TokenSkip:可控的 CoT 压缩 in LLMs#
TokenSkip: Controllable Chain-of-Thought Compression in LLMs
摘要#
链式思维(CoT)已被证明能够有效提升大型语言模型(LLMs)的推理能力。如 OpenAI 的 o1 和 DeepSeek-R1,表明在推理过程中增加 CoT 序列的长度可能进一步提升 LLM 的推理性能。然而,由于 LLM 解码的自回归特性,较长的 CoT 输出导致推理延迟线性增加,从而对用户体验产生不利影响。为此,我们分析了 CoT 输出中 tokens 的语义重要性,并揭示了它们对推理的贡献各不相同。基于这一洞察,我们提出了 TokenSkip,这是一种简单但有效的方法,允许 LLMs 有选择地跳过不太重要的 tokens,从而实现可控的 CoT 压缩。在各种模型和任务上的广泛实验表明,TokenSkip 在减少 CoT tokens 使用的同时,能够保持较强的推理性能。值得注意的是,当应用于 Qwen2.514B-Instruct 时,TokenSkip 在 GSM8K 上将推理 tokens 减少了 40%(从 313 减少到 181),且性能下降不足 0.4%
https://github.com/hemingkx/TokenSkip
Motivation#
已经有一些研究探讨了选择性跳过推理步骤的方法,但是这种方法可能会损害 llm 性能,因此在效率和性能中找一个平衡点。
Contributions#
- 首个研究通过跳过 Token 来提升 CoT 效率的潜力,灵感来自于 LLMs 的 CoT 轨迹中令牌的不同语义重要性。
- 引入了 TokenSkip,这是一种简单而有效的方法,能够使大型语言模型在链式推理中跳过冗余的标记,并学习关键标记之间的捷径,从而实现可调比例的链式推理压缩。
- 实验验证了 TokenSkip 的有效性。当应用于 Qwen2.5-14BInstruct 时,TokenSkip 在 GSM8K 上将推理令牌减少了 40%(从 313 减少到 181),且性能下降不到 0.4%。
背景#
Token 重要性#
CoT 输出的每个 Token 对得到答案的贡献是不对等的,且 Token 的冗余已被认定为大型语言模型效率的一个长期且根本性的问题(Hou et al., 2022; Zhang et al., 2023; Lin et al., 2024; Chen et al., 2024)。Selective Context(Li et al., 2023)提出了一项研究,删除冗余的输入的 token 以减少 API token 的使用,并且这项研究提出了衡量 token 重要性的公式\(I_1(x_i)=-\log{P(x_i|x_{
