Token 预算意识的 llm 推理#
Token-Budget-Aware LLM Reasoning
摘要#
llm 使用推理更容易在各种任务上取得出色表现。但是像 CoT 这种推理方法会导致 token 开销的大幅增加,增加成本。作者发现当 llm 的推理过于冗长的情况下,可以通过在提示中包含合理的 token 预算来压缩(王新昀:更确切的说是减少推理输出),但是 token 预算的大小对于“压缩”效果上起着至关重要的作用。
作者提出了一种能够感知 token 预算的 llm 推理框架,这个框架根据每个问题的推理复杂度动态调整 token 预算的数量。
实验表明这种方法在 CoT 推理中有效降低了 token 的成本,但是也略微降低了性能。
Motivation#
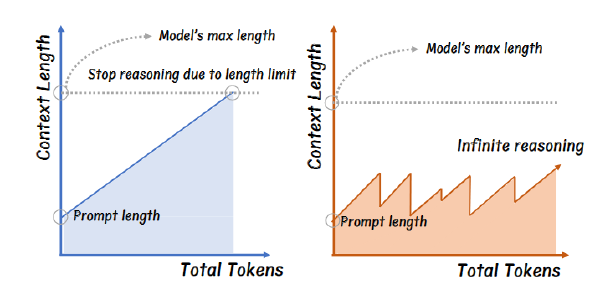
CoT 能显著提升 llm 性能,但是也产生了大量的额外开销,比如 token 数量的增加、延时增加等等,最终导致额外的金钱和能源消耗。
发现可以使用在 prompt 中声明 token 预算来是的 llm 按照 token 预算数量进行输出
你的问题 Let’s think step by step and use less than β tokens:




方法#
token 冗余现象#
- LLM 有能力遵循 prompt 中的长度约束
- 我们发现,提供合理的标记预算可以显著降低推理过程中的标记成本
- 在 post-training 阶段,例如 Ouyang 等人(2022)提出的 RLHF 过程中,标注者可能更偏好来自大型语言模型的更详细的响应,并将其标记为首选。
Token 预算搜索#
- 二分查找,使用二分查找的方式,找寻解决某个问题的最小 token 预算,isFeasible 实际上是在判断模型输出是否正确以及模型对于预算遵循情况

对于 token 弹性的观察#
我们发现如果预算降低到某个范围之外,token 成本会增加,这表明进一步减少预算会导致 token 消耗的增加。下图横轴代表搜索轮次,轮次越大,预算越小。不同颜色表示从 MathBench-College(Liu 等人,2024)中随机选取的不同样本。在合理的令牌预算范围内,令牌成本显著较低。当令牌预算小于合理范围时,令牌成本逐渐增加。
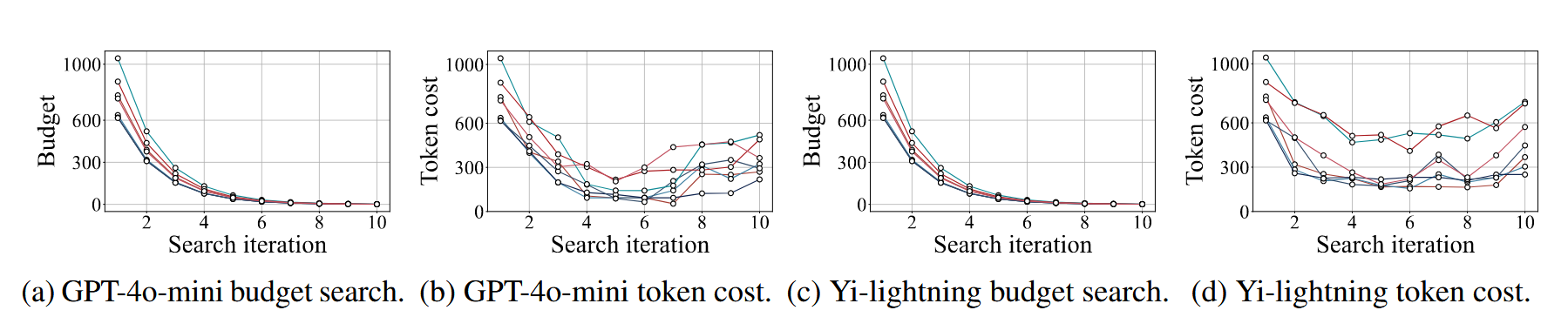
基于 token 弹性的搜索策略(修改了 isFeasible 函数,实际还是二分)#
isFeasible 同时检查模型输出是否正确 + 本次实际 token 是否小于上次 token

