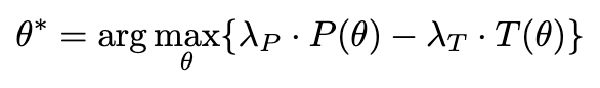SEAL:大语言模型的可操控推理 Traning Free#
SEAL: Steerable Reasoning Calibration of Large Language Models for Free
摘要#
大语言模型(Large Language Models,LLMs),例如 OpenAI 的 o1 系列,已展现出通过扩展的思维链(chain-of-thought,CoT)推理机制处理复杂推理任务的出色能力。然而,最近的研究(Fu 等,2024;Wang 等,2025)揭示了 CoT 推理轨迹中存在显著冗余,这不仅增加了推理延迟,还因将注意力分散至不必要的推理路径而对模型性能产生负面影响。为了解决这个问题,我们研究了 LLMs 内部的推理结构,并将其归类为三种主要思维类型:执行(execution)、反思(reflection)和过渡(transition)思维。此外,我们的分析表明,过多的反思与过渡思维与失败案例高度相关,并且这些思维类别在潜在空间中表现出清晰的分离性。基于这些发现,我们提出了 SEAL(Steerable rEAsoning caLibration),一种无需训练的方法,可无缝校准 CoT 过程,在提高准确性的同时展现出显著的效率提升。