LLMLingua-2(Pan et al., 2024)认为上述测量存在两个主要局限,阻碍了压缩性能:
- LLM 困惑度的内在特性导致处于句子末尾的 token 重要性度量较低
- 因果语言模型中的单向注意力机制可能无法捕捉文本中 token 重要性所需的所有关键信息
为了应对这些限制,LLMLingua-2 引入了利用双向 BERT-like 语言模型(Devlin et al., 2019)进行 token 重要性测量。它使用 GPT-4(OpenAI, 2023)将每个 token 标记为“重要”或“不重要”,并以 token 分类为目标训练双向语言模型。token 重要性通过每个 token 的预测概率来衡量。 \(I_2(x_i)=P(x_i|x_{\le n};\theta_{MB})\)其中 MB 表示双向语言模型。其计算出的效果如图中的第二个 CoT 版块。
作者最终采用 LLMLingua-2 来计算 LLM CoT 的重要性
Token 重要性计算效果:

CoT 恢复#
使用 LLaMA-3.1-8B-Instruct 将压缩后的 CoT 恢复为可读文本
方法#
TokenSkip 通过从原始 LLM CoT 轨迹中修剪不重要的标记,构建具有不同压缩比的压缩 CoT 训练数据。然后对 LLM 进行基础的 SFT
Token 剪枝#
先计算整个 CoT 文本的所有 token 的重要性,然后仅保留前百分之 γ 重要的 token(不打乱顺序)
训练#
取一个给定的有 N 个样本的数据集 D 和 LLM M,使用 M 在 D 上获取 N 个 CoT trace,删除答案错误的 treace,并采用 Token 剪枝的方法来修建 CoT,并且在 D 中每个问题的最后插入压缩比 γ,得到了一个新的数据集,每个样本格式如下:
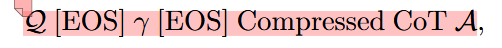
EOS 指什么没读到,可能是个特殊 token 或标记。具体而言,上述样本的格式为:问题、EOS、压缩率、EOS、压缩过的 COT、答案(答案并不被压缩)
在使用新数据集取微调 M,Loss 定义如下:
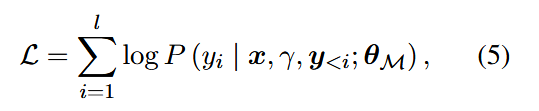
在 Loss 中,y 表示被压缩的 CoT 序列,
为了保留 LLM 的推理能力,作者还在训练数据中包含部分原始 CoT 轨迹,并将 γ 设置为 1。