压缩 CoT 的方式#
Token 预算估计与 Prompt(TALE-EP)#
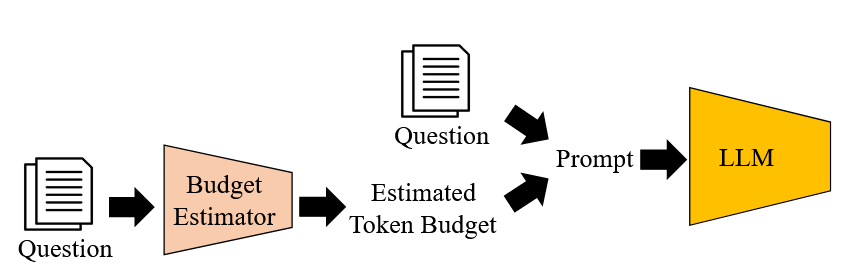
给定一个问题,TALE-EP 首先使用预算估计器估计 token 预算。然后,它通过将问题与估计的预算相结合,创建一个 token 预算意识的 prompt。最后,将提示输入到 LLM 中,生成答案作为最终输出。默认 llm 就是 budget 估计器。
token 预算意识的 prompt:

Post-training 的 token 预算意识内化(TALE-PT)#
对于预训练 llm 进行微调,使其具有 token 预算意识。这个过程分为两个关键阶段:目标输出生成和 LLM 后训练。
目标输出生成#
使用包含我们所搜索到的最优 token 预算的 CoT 提示,来激发 model 生成 y_i(回答)
最优 token 预算的 CoT 提示:

