Thinkless: LLM Learns When to Think#
Thinkless: LLM Learns When to Think
摘要#
推理语言模型(Reasoning Language Models),具备扩展的链式思维推理能力,在需要复杂逻辑推理的任务上展现了卓越的性能。然而,对所有查询应用详尽推理通常会导致显著的计算效率低下,尤其是在许多问题有简单解决方案的情况下。这引发了一个开放性问题:大型语言模型(LLMs)能否学会何时进行深度思考?为了解答这一问题,我们提出了 Thinkless,这是一种可学习的框架,能够使 LLM 根据任务复杂性和模型自身的能力,自适应地选择短形式或长形式的推理方式。Thinkless 在强化学习范式下进行训练,并使用两种控制 token:
Motivation#
- Long cot 效率低
- 已有的研究的模型推理与否受制于人类的先验知识,可能陷入次优,让模型自己决定才是正解
方法#
影响推理的因素#
- 用户问题的难度:形如 1+1=?的问题不需要推理
- 模型的能力:即使有些问题较难,但是如果模型能力上去了也不用过多推理
- 用户对于效率和准确性的容忍度
具体方法:#
用于预热的蒸馏#
目的:构建一个能生成 short 形式和 long 形式的模型
步骤:取一个 reasoning 模型和一个 instruct 模型,分别对于同一个问题进行回复,并在其回复前加上
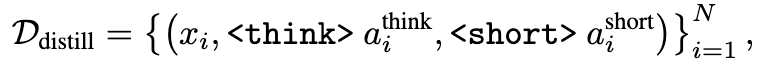
并使用该数据集 SFT,