SEAL 包括一个离线阶段,用于在潜在空间中提取推理引导向量;随后是在推理过程中通过表示干预利用该引导向量进行即时校准。值得注意的是,该引导向量在多种任务之间表现出强迁移能力。广泛的实验在多个模型(DeepSeekR1-Distill 和 QwQ-32B-Preview)以及多个基准(Math500、GSM8K、LiveCodeBench)上验证了 SEAL 的有效性,准确率最高提升了 11%,同时推理 token 减少了 11.8% 至 50.4%。
https://github.com/VITA-Group/SEAL
Motivation#
- CoT 推理轨迹中存在显著冗余,这不仅增加了推理延迟,还因将注意力分散至不必要的推理路径而对模型性能产生负面影响。
- LLM 按照执行、反思和过渡思维进行 think,且这些 thought 在隐藏状态中是可以被分离出来的
LLMs 的推理模式#
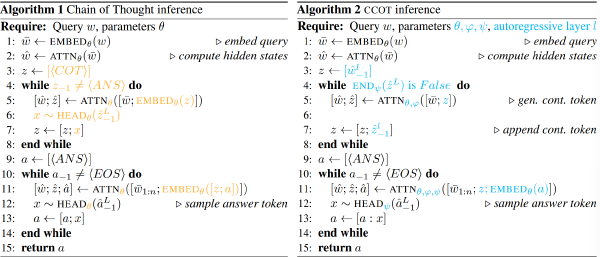
使用"\n\n"分割整个 think 过程,每一段作为一个 thought,将这些 thought 分成 3 类:
