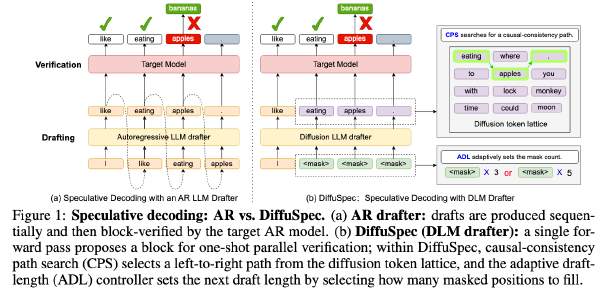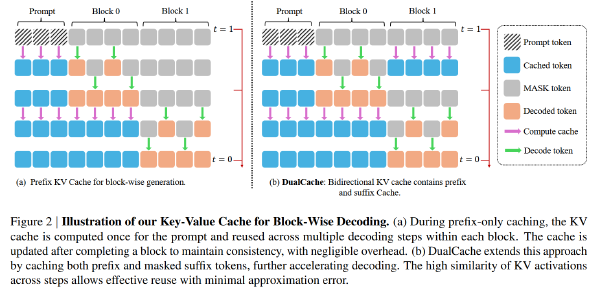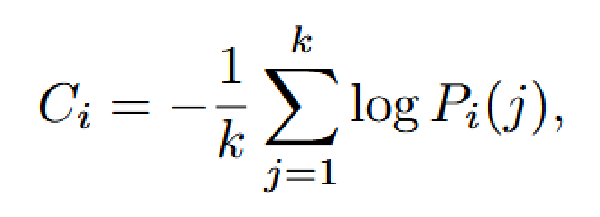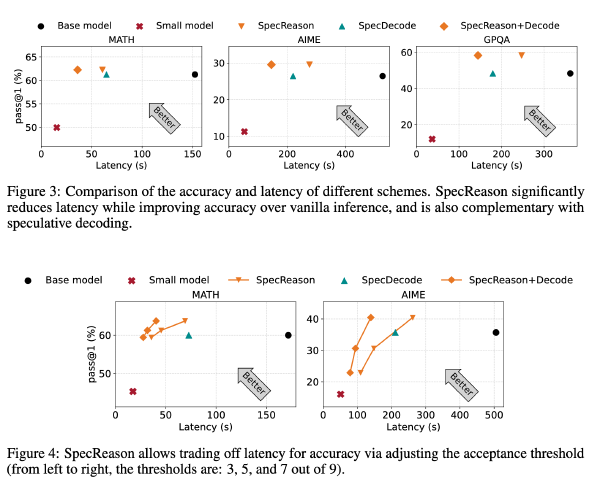
SpecDiff:使用扩散模型作为 Draft 模型#
Speculative Diffusion Decoding: Accelerating Language Generation through Diffusion
摘要#
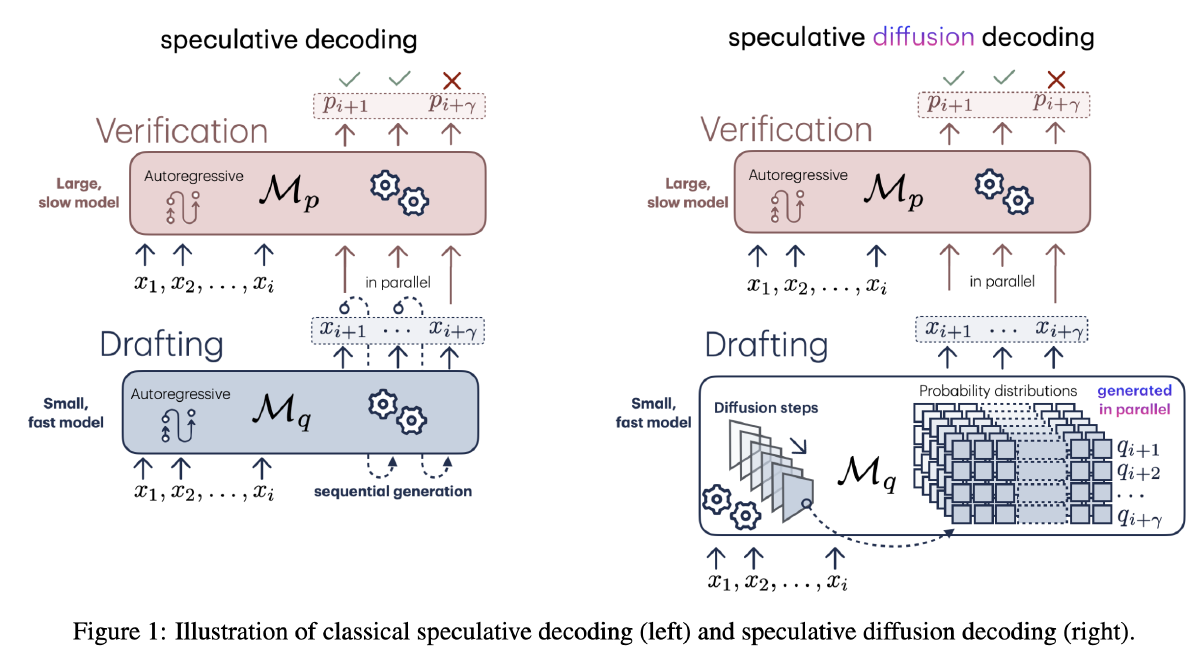
推测解码已成为一种广泛采用的方法,可在不牺牲模型输出质量的前提下加速大语言模型的推理过程。尽管该技术通过实现并行序列验证显著提高了生成速度,但其效率仍受限于现有 Draft 模型中对逐个 token 生成的依赖。为克服这一限制,本文提出了一种改进的推测解码方法,该方法使用离散 Diffusion 模型生成草稿序列。这使得 Draft 生成和验证两个步骤均可并行化,从而显著加快推理过程。我们提出的方法——推测扩散解码(Speculative Diffusion Decoding,SpecDiff),在标准语言生成基准任务上进行了验证,实验证明其相比标准生成方法可实现最高达 7.2 倍的加速,相比现有推测解码方法最高可达 1.75 倍的加速。
