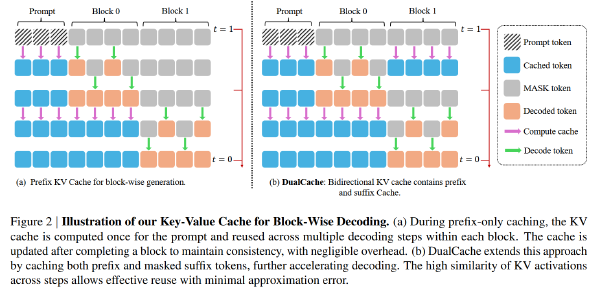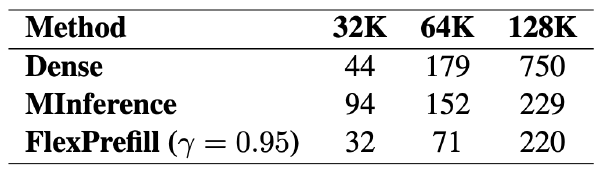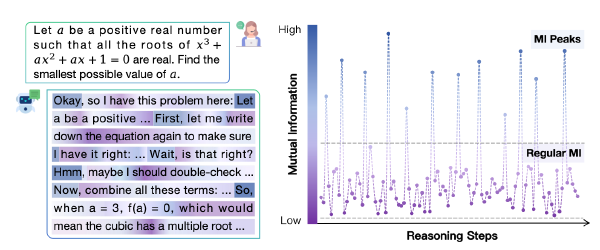
SlowFast 采样加速 DLM#
ACCELERATING DIFFUSION LARGE LANGUAGE MODELS WITH SLOWFAST SAMPLING: THE THREE GOLDEN PRINCIPLES
Code: https://github.com/LiangrunFlora/Slow-Fast-Sampling
摘要#
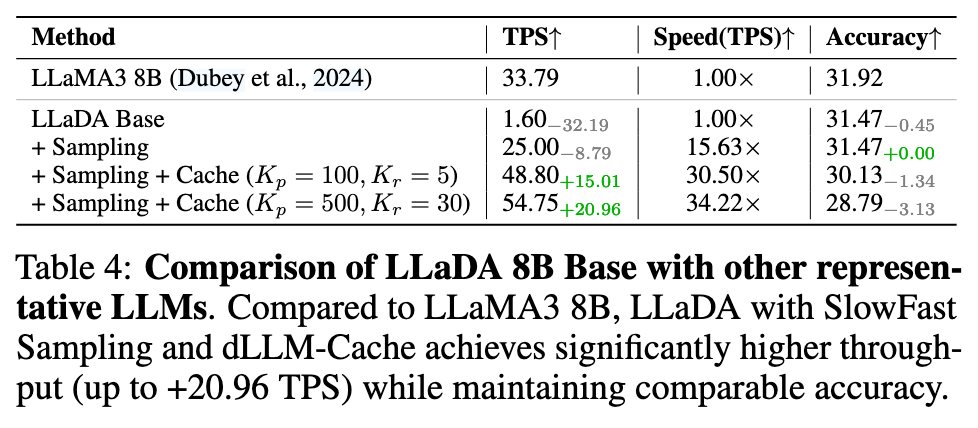
基于扩散的语言模型(dLLMs)通过实现并行 token 生成,显著降低了推理延迟,已成为传统自回归 LLM 的一个有前景的替代方案。然而,现有的 dLLMs 采样策略,如基于置信度或半自回归解码方法,通常表现出静态行为,导致效率次优且灵活性受限。本文提出了 SlowFast Sampling,一种新颖的动态采样策略,能够自适应地在探索性解码与加速解码阶段之间切换。我们的方法由三个黄金原则指导:确定性原则、收敛性原则和位置性原则,这些原则决定了何时以及何处在可信赖且高效的前提下进行 token 解码。我们进一步将该策略与 dLLM-Cache 相结合,以减少冗余计算。在多个基准和模型上的大量实验表明,SlowFast Sampling 在 LLaDA 上实现了最高达 15.63 倍的加速,在结合缓存时最高可达 34.22 倍,且精度损失极小。值得注意的是,我们的方法在吞吐量方面优于 LLaMA3 8B 等强自回归基线,证明了精心设计的采样策略可以充分释放 dLLMs 在快速高质量生成方面的潜力。
