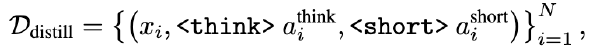
ThinkLess:一种无需训练的推理高效方法,用于减少推理冗余#
ThinkLess: A Training-Free Inference-Efficient Method for Reducing Reasoning Redundancy
摘要#
虽然链式思维(CoT)提示提升了大型语言模型(LLMs)的推理能力,但过长的推理 token 序列会增加延迟和 KV 缓存内存使用量,甚至在上下文限制下截断最终答案。我们提出了 ThinkLess,一种推理高效的框架,能够在不修改模型的情况下提前终止推理生成并保持输出质量。注意力分析表明,答案 token 对早期推理步骤的关注最少,而主要集中在推理终止符 token 上,这是由于因果掩码下的信息迁移所致。基于这一发现,ThinkLess 在更早的位置插入终止符 token,以跳过冗余推理同时保留底层知识传递。为防止早期终止导致的格式破坏,ThinkLess 引入了一种轻量级的后调节机制,利用模型天然的指令跟随能力生成结构良好的答案。无需微调或辅助数据,ThinkLess 在大幅减少解码时间和内存消耗的同时,实现了与完整长度 CoT 解码相当的准确率。
Motivation#
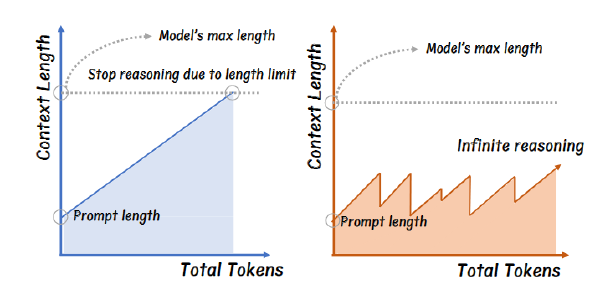
- 资源消耗
- 过长 CoT 效果可能反而不好
- 长 CoT 可能挤占最后生成答案的 token 数量
方法#
观察到现象#
注意力下沉,在早期层模型会关注整个推理过程,但是到了后面的层模型更多关注,因为包含整个推理的信息
基于上述现象,提出假设,在推理过程中,之前,存在一个 token,已经具备了足够的信息,在此 token 以后添加能在有足够的信息后终止思考。
验证假说#
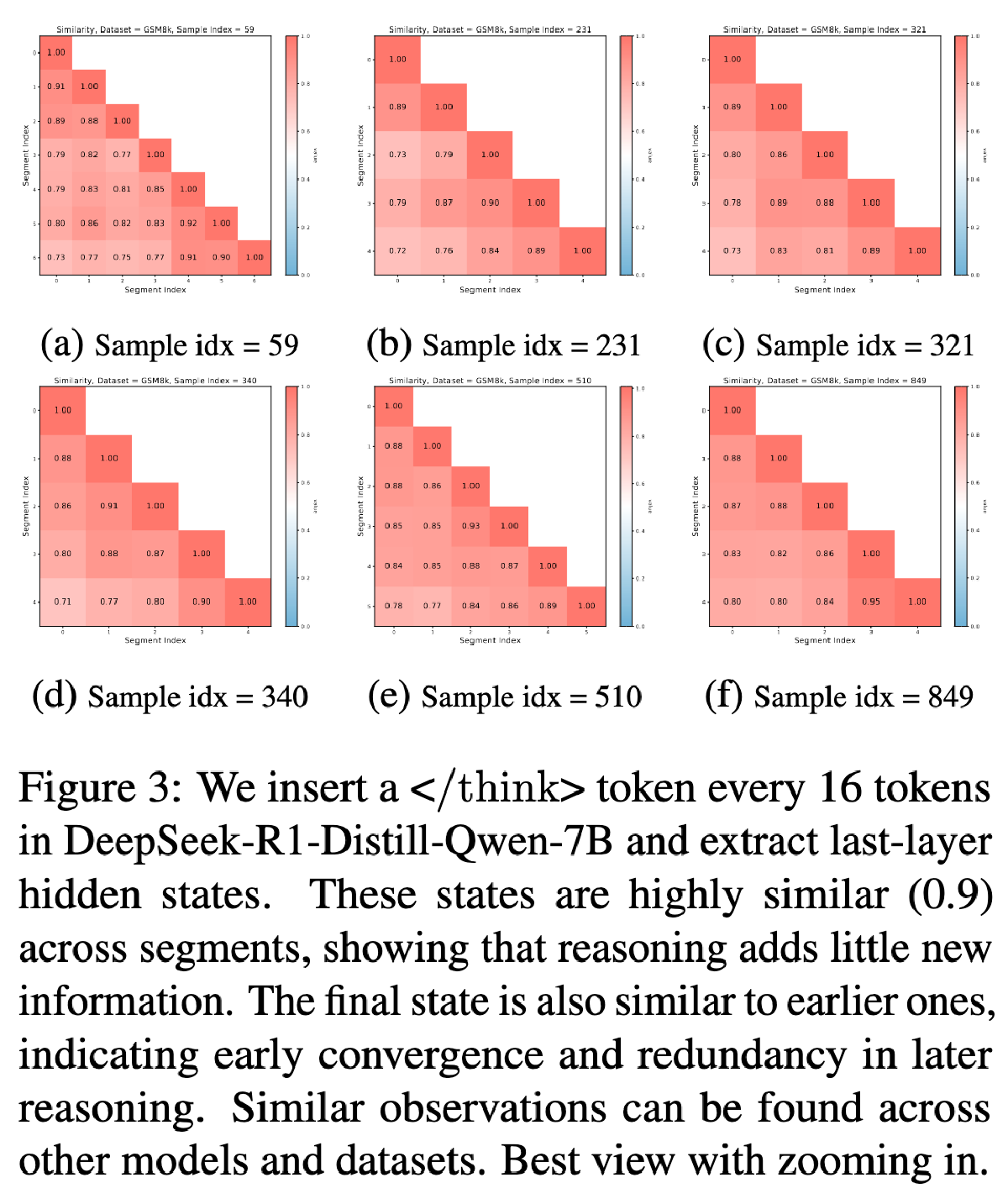
在 DeepSeek-R1-Distill-Qwen-7B 推理中每 16 个 token 的地方插入提前终止思考一次,并提取出的隐藏状态
然后计算各个隐藏状态的余弦相似性