动机#
- 已有的加速投机采样的研究主要集中在引入额外的并行化技术,然而,生成效率的提升是以每次生成所需的操作数量和/或内存的显著增加为代价的。
- 作为 Draft 模型,Diffusion 模型在速度和质量上取得了一个平衡
- 且使用 Diffusion 模型作为 Draft 模型,可以实现 Draft 的并行化
- 先前的研究让大家先入为主认为 Target 和 Draft 模型应当是同系列模型,而本文提出质疑
- 投机采样需要精调超参(比如 Draft 生成的 token 数),但是如果使用扩散模型作为 Draft 就对于这个超参精度要求没那么高,因为其生成都是并行的,所以调大了损失不大
方法#
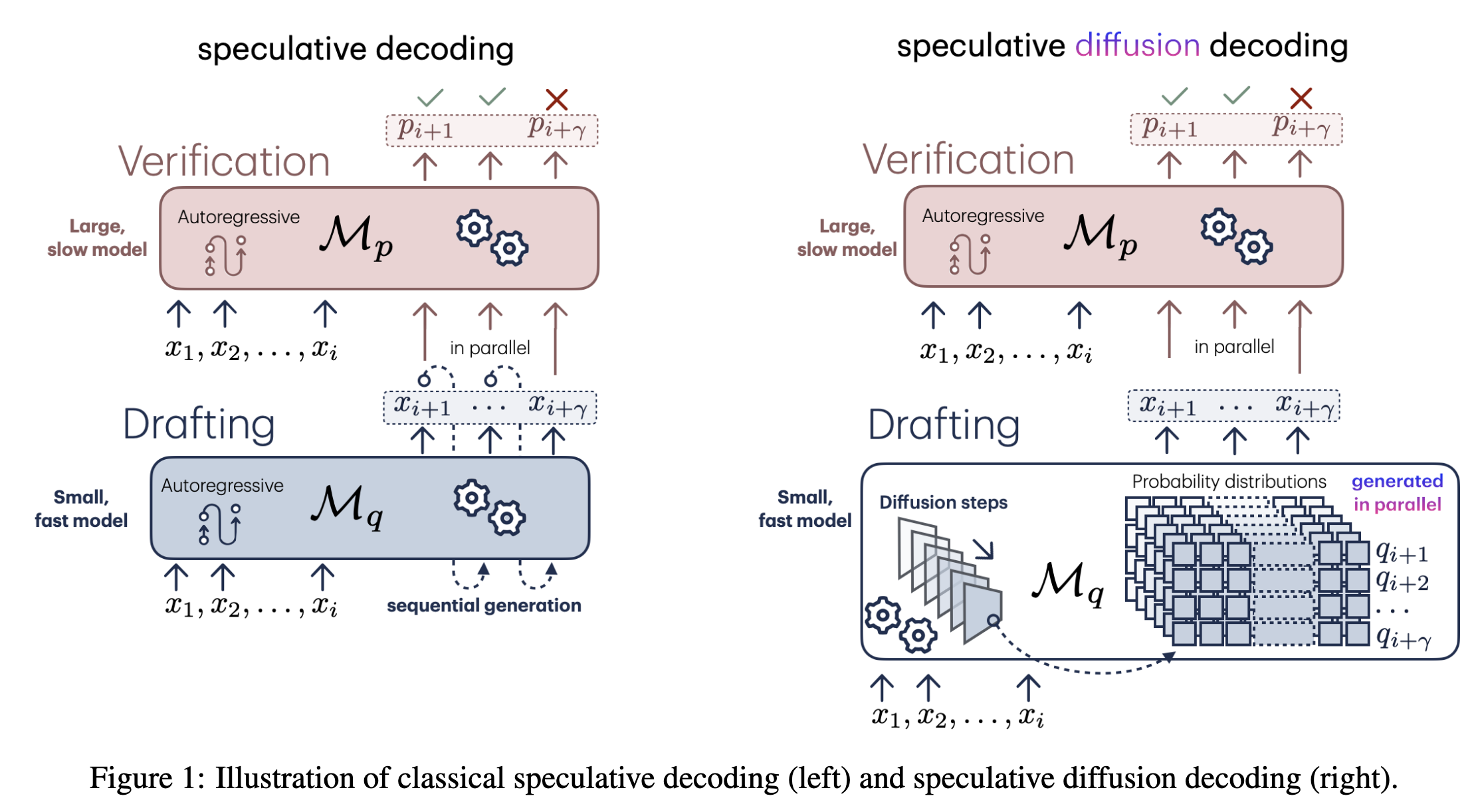
方法比较常规
- 当 diffusion 模型降噪 T 步生成 draft
- 用 Target 获得所有 token 概率
- 按照投机采样的方式接受 or 拒绝 token

- T 次去噪,生成 gamma 个 token
- 使用 Target 进行 Verify