- 执行思维:其中模型分析问题并逐步求解
- 反思思维:模型暂停推理过程以验证其步骤
- 过渡思维:模型转换推理流程,并从另一个角度 rethink

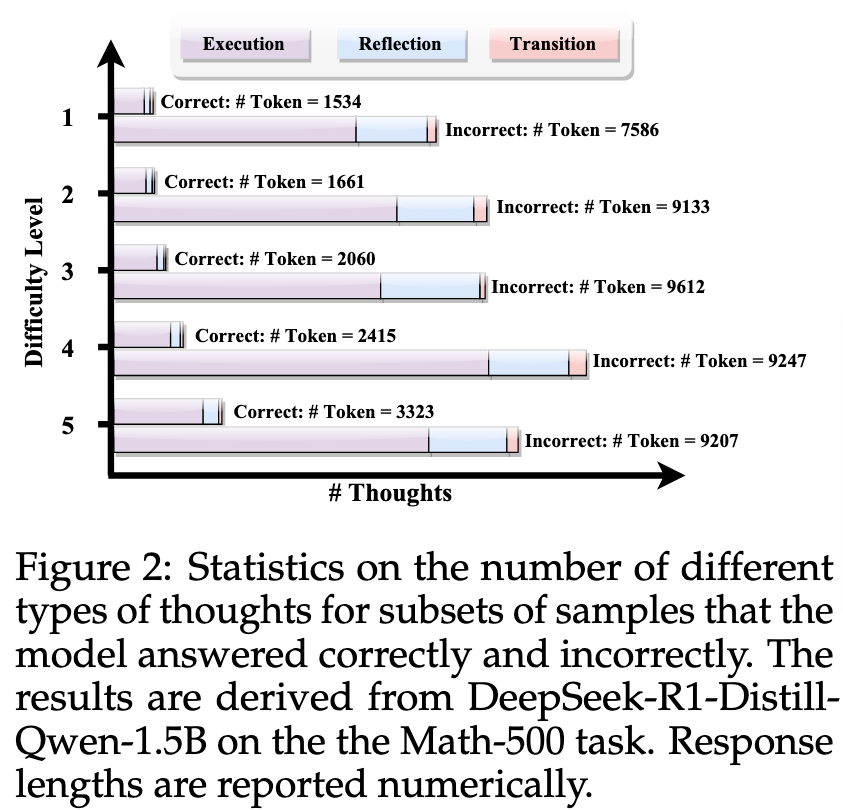
对于三种 thought 的 token 数量和最终答案正确与否分类统计了一下,得到以下结果:
- 随着题目难度增加,Token 消耗越来越多
- 错误样本中的 Token 数量显著高于正确样本
且每种类型的思维在错误案例中均表现出更多的步骤。鉴于正确和错误样本的难度具有可比性,这些结果表明,此类过多的推理步骤在必要推理过程之外引入了显著冗余,并可能对性能产生负面影响。
错误样本中思维数量的增加主要由反思和过渡思维的增加所驱动,因为每个反思或过渡步骤通常都伴随着多个执行步骤。
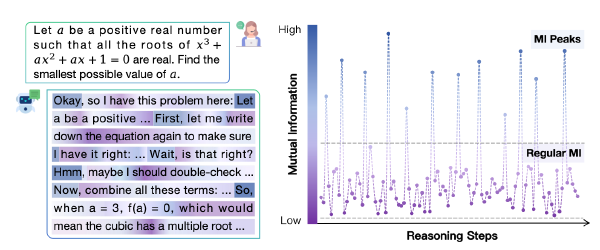
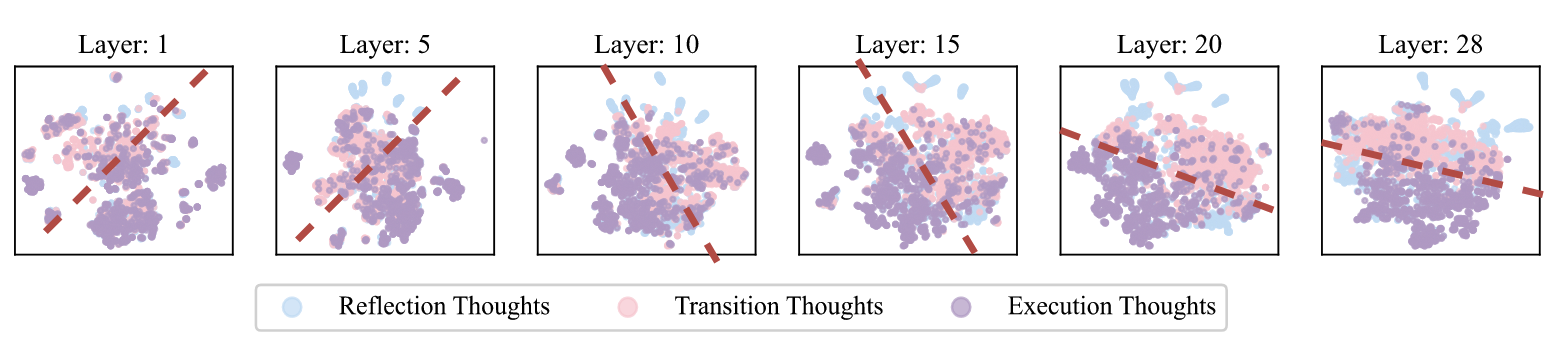
不同 thought 的隐藏状态特征#
t-SNE 降维
- 执行思维和其他思维在隐藏状态中可以区分开(例如第 20 层)
- 不同思维的可分离性在深层中表现得显著更好,而初始层则难以区分它们。