接着使用 y_i 来训练 model
基于 SFT 的内化#
构建数据集,数据集中包含原始的 x_i 和模型生成的 y_i
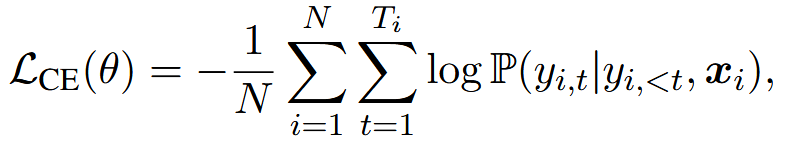
基于 DPO 的内化#
使用模型生成的 y_i 作为正样本,原版不带预算的 CoT 的 y_i_hat 作为负样本,正负样本对被用来创建 DPO 训练所需的双向偏好数据。
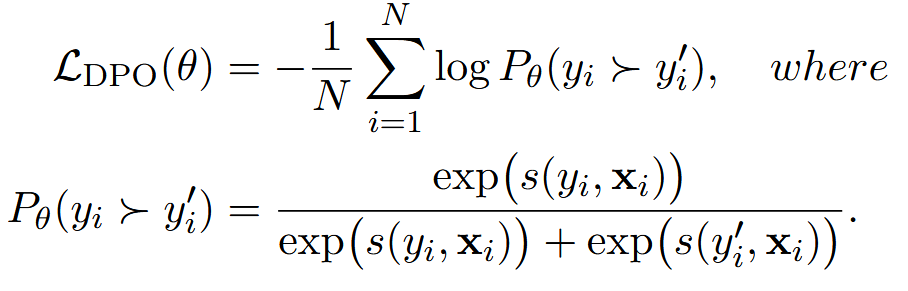
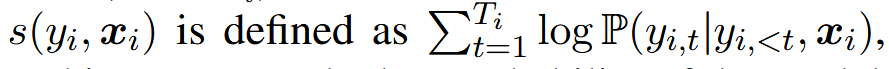
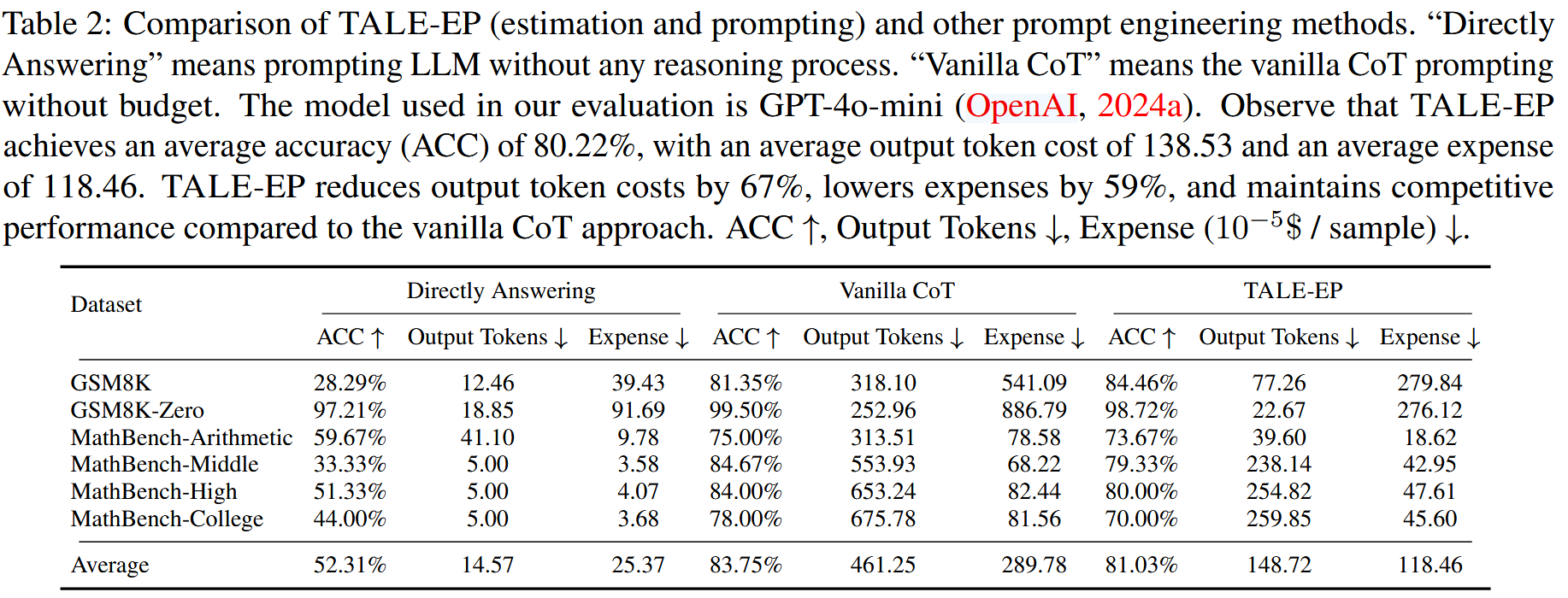
实验#
- 数据集:GSM8K、GSM8K-Zero、Math-Bench
GSM8K-Zero,源自 GSM8K 数据集,专门用于分析大型语言模型生成的输出中的过度推理和冗余。简而言之,GSM8K-Zero 的设计使得答案本身就内嵌于问题之中。大型语言模型可以轻松生成正确的回应,而无需复杂额外的推理或冗余的计算。
- 模型:GPT-4o、GPT-4o-mini、Yi-lightning、o3-mini、LLama-3.1-8B-Instruct
基于提示的#
- 4o-mini(问题越复杂,性能下降越多,但是 Output Token 下降更明显 + 花费更少)
- MathBench-College 数据集(对推理或非推理模型均有效)
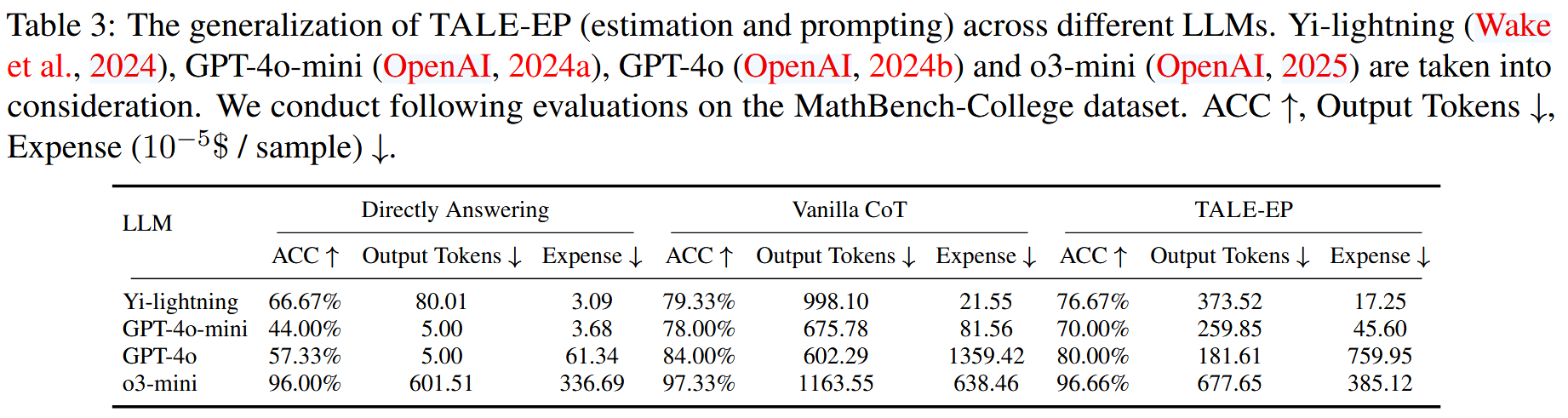
基于 post-training 的#
SFT 完胜 DPO,且 SFT 完胜原版 CoT(wxy:没说 SFT 的训练数据是基于哪个数据集构建的 +baseline 没有做过其他 SFT)

我的思考#
设计一个数据集,每条格式如下:
问题 token 预算 推理 回答
进行 SFT,在推理阶段使用 Bert 预测 token 预算,并作为输入
类似 TokenSkip