推理#
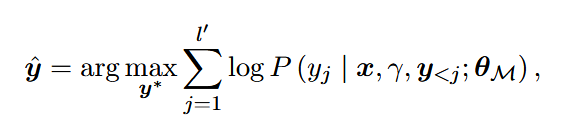
实验#
LLM:LLaMA-3.1-8B-Instruct 和 Qwen2.5-Instruct
数据集:GSM8K 和 MATH-500
使用 LLMLingua-2 计算 Token 重要性,对每个训练样本,压缩比 γ 在 0.5、0.6、0.7、0.8、0.9、1.0 中随机选择
采用 LoRA 微调(秩 r 设置为 8, scaling 参数 α 设置为 16)
推理期间 max_len 对于 GSM8K 设置为 512,对于 MATH 设置为 1024
有两种 Baseline(仅对比了减少 Token 的方法,并没有对比不修改 CoT 的方法):
- 基于提示的减少(Prompt)
在输入指令中附加一个提示,例如“请减少您链式思维过程中的 50% 的词语。”
- Token 截断(Truncation)
粗暴的长度截断,其中输出标记的最大数量受到限制,将链式思维输出压缩到固定的比率
评估采用 Acc(模型性能是通过 DeepSeek-Math2 的脚本进行评估的)、Token 数量和推理时长。除了这些指标,作者还报告 CoT 的实际压缩比,以评估压缩是否符合指定的比率。
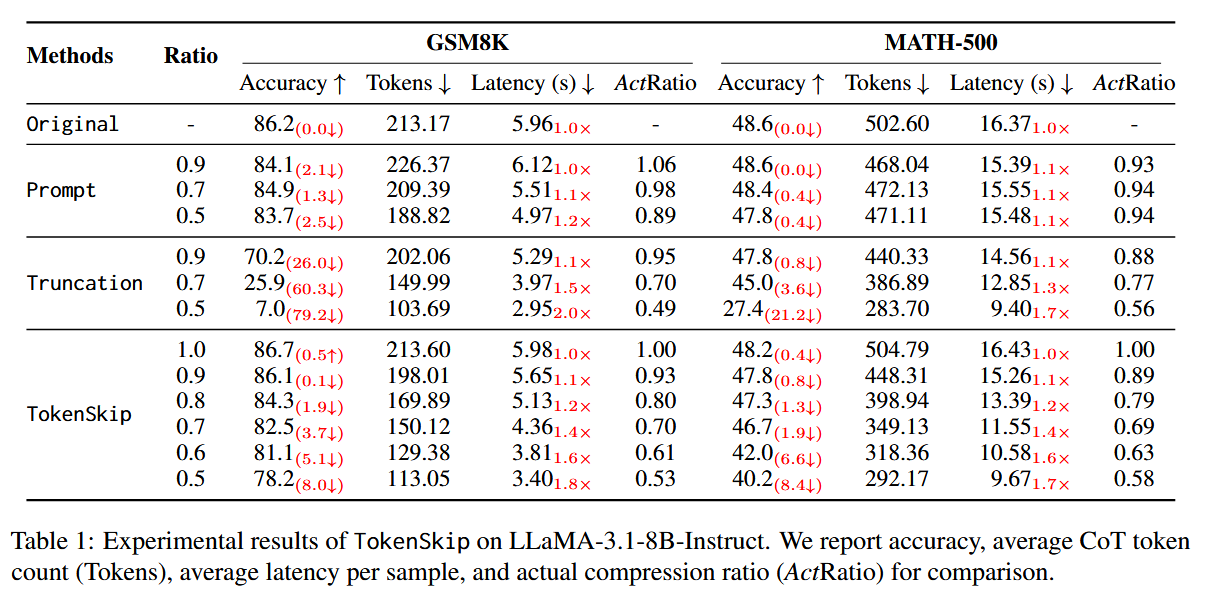
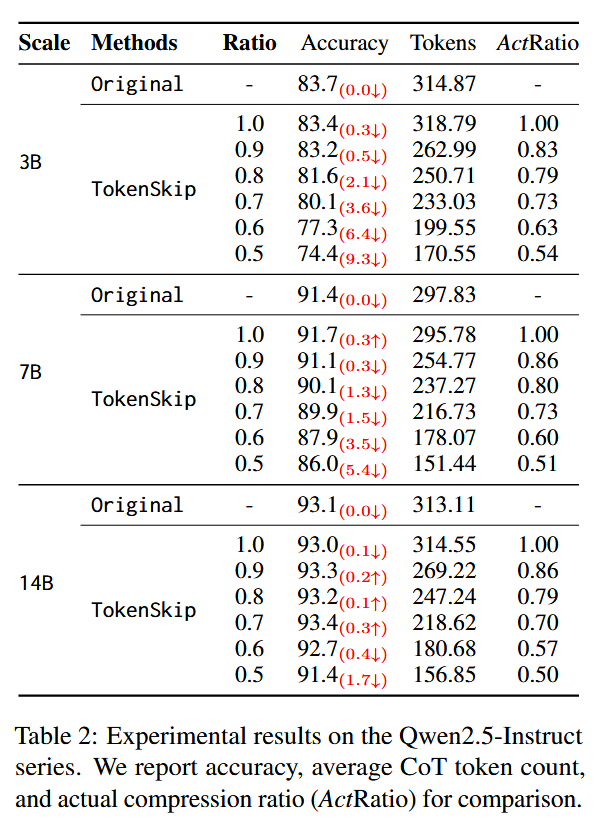
模型参数越大,压缩对性能影响越小:
值得注意的是,Qwen2.5-14B-Instruct 在 40% 标记修剪时几乎没有性能下降(低于 0.4%)。即使在 0.5 的压缩比下,该模型仍然保持强大的推理能力,仅有 2% 的性能下降。
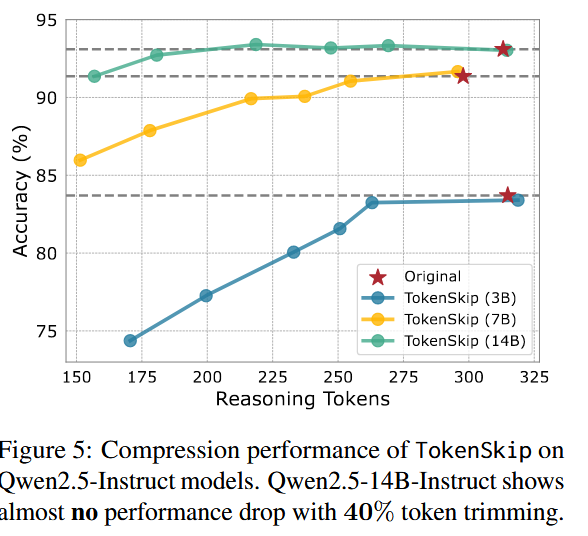
除了表中所说的几个压缩率,作者还测试了更多压缩率 0.3 0.4 这种,发现模型不愿意遵守压缩率了,仅保持在 0.5 的压缩率水平
Limitation#
- 更有效的 CoT 压缩
我们还将 GPT-4o 作为强有力的 token 重要性度量进行比较。具体而言,对于给定的 CoT 轨迹,我们提示 GPT-4o 剪除冗余 token,按照指定的压缩比,在不添加任何额外 token 的情况下进行。此外,我们要求 GPT-4o 建议 CoT 轨迹的最佳压缩格式,在下图中称为 GPT-4o-Optimal。我们利用 GPT-4o 生成的所有训练数据来训练 TokenSkip 的一个变体。我们使用 “[optimal]” token 来提示模型,从而获得 GPT-4o-Optimal 的结果。
