SoftCoT:Prompt➡️SLM➡️LLM#
SoftCoT: Soft Chain-of-Thought for Efficient Reasoning with LLMs
投机采样
摘要#
链式思维(CoT)推理使大型语言模型(LLMs)能够通过生成中间推理步骤来解决复杂的推理任务。然而,大多数现有的方法专注于硬 token 解码,这将推理限制在离散的词汇空间内,并且可能并非总是最优的。尽管最近的研究探索了连续空间中的推理,但这些方法通常需要对整个模型进行微调,并且容易遭受灾难性遗忘,从而限制了它们在零样本设置下已经表现良好的最先进的 LLM 中的适用性,尤其是在提供适当指令的情况下。为了解决这一挑战,我们提出了一种新的连续空间推理方法,该方法无需修改 LLM。具体来说,我们使用一个轻量级的固定辅助模型来投机性地生成实例特定的软思维 token 作为初始的思维链条,然后通过一个可训练的投影模块将这些 token 映射到 LLM 的表示空间中。在五个推理基准上的实验结果表明,我们的方法通过监督的、参数高效的微调提升了 LLM 的推理性能。
动机#
- 现有的 CoT 压缩或者连续 CoT 需要微调整个 model,一方面计算成本高,另一方面可能带来灾难性遗忘,并降低了模型通用性
- CCoT 和 Coconut 性能下降,推测可能对于 GPT-2 比较合适但是对于新模型效果不佳(SoftCoT 作者归因为灾难性遗忘)
