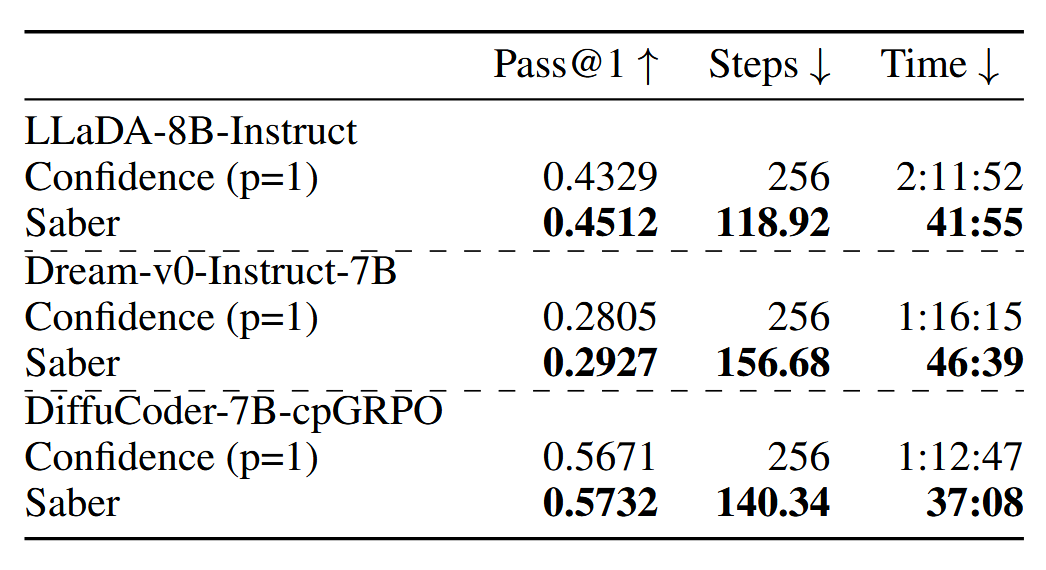
在其他模型上面的效果(HumanEval)
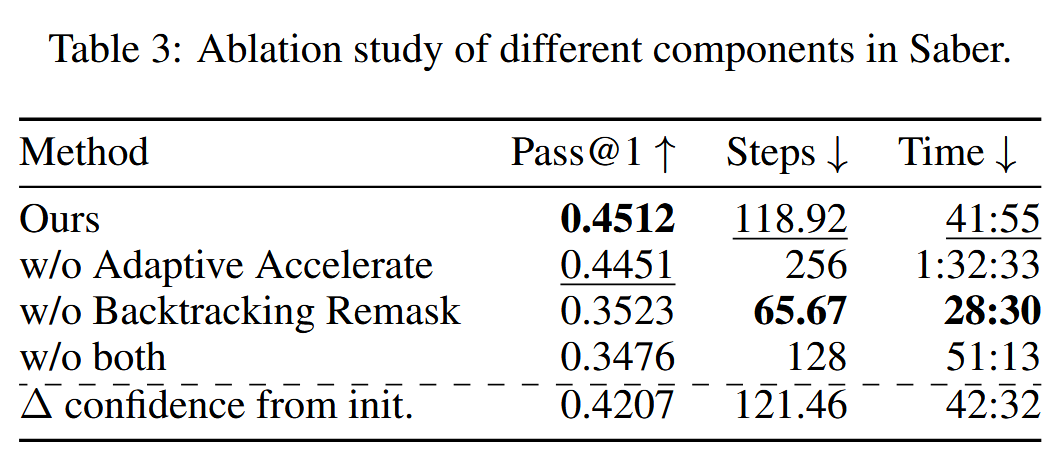
消融#
一些其他想法#
在另一篇文章中看到以下内容:
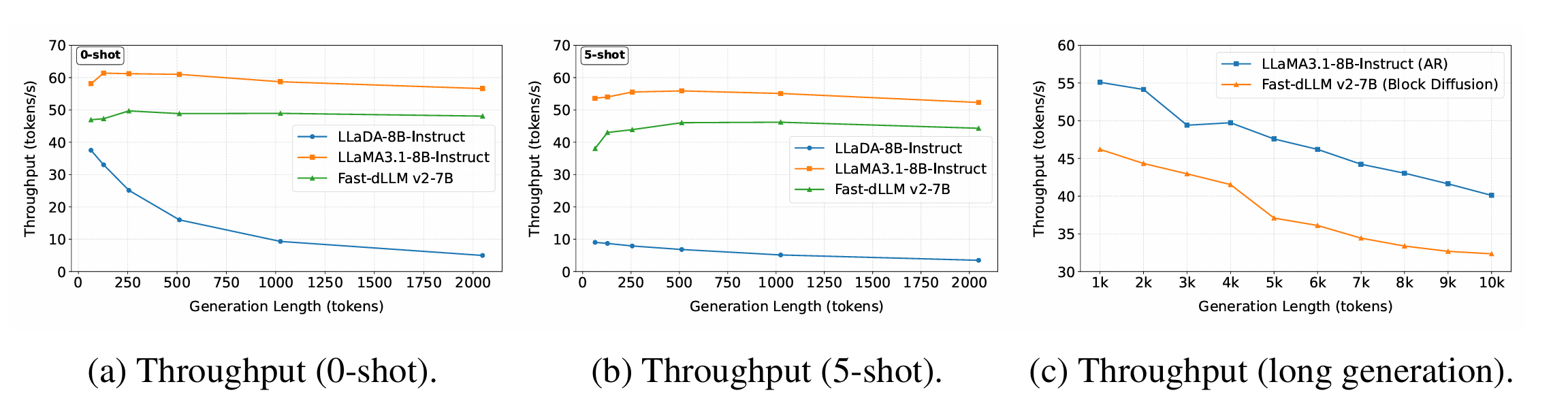
DLM 相比同参数的 AR,可以说很慢了