Motivation#
当前 DLM 要么基于置信度选择 token 并将其 decode 出来,要么采用半 AR 解码。然而这两者方法在并行解码大量 token 的时候效果并不理想,且在整个生成过程中表现出静态、恒定的采样速度。
因此作者希望能提出一种动态的采样策略,一种能够决定每一步采样多少 token、哪些 token 的策略
观察到的现象#
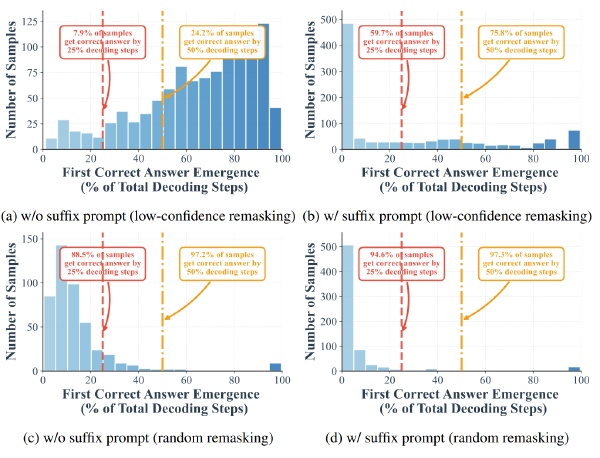
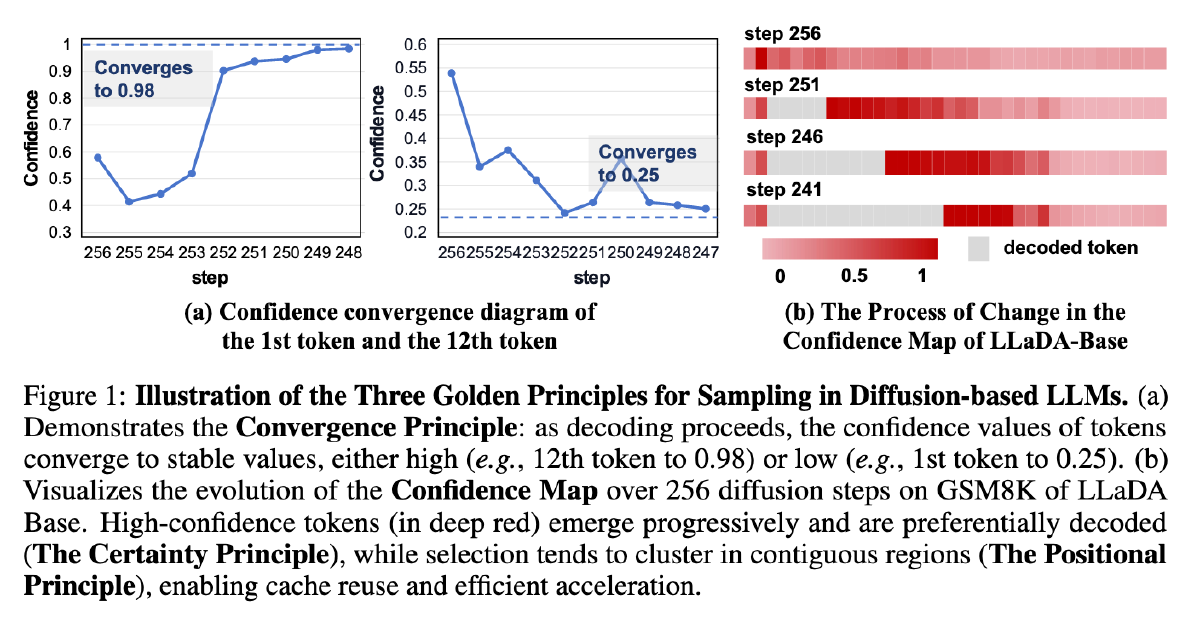
图 a 展示了随着 decoding 进行,token 的置信度逐渐收敛,要么越来越高,要么越来越低
图 b 展示了 LLaDA 在 GSM8K 上经过 256 步扩散过程中的置信度图谱变化,高置信度位置的 token 越来越多并被优先 decode、且这些 token 往往连续出现
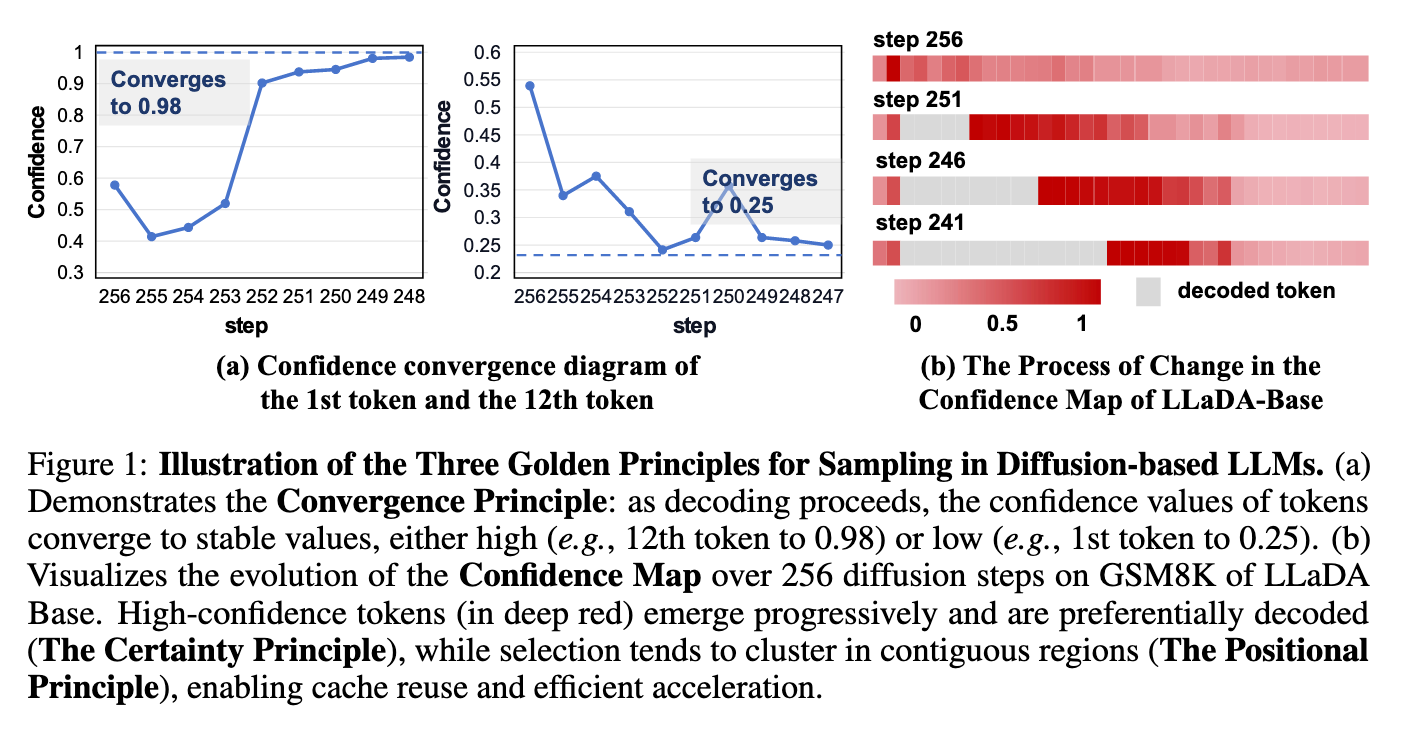
于是作者提出 3 个 Gold Principle:
| 原则 | 含义 | 意义 |
| 确定性 | 表现出更高置信度的token本质上更具确定性。因此,它们更有可能在解码过程的早期被正确解码,并且在后续的扩散步骤中需要较少的调整。 | 通过优先处理那些能够快速达到高置信度阈值的token,我们可以减少对序列中已确定部分的冗余计算。 |