发现这些相似性相似程度很高,可以认为后续就几乎没有新的有用信息加入了。
尝试在不同位置截断并看最终 Acc,发现尽管早期 hidden state 已经具备很多信息了,但是 Acc 还是很低,但是到了越往后越高 ⬇️。
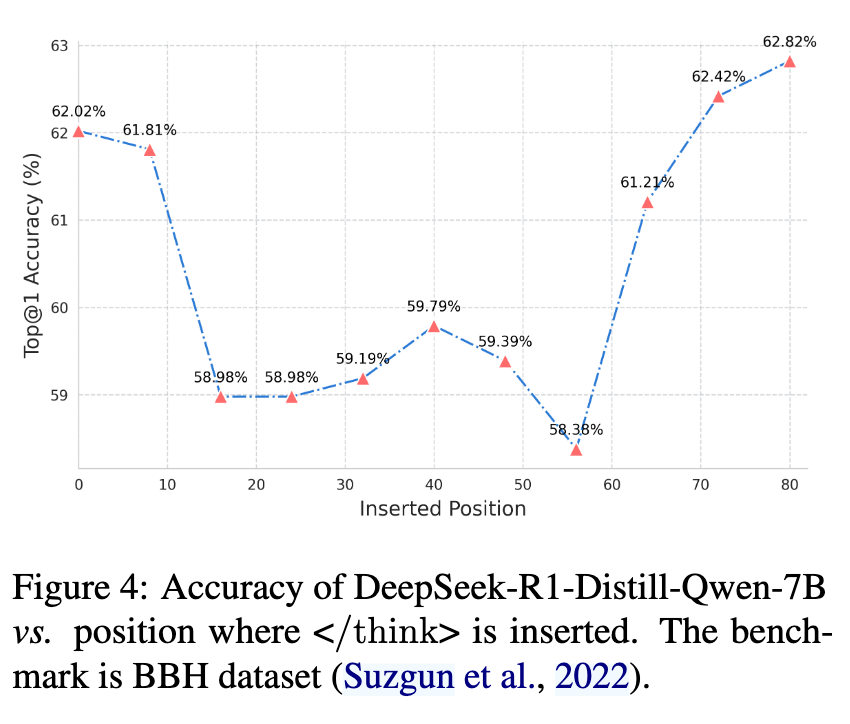
作者分析提到,在早期截断时,模型其实答对了,但是模型最后没能格式化,比如在 GPQA 上选择题,直接输出了选项内容但是没输出选项 ABCD,导致自动评分错误,对于这个问题,作者选择在写一段简洁的 prompt 拼在题目之前以限制模型的输出
实验#
数据集:GSM8K、MMLU、GPQA、BBH
模型:Qwen2.5-7B/14B、LLaMA3.1-8B
Baseline:上述模型蒸馏 Deepseek-R1 的变体,例如 deepseek-r1-distill-qwen-7b
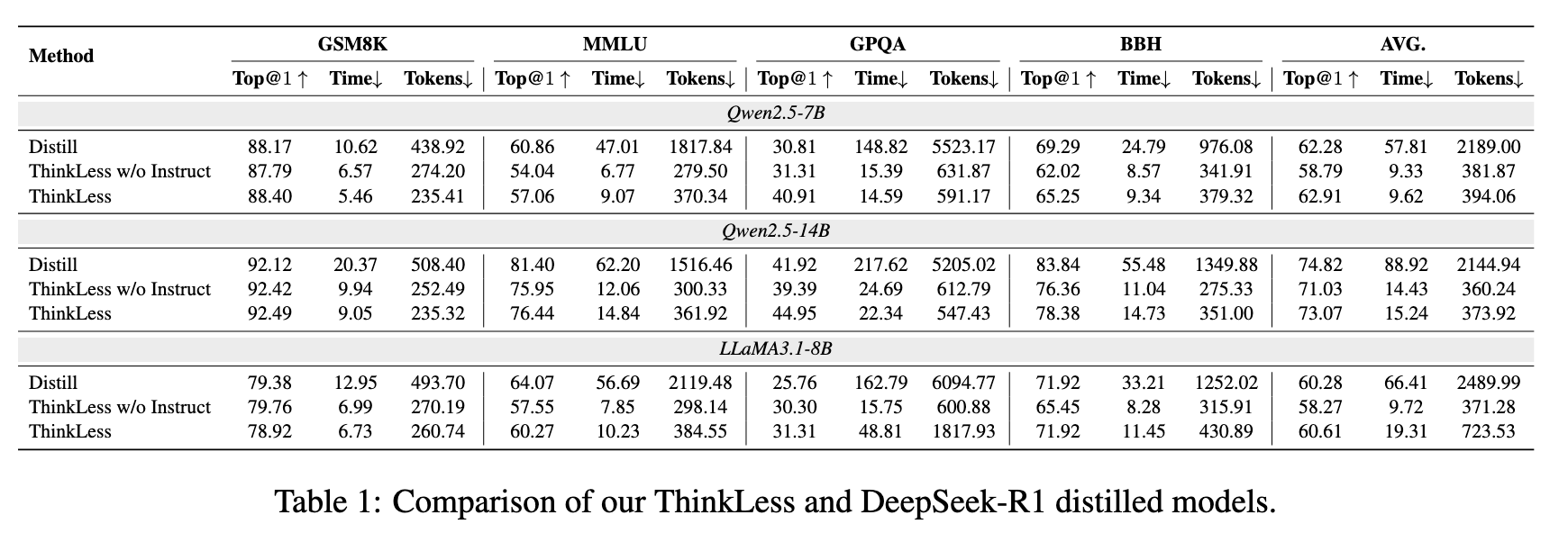
效果真的挺好的,基本上都是 ThinkLess 胜