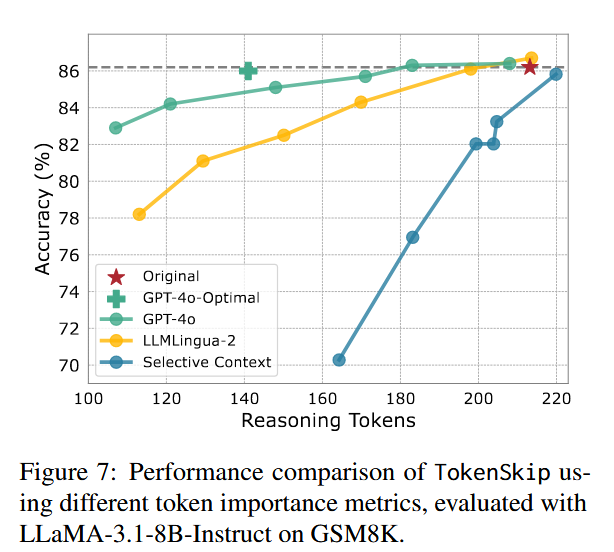
GPT-4o-Optimal 意味着还会有更强大的 CoT 压缩器(LLMingua-2 和实验中使用的是 BERT)
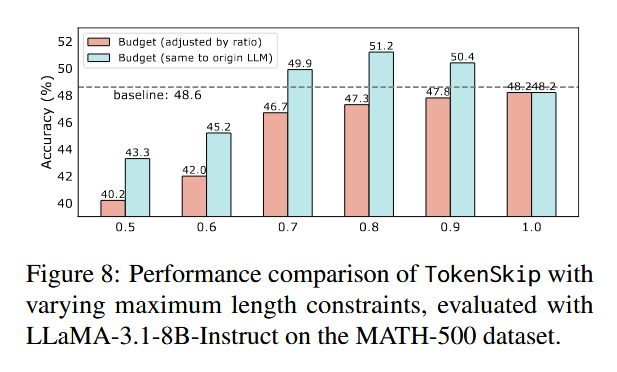
- 暴力 Budget 对性能的影响
我们在评估 MATH-500 上的 TokenSkip 时,将 max_len 设置为 max_len×γ,以确保压缩比率的公平比较。然而,这种暴力长度截断不可避免地会影响 LLM 的推理性能,因为 LLM 无法完成完整生成。具体而言,我们在与原始 LLM 相同的长度预算下(例如,MATH-500 的 1024)评估 TokenSkip。实验结果如下图所示,与通过压缩比率调整的长度预算相比,TokenSkip 在此长度预算下的性能显著提升。
- 未对更大的模型(32B 及以上)进行实验 + 未测试推理模型
附录中一些有意思的点#
CoT 恢复:#
对 LLaMA-3.1-8B-Instruct 的 Prompt:
Could you please recover the following compressed Chain-of-Thought output of a mathematical question to its original full content?
The question is: Marcus is half of Leo’s age and five years younger than Deanna. Deanna is 26. How old is Leo?
The compressed Chain-of-Thought: break down Deanna 26 Marcus five years younger 26 - 5 21 Marcus half Leo’s age Leo twice Marcus’s age Marcus 21, Leo’s age 2 x 21 = 42.
Original Full Chain-of-Thought:

GPT-4o 的恢复结果:

实现细节#
在每个数据集上训练了 3 个 epoch,peak learning rate 设置为 5e-5,学习率 schuduler 使用 cosine decay,使用 AdamW 优化器,warmup-ratio 设置为 0.1,施压 LLaMA-Factory 训练
Qwen2.5-Instruct 家族的实验结果#