- 进行标准的投机采样,找到第一个 reject 的位置 n
- 如果未全部 accept,则直接输出
- 否则,对于第 n+1 个位置从调整后的分布中采样一个 token,并回到第一步
调整分布的方法:
设 Target 的分布为 P(x)={A:0.6, B:0.3, C:0.1},Draft 的分布为 Q(x)={A:0.4, B:0.5, C:0.1}
Draft 输出的 B 被 Target 拒绝,并从 max(0, P(x)-Q(x))={A:0.2, B:0, C:0}
这样做的目的是防止 B 再一次从 P(x)里被取样出来,导致效果不佳
但是可能会有一个问题
由于 Diffusion 和 Autoregressive 模型大概率不是同一个系列的模型,他们的概率分布可能有较大差异,因此作者又引入了一个方法,即对最初的几个 Token 采用标准的投机采样,从而在一开始就优化了 SpecDiff 的性能
实验#
数据集:CNN/DM(文本总结)、OpenWebText(文本生成)、MT Bench(文本生成)
采样策略:Greedy,nums_of_tokens = 1024
模型:
Target:GPT-2 XL(1.5B)、GPT-Neo(2.7B)、Vicuna(33B)
Draft:
- Ours: Masked Diffusion Language Model(MDLM,110M)
- Baseline: GPT-2 (86M)
硬件:A100(80G,CUDA 12.2)
应用了 FlashAttention
Draft 一次生成 gamma 个 token 后再交给 Target 检查
$$ \alpha=\frac{Draft被接受的token数}{Draft总token数} $$看上去相比较于标准的投机采样,只实现了 1.5x 左右的加速
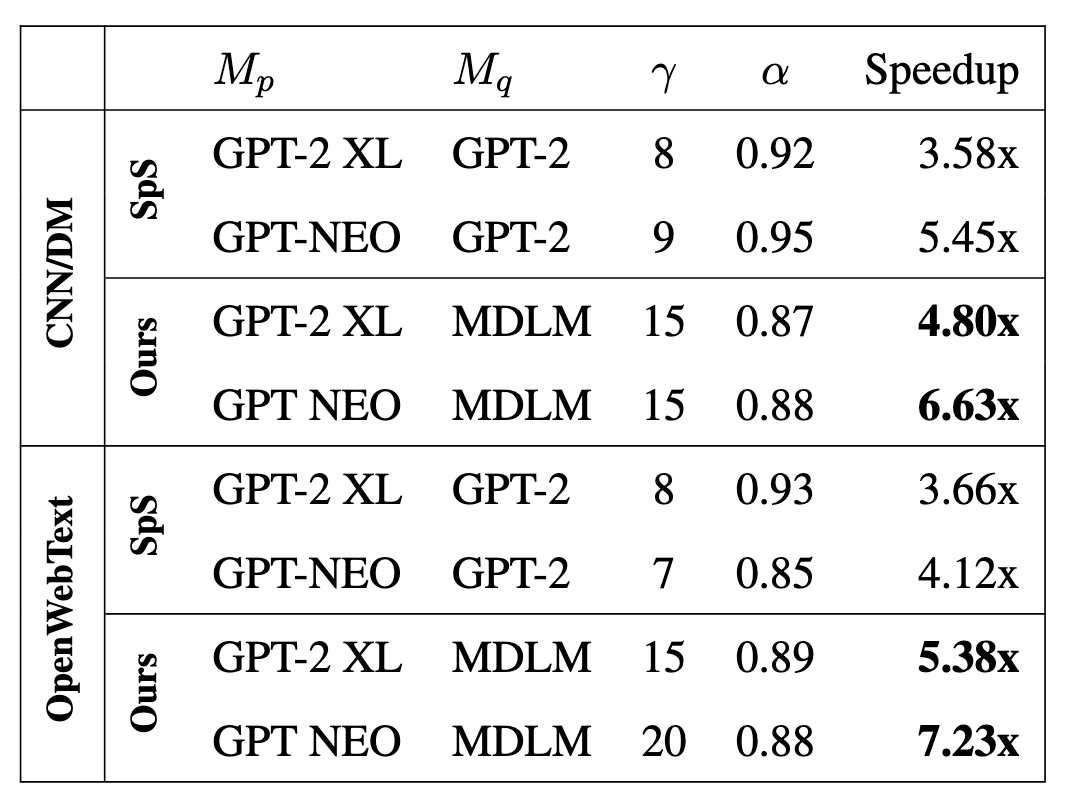
下图中的 Task Speedup 是模型在对应数据集上的加速效果,Overall Speedup 是在所有 Spec-Bench (Xia et al., 2024) tasks 上测量的平均成绩

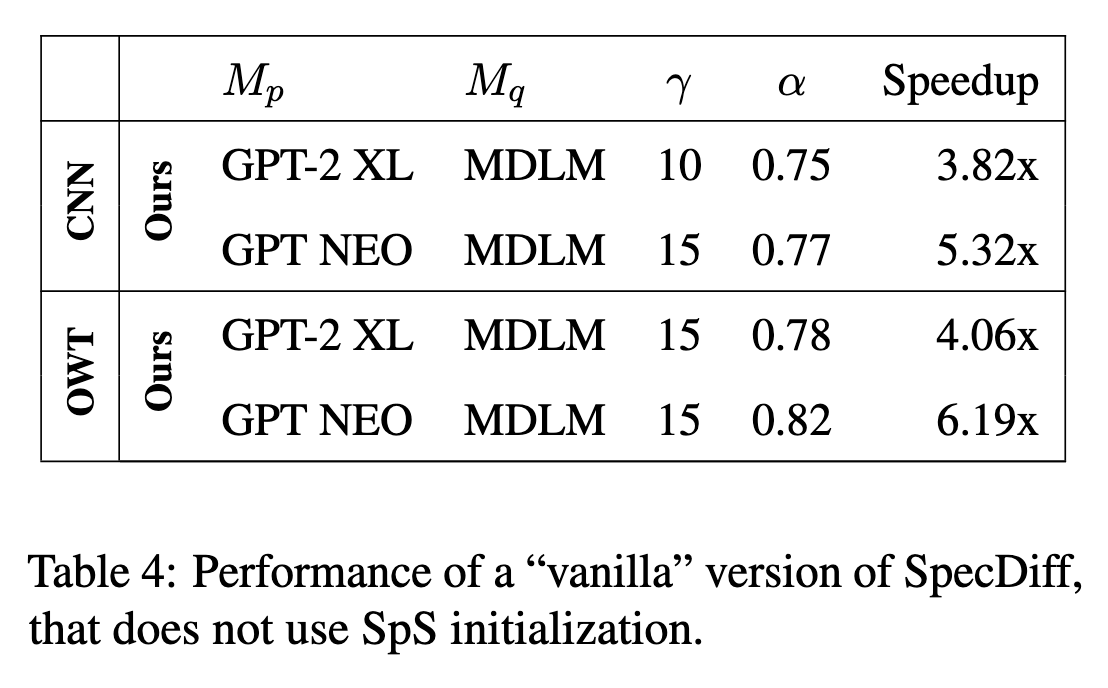
如果不在初始阶段先进行几个 token 的投机采样,速度会有些微的下降
Limitation#
- Diffusion 经常过于自信,导致对选中的 token 的概率过高(尤其是 temp>0 的情况下),容易导致 reject。需要想办法对齐 Diffusion Draft 和 Target 的概率
- 在短序列生成任务中效果并不明显