为什么不把两个回复拆开呢? 或者是说训练的时候其实是分开训练的
让模型遇到
通过解耦的 GRPO 学习何时思考#
优化策略#
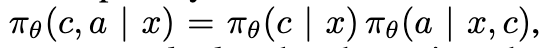
其中 c 要么是
奖励设计#
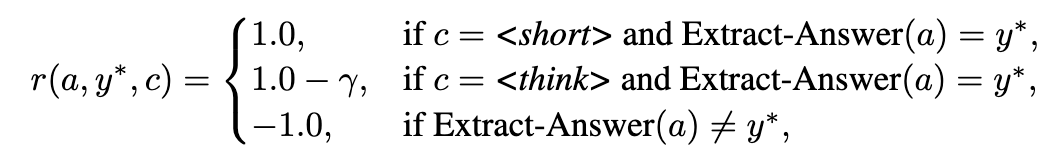
简言之,鼓励
解耦策略优化#
原 GRPO
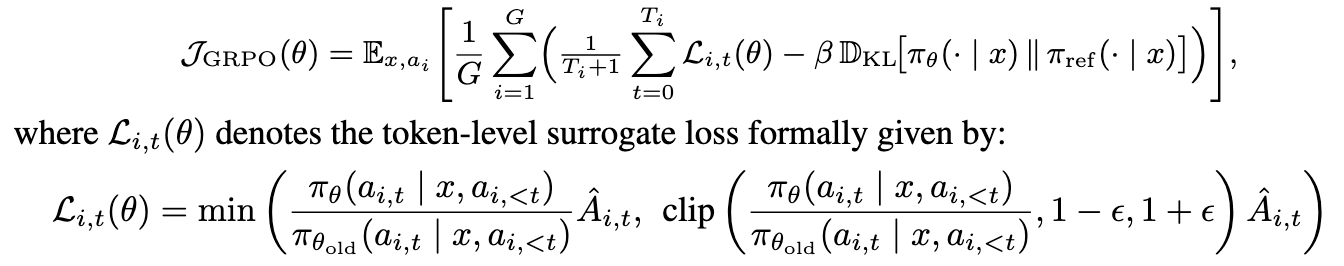
但是(1)模式-准确性不平衡 - 每条轨迹仅包含一个控制 token,而有 Ti 个响应 token,这不成比例地削弱了模式选择相对于响应准确性优化的影响。(2)长思-短思不平衡 - 更长的序列由于归一化因子 1/(Ti + 1)的存在进一步抑制了控制 token 的梯度贡献,导致
所以设计了新的策略
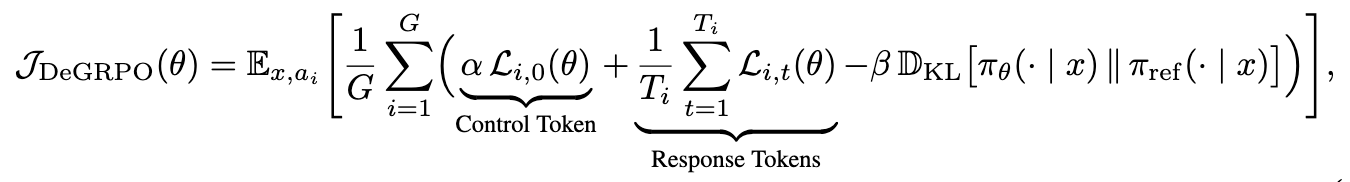
实验#
模型:DeepSeek-R1-Distill-Qwen-1.5B
数据集:AIME、Minerva Algebra、MATH-500 和 GSM-8K
使用 DeepSeek-R1-671B 和 Qwen2.5-Math-1.5B-Instruct 在 DeepScaleR 上分别生成 think 和 short
硬件:4 张 H100
超参:
生成数据集 max_len: 16k(长了截断),SFT 时调整到 24k
SFT 训了一轮,RL 训 600 步
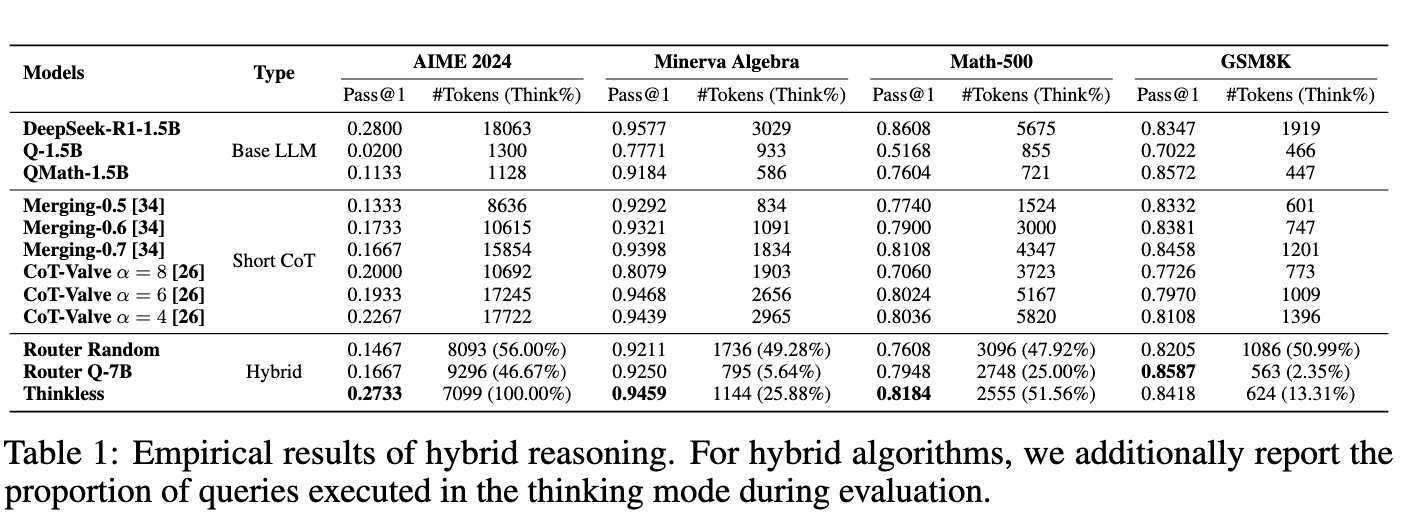
在 AIME 上大胜!