| 收敛 | 随着扩散过程的展开和token的逐步优化,许多token的语义含义趋于稳定,其对应的置信度分数收敛至一个稳定值。这种收敛表明这些token已基本定型,几乎不需要进一步优化。 | 已表现出收敛性的token(即在最近若干步中具有稳定的标识和置信度)更不易发生变化。激进解码可避免不必要的重新评估,从而加快处理速度。 |
| 位置 | **即使没有显式的约束条件,模型的采样偏好通常也会倾向于出现在特定的、通常是相邻的位置上的token。这种固有的位置偏差可以被策略性地加以利用。例如,序列的部分内容可以有效地被缓存,从而带来显著的加速增益。** | 识别这些区域有助于实现有针对性的解码。无需均匀处理所有token,而是可以将计算资源集中在当前最易于解码的区域上。 |
方法#
还是 block 内并行,但是 block 之间是 ar
block 内部分为两阶段 dlm 解码,探索阶段(slow)和加速 decoding(fast)阶段
探索阶段#
- 小心解码:每一个 step,只 decode 出置信度最大的一个 token,一共执行 k(超参数)个 step
- 终点预测:每个 step 中,取出 block 内距离该 token 最远的、置信度高于 t_{min_conf}(超参数)的 token,并认为 dlm 可以自信地 decode 到这个位置
稳定性检查:多个 step 之间维护一个历史记录(保留最近 K_hist 条,也是超参数),用于记录最远的 token 的位置,如果最近 K_hist 个记录的方差小于 σ^2_stable,则认为稳定了,取历史记录的平均值作为最终确定下来的位置,并将 block 中从开始到此为止的所有 token 进入 Fast decoding 阶段