- 反思思维和过渡思维彼此之间的相似性要高于与执行思维的相似性。直观上,反思和过渡思维都涉及对先前推理步骤的重新考虑或修改,而执行思维则代表原始的逐步推理过程。
DeepSeek-R1-Distill-Qwen-1.5B 在 MATH500 上
方法#
推理引导向量提取#
从数据集中抽取出一部分作为验证集,让 Reasoning 模型进行推理,并依据\n\n 切分成多个 thought,使用关键字将 thought 进行归类(‘Alternatively’就归类为过渡)

其他 Thought 将被归类为执行 Thought
对于每个 Thought j,从第 i 层 Transformer 中提取对应于第一个 token“\n\n”的输出表示,记为 Hj i。然后计算每个思维类别的平均表示:
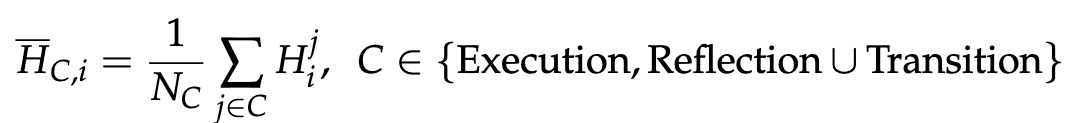
由于作者的主要目标是保留执行 Thought 而减少不必要的反思和过渡,因此构建引导向量:
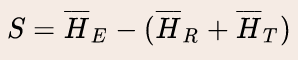
解码时隐藏状态干预#
使用上述的 S 向量对于解码过程进行即时干预
