SpecReason:使用推测性推理实现加速推理#
SpecReason: Fast and Accurate Inference-Time Compute via Speculative Reasoning
摘要#
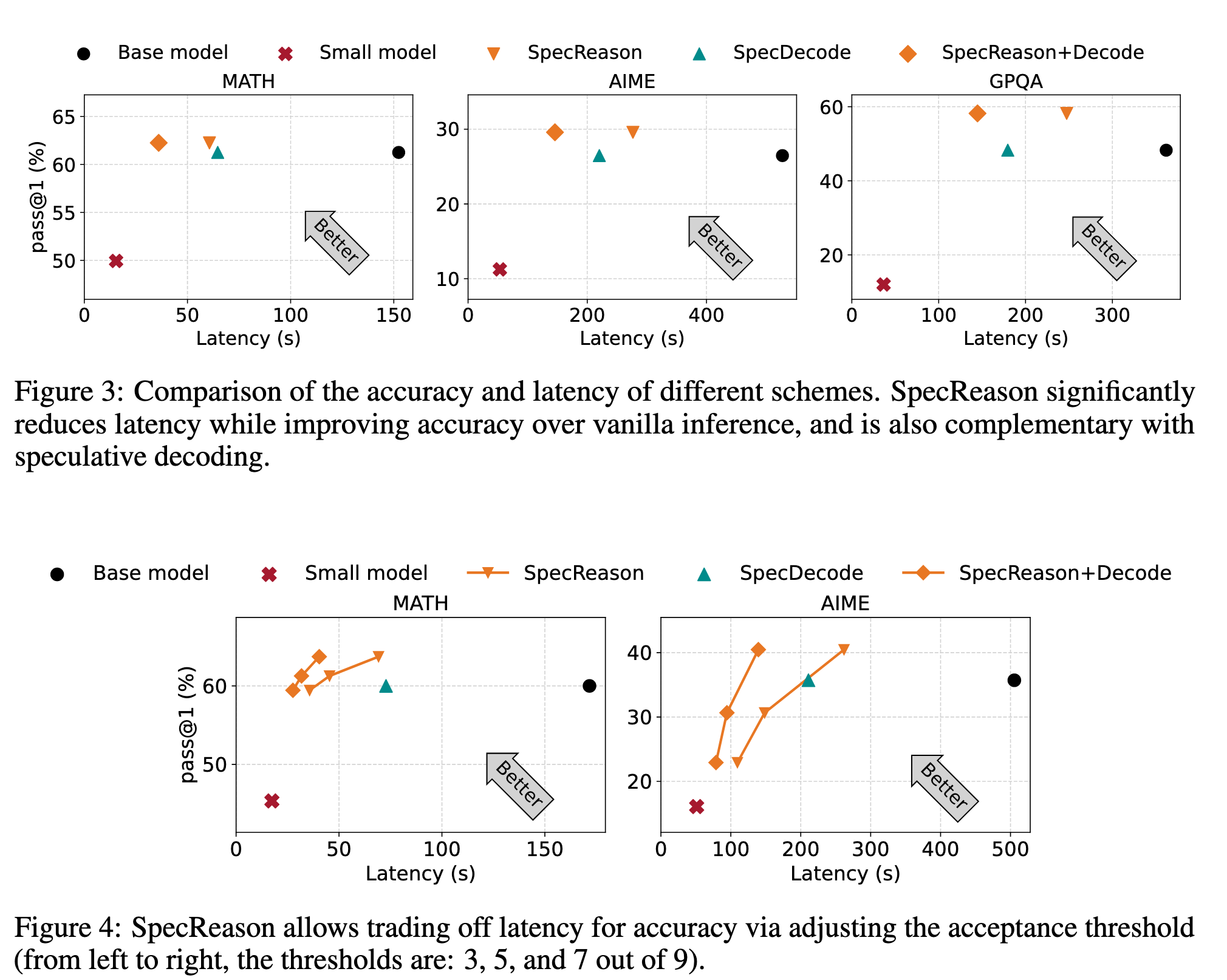
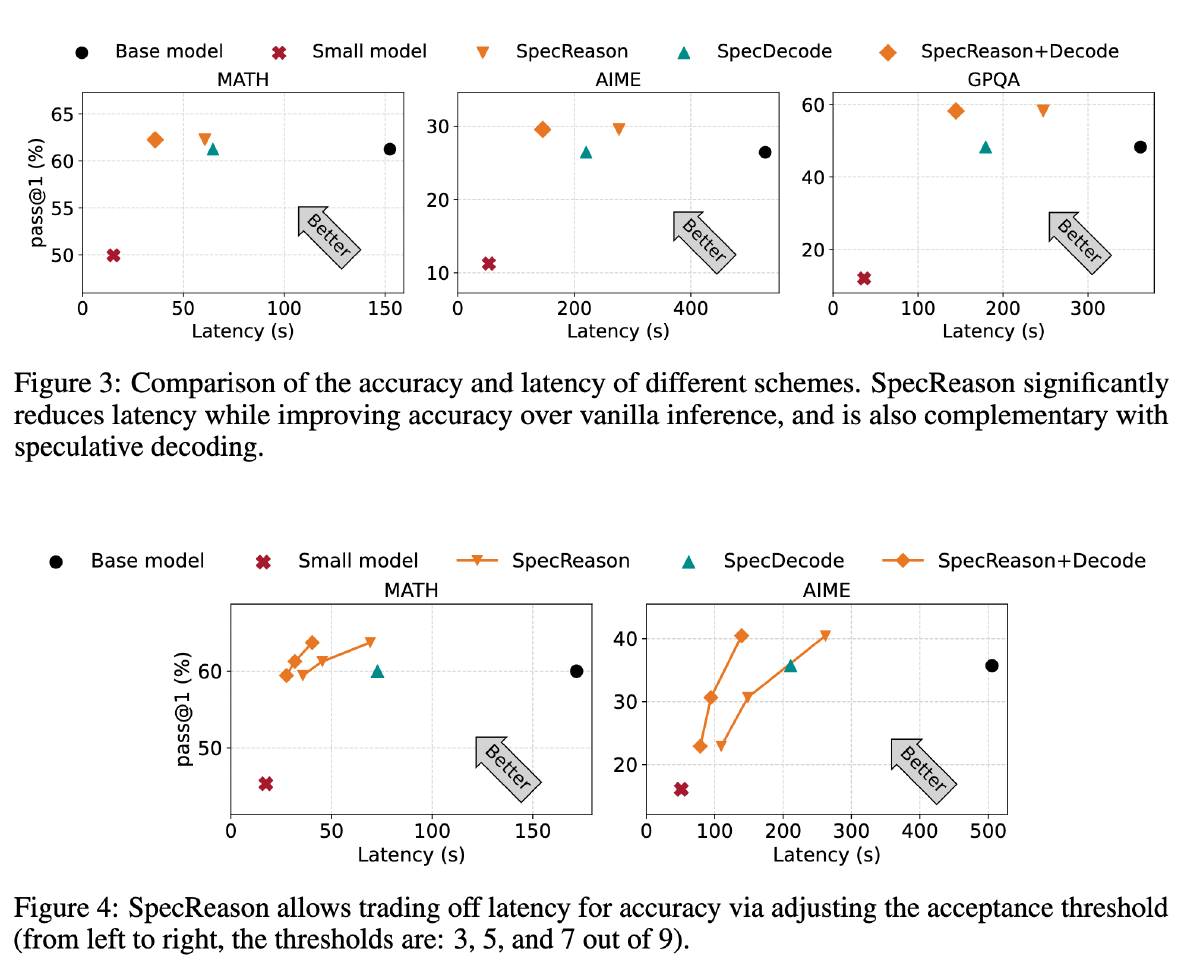
CoT 效果好但是带来巨大开销。我们解决这些开销的关键洞察是,LRM 推理及其嵌入的推理对近似的容忍度很高:复杂的任务通常被分解成更简单的步骤,每一步都基于它为下游步骤提供的语义见解带来效用,而不是它生成的确切 token。因此,我们引入了 SpecReason,这是一个利用轻量级模型自动加速 LRM 推理的系统,该轻量级模型(推测性地)执行更简单的中间推理步骤,并仅保留昂贵的基础模型来评估(并可能纠正)推测输出。重要的是,SpecReason 专注于利用思考 token 的语义灵活性以保持最终答案的准确性,这与先前的推测技术是互补的,特别是推测性解码,后者要求每个步骤的 token 级别等价。在各种推理基准测试中,SpecReason 比普通的 LRM 推理实现了 1.5-2.5 倍的速度提升,同时将准确性提高了 1.09% 至 9.9%。与没有使用 SpecReason 的推测性解码相比,它们的结合额外降低了 19.4%-44.2% 的延迟。我们在 https://github.com/ruipeterpan/specreason 开源了 SpecReason。
动机#
中间步骤实际用不了那么多计算(SLM 也能胜任)#
在长 CoT 中的许多推理步骤中,推理任务的难度并不是均匀分布的。虽然整体任务对于小型模型来说可能具有挑战性,但只有少数关键推理步骤(例如,分析问题,通过公式或案例分析将其分解,以及制定逐步推理问题的计划)对整体推理进展至关重要,而其他许多推理步骤则相对容易。