回退策略:如果最终没能达到稳定,则准备了两种回退策略来估计最终的终点:
- 保守区间回退(默认):还是取历史记录的平局值
- 全序列慢速解码(极端情况):不进入 Fast Decoding 阶段
加速 Decoding 阶段#
- 区域外缓存:对于上面计算出的终点外的 token,只计算他们一次,并将这些位置的计算结果 cache 下来
- 区域内并行解码:在区域内尝试激进的并行解码,同时解码所有置信度高于 t_{high_conf}(超参数)的 token
- 回退策略:如果没有 token 高于 t_{high_conf},则解码 top-k_fast(超参)的 token
实验#
模型:LLaDA 8B、Dream 7B
硬件:4090
超参数:
| 参数 | 值 | 含义 |
| t_{min_conf} | 0.1 | slow阶段终点预测时的置信度阈值 |
| t_{high_conf} | 0.85 | fast阶段并行解码的token的置信度阈值 |
| K | 8 | slow阶段探索步数 |
| k_hist | 2 | slow阶段保留的最终历史记录数 |
| σ^2_stable | 1.0 | slow阶段的历史记录方差阈值 |
| K_fast | 未汇报 | Fast阶段回退的并行解码top-k的k |
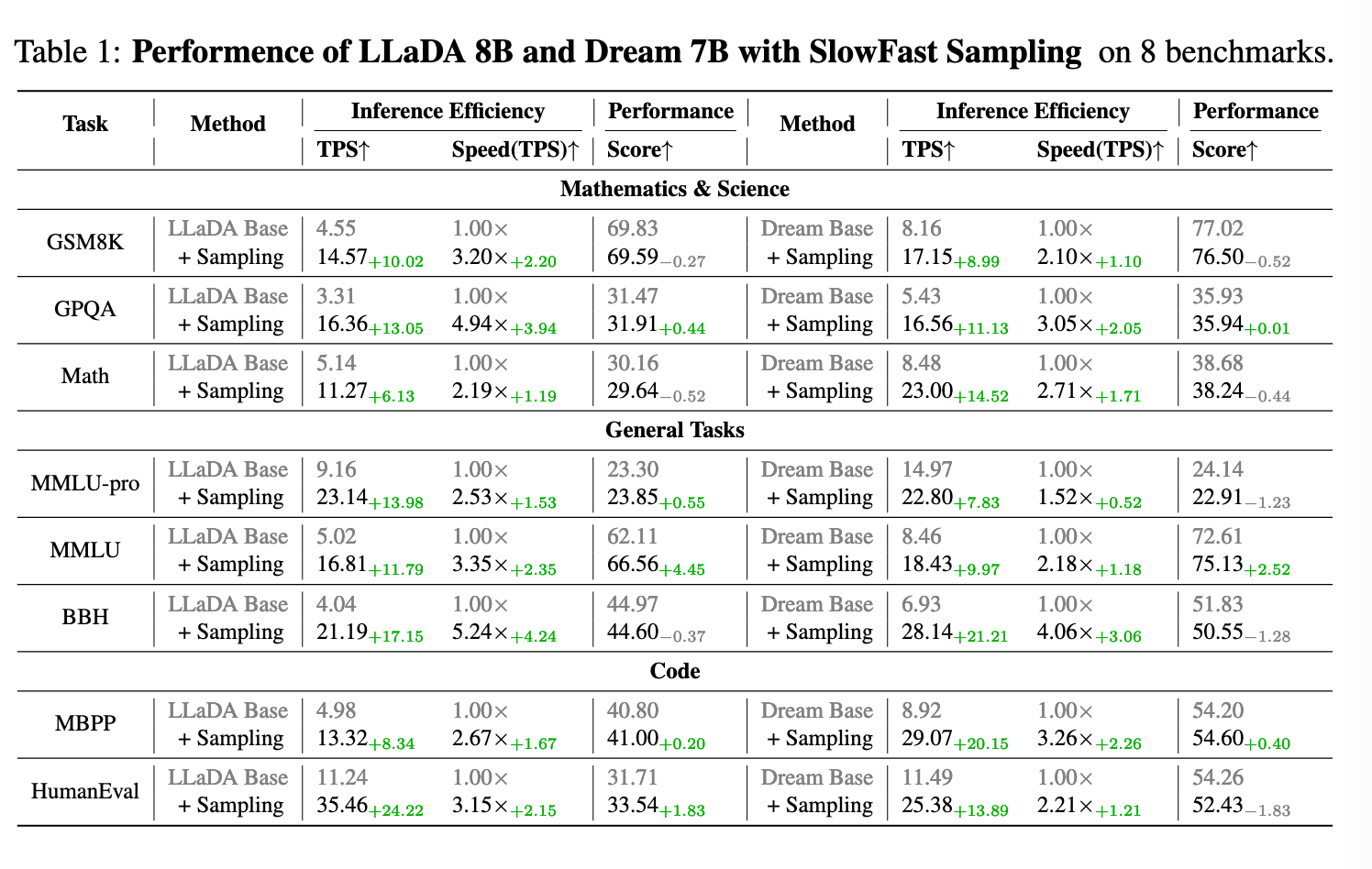
下图的 K_p 和 K_r 文章中没提到,应该是 Cache 的超参数