在解码过程中,在每一个思维步骤结束时,通过对某一层所有 \n\n token 的隐藏状态应用基于 S 得到的偏移量来进行干预,其形式化表示为:H_e = H + α · S,其中 α 是一个超参数。
由于提取过程是离线进行的,因此不会在解码过程中引入任何额外的延迟
实验#
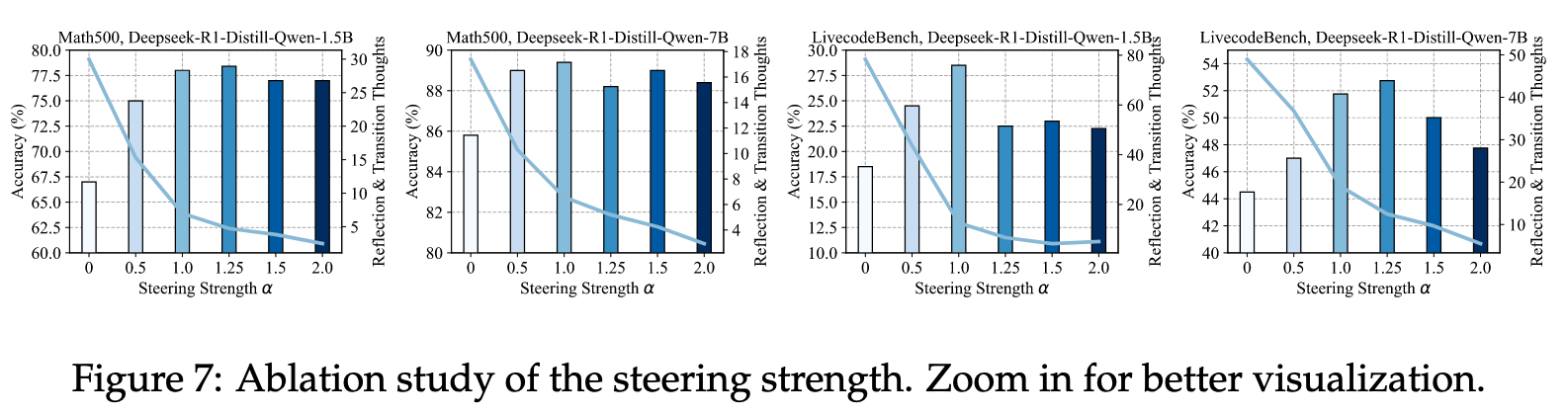
超参数: \(\alpha=1\)
模型:Deepseek-R1-Distill-Qwen-1.5B(干预第 20 层),Deepseek-R1-Distill-Qwen-7B(干预第 20 层),QwQ-32B-Preview(干预第 55 层)
数据集:Math500、GSM8K、LiveCodeBench
贪婪解码
下表中的 Logits Penalty 是 baseline,指对于和对应 thought 相关的 token 施加 logits 惩罚的结果,比如对于 wait 和 alternatively token,惩罚值为-3
下面两个表的引导向量 S 都是在 MATH500 的一个 subset 上提取出来的,但是都没有汇报是如何划分 subset 的,也没有汇报这个 subset 是否和测试用的数据集有重叠,所以第一个表参考价值不是很大,但是第二个表参考价值一些