推理的进展依赖于洞察力,而不是确切的 token(对于同一个思路表述不一也问题不大)#
推理步骤的作用不在于确切的 token,而更多在于它在语义上多能推动推理过程继续。传统 LLM 推理中的翻译等任务中忠实于确切的 token 组合更为重要,而在 LRM 的思考 token 中的推理 CoTs 更关心能够推进推理链的信息。对于给定的步骤存在一系列有效的表述:许多语义相同或语义相似的 token 序列可以起到相同的引导后续推理的功能。
偶尔的错误可以通过自我反思来纠正(SLM 出错了 LRM 可以修改过来)#
此外,LRM 表现出强大的自我反思能力。即使早期步骤中包含事实性或逻辑性错误,LRM 也常常能在随后的推理步骤中自我纠正,通常以输出如“Wait”或“Hmm”这样的 token 为标志。而且,由于在 LRM 推理中,只有最终 response 的 token 才计入准确性,LRM 推理可以容忍偶尔的错误,因为模型通常能够识别这些错误,并在自我反思过程中将推理引导回正确的路径。这种容错特性进一步表明了近似的潜在好处。
总之,LRM 推理本质上更能容忍 token 的近似,只要整体的推理轨迹得以保持即可。
方法#
推测性推理(Speculative Reasoning)#
让 SLM 进行推理,每一步(一个句子或一个自然段)都提示 LRM 生成一个 token 的 score 来评估步骤是否可以采纳,如果 score 比较低,就用 LRM 进行重新生成
实验#
模型:QwQ-32B(LRM)、R1-1.5B(SRM)
数据集:AIME、MATH500、GPQA
其他:pass@1,k=16, temperature=0.6 maxlen=8k
软硬件:vllm A6000(48G)
SpecDecode 是投机采样、SpecReason+Decode 是投机采样 + 本文方法,Fig3 中 score 阈值为 7