为了避免灾难性遗忘,需要冻结 LLM 的参数,使用一个小型助手 model(ALM,Assistant Language Model)来辅助 LLM
方法#
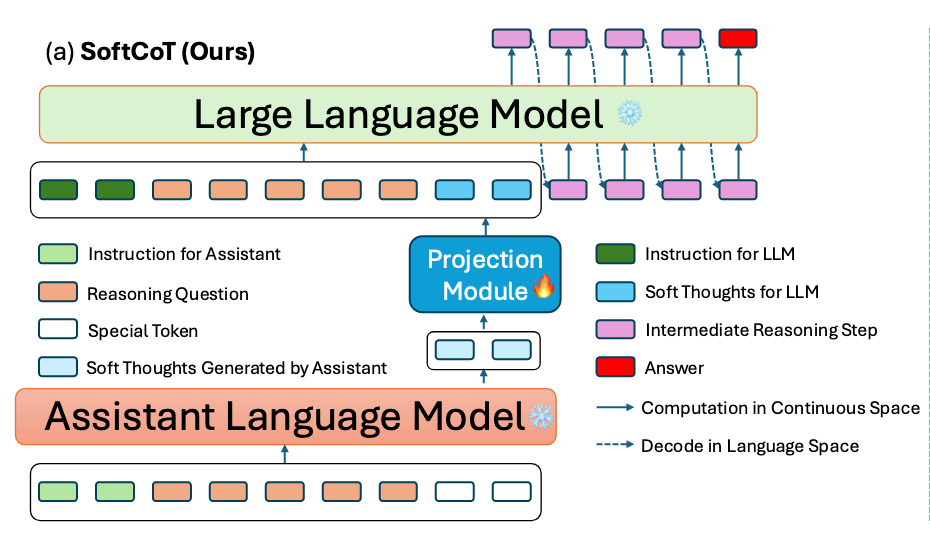
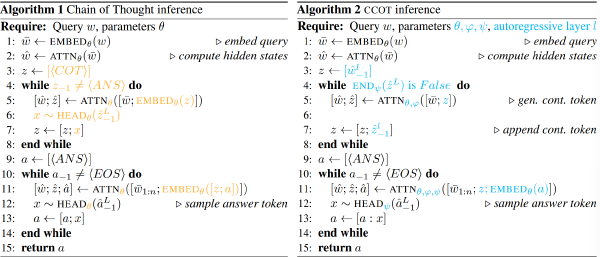
将 ALM 的 map 到词汇前的最后一层隐藏状态取出作为 SoftThought token,将 SoftThought Token 输入到投影模块,通过投影模块将其映射到 LLM 的 latent space(可以为不同任务训练不同的投影模块)
ALM 输入 X_assist 生成 Soft Thought Token,
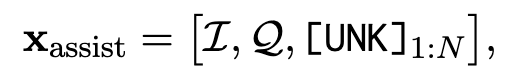
这三个分别是对于 ALM 的 Instruction、要推理的问题,以及 SoftThought Token 的占位符

h_assist 表示辅助模型的最终层隐藏状态,而 t_assist 是 N 个占位符被填充后的的 h_assist 片段。t_assist 作为 Soft Thought
将 t_assist 输入投影模块,得到 t
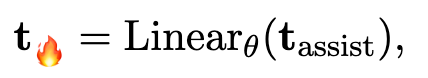
基于此,构建 LLM 的 input

分别是对于特定问题的固定的 instruction、要推理的问题、和投影出来的 t
实验#
数据集:GSM8K、ASDiv、AQuA、StrategyQA、Data Understanding