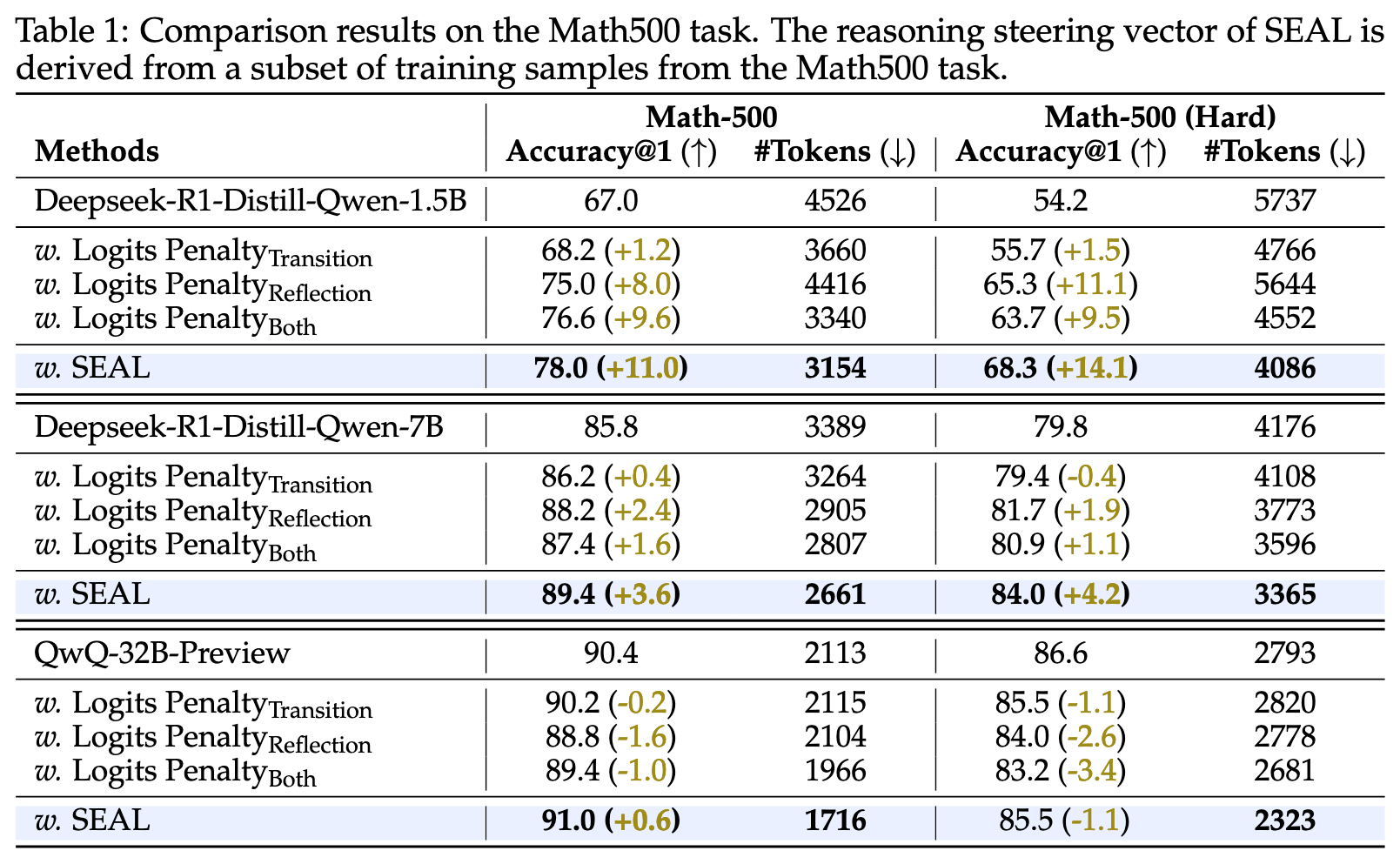
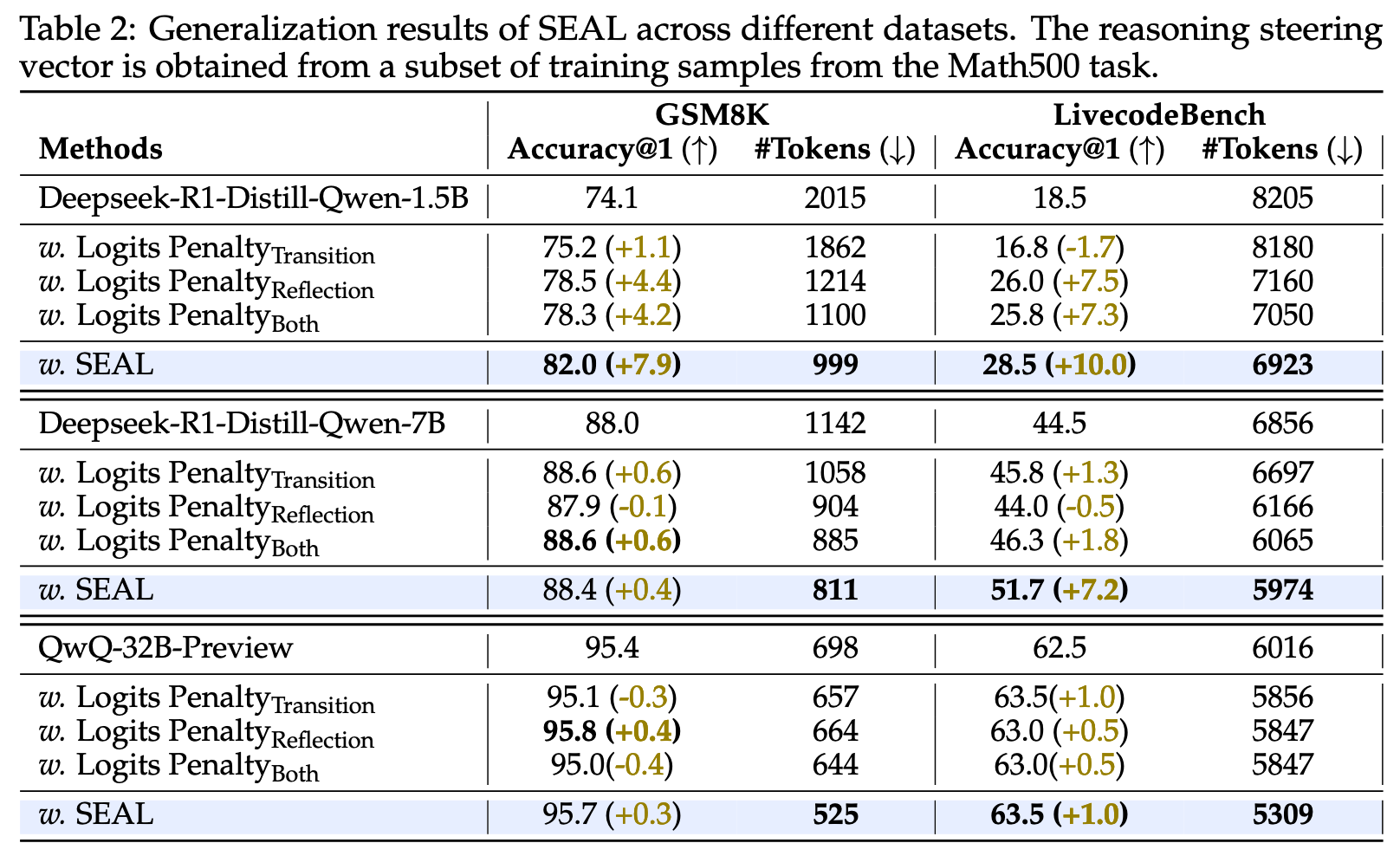
对于为什么施加 logits 惩罚反而可能提升了 token 数量,作者解释如下:
Logit Penalty(即 token 空间调整)方法的一个局限性在于,它通常针对单个 token 进行操作,例如 alternatively 或 wait,而不是在概念层面进行调整。然而,反思和过渡性思考通常通过短语或更长的句子表达,例如 let me double-check 或 another approach is。这种情况仅通过 Logit Penalty 难以完全抑制。此外,我们观察到,即使降低了这些思考中代表性 token 的 logit 值,模型仍然表现出反思和过渡的倾向——只不过是以更隐晦的方式,例如通过改写表达。
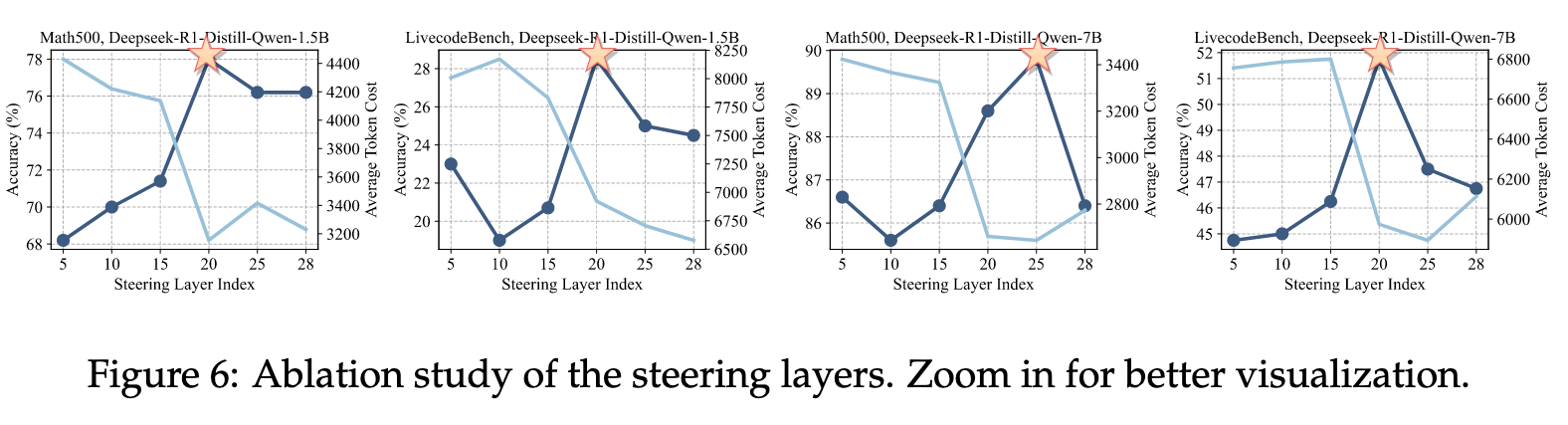
消融实验#
- 使用引导向量弱化不同 thought
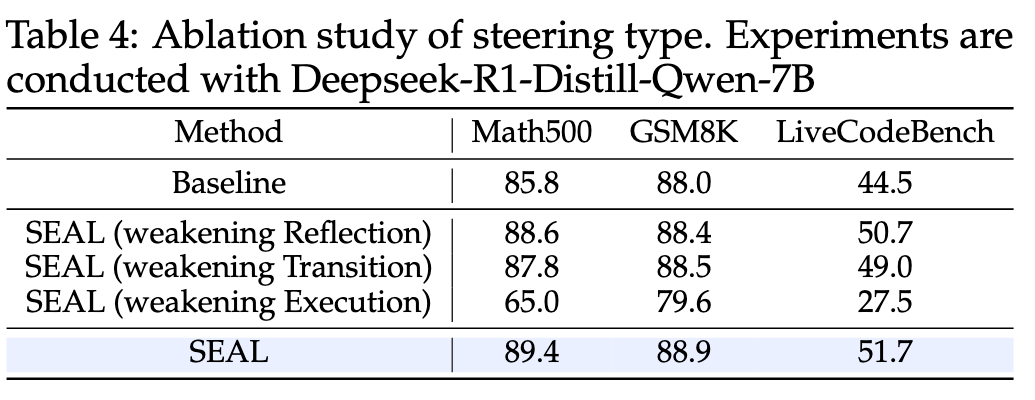
- 对不同层施加
- 不同系数 \(\alpha\)