Baseline:
- Coconut(Meta 的连续空间推理)
- 零样本 CoT
- 零样本 CoT + 占位符(Pause Token)
- 零样本 Assist-CoT(使用 ALM 生成提示词来驱动 LLM)
模型选择:
- ALM 原文中并未提及具体选的哪个,但是在举例中选用 LLaMA-3.1-1B-Instruct
- LLM 分别选用 LLaMA-3.1-8B 和 Qwen2.5-7b
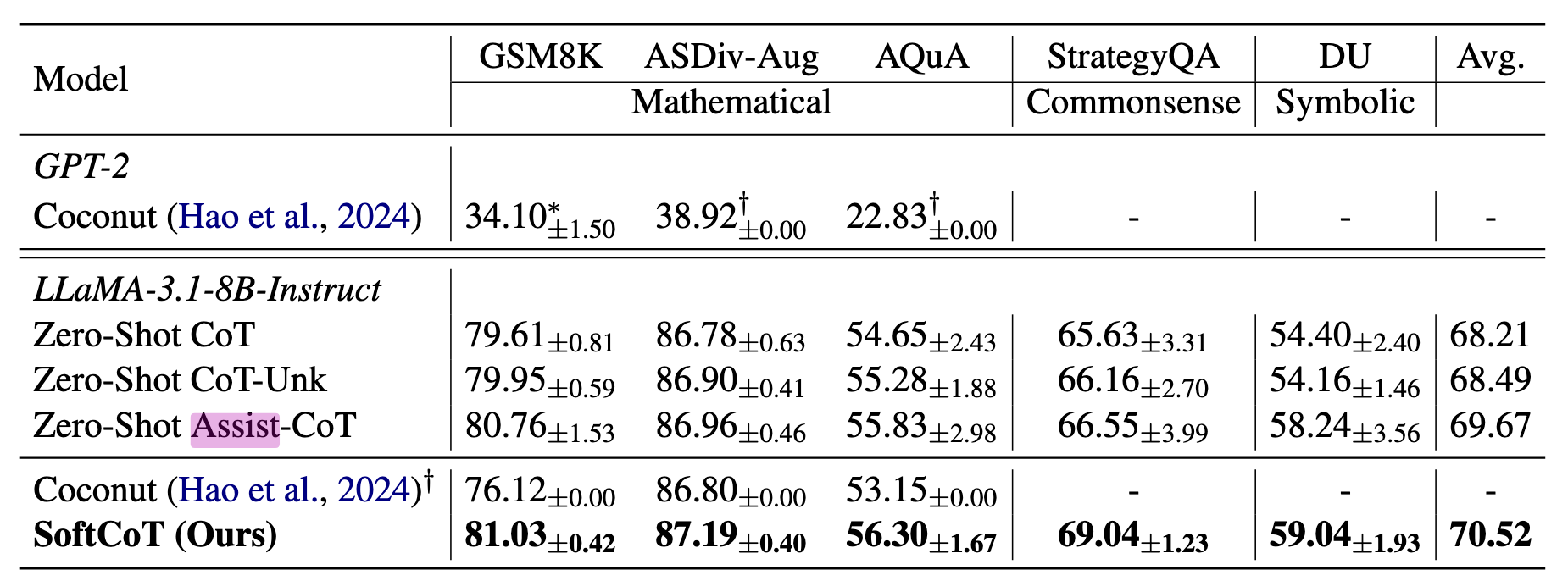
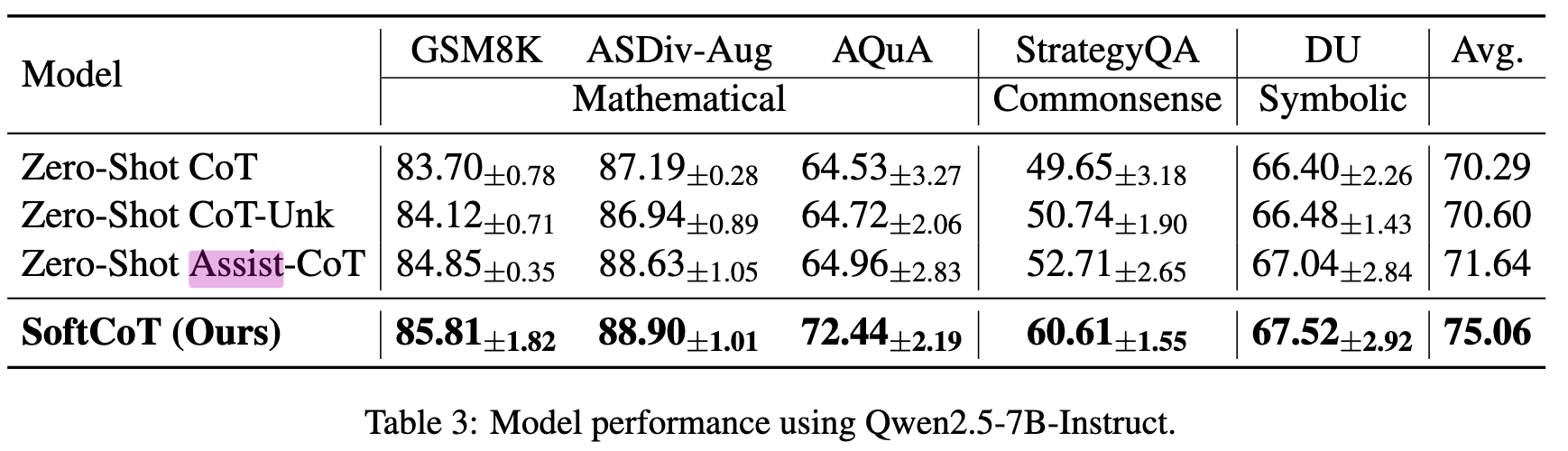
思考#
这篇文章有些胜之不武,两个 model 加起来参数量也大,token 也多,计算时间也久,效果要是还差那就奇了怪了,但是对此我也有一些思考
能否省去 LLM 的 Reasoiong Question,将投影模块的 output 作为初始 hidden state(属于对 input 进行压缩)- 能否和 LightThinker 结合,输入 SoftToken 以后采用 LightThinker 的方式进行 CoT 压缩,能否提高 LightThinker 的 Acc?(待实验验证)
- 或者更进一步,就设计一个 LLM 在正常推理,但是不定期将其推理的隐藏状态取出放到 Input 并重新推理?不定期可以是设计一个二分类器或直接像 LightThinker 按照句子或段落?