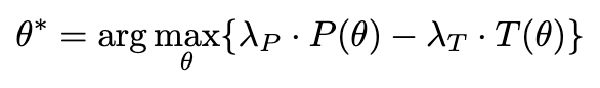
TriangleMix:无损且高效的用于预填充阶段的注意力模式#
TriangleMix: A Lossless and Efficient Attention Pattern for Long Context Prefilling
摘要#
LLM 依赖于注意力机制,其时间复杂度随着输入序列长度的增长而呈二次方增长,从而在 Prefilling 阶段产生显著的计算瓶颈。现有的静态稀疏注意力方法通常会降低准确率,而动态稀疏方法则由于在运行时需要估计稀疏索引而引入了额外的计算开销。为了解决这些局限性,我们提出 TriangleMix,一种无需训练的静态注意力模式。TriangleMix 在浅层中使用密集注意力,并在深层中切换为三角形形状的稀疏模式。大量实验表明,在深层中 TriangleMix 可将注意力开销减少 3.7 倍至 15.3 倍,并在不牺牲模型准确率的前提下,对于长度从 32K 到 128K 的序列,整体首次生成延迟(Time-to-First-Token, TTFT)减少了 12% 至 32%。此外,TriangleMix 可以与动态稀疏方法无缝结合,从而实现进一步加速,例如在 128K 序列长度下使 MInference 加速 19%,凸显了其提升 LLM 推理效率的潜力。
Motivation#
先前研究揭示,Attention 计算是 LLM Prefilling 阶段的关键瓶颈(Jiang et al., 2024a; Lai et al., 2025)
现有的静态和动态稀疏注意力方法存在不足
- 静态稀疏注意力在长上下文中表现不佳(如 StreamingLLM(Xiao 等,2023))将计算复杂度从 O(N²) 降低至 O(N),但在长上下文任务中会带来明显的性能下降(Li 等,2024a)
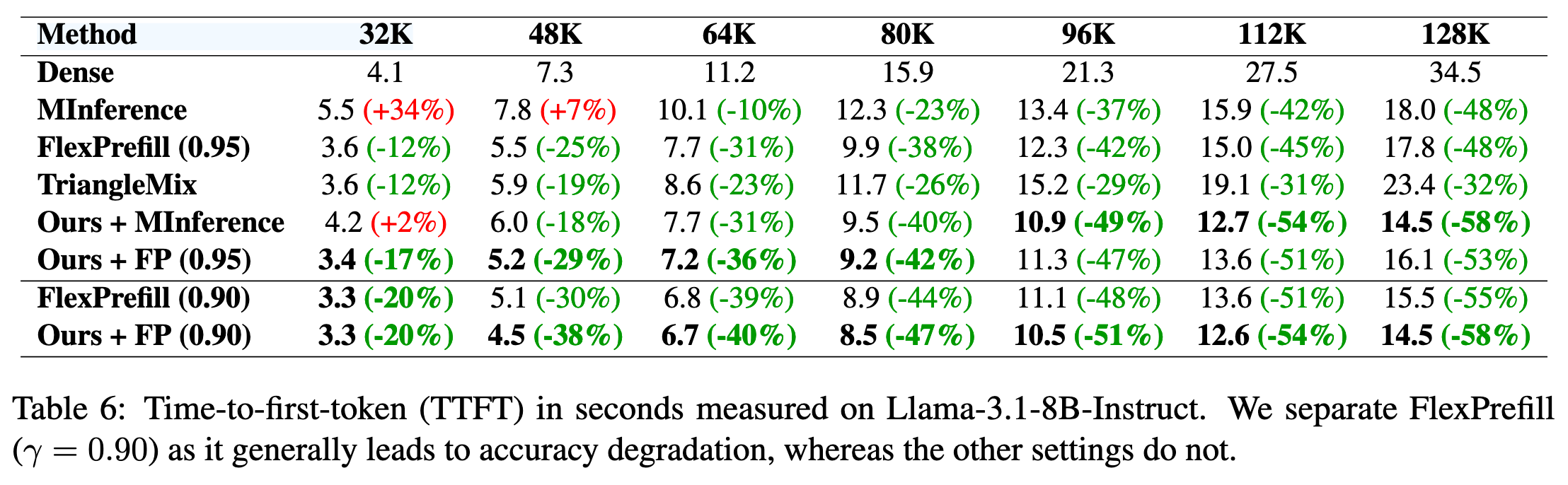
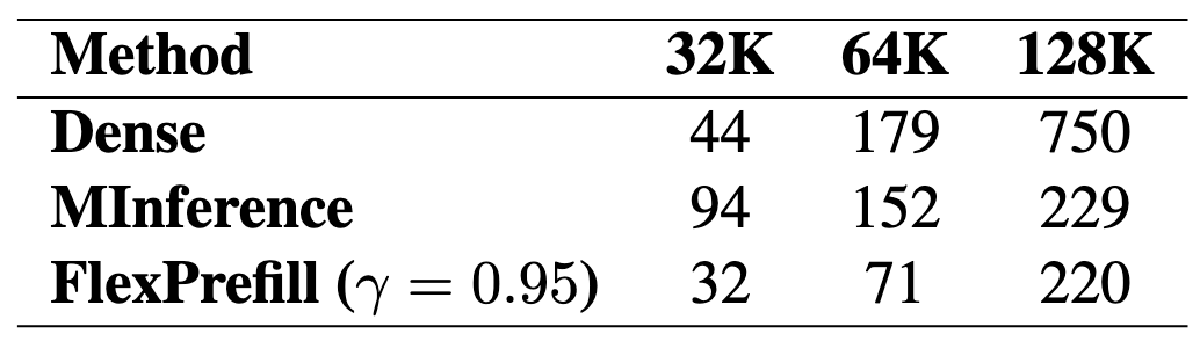
- 动态稀疏方法(如 MInference(Jiang 等,2024a)和 FlexPrefill(Lai 等,2025))旨在通过在推理过程中动态计算稀疏注意力索引。动态稀疏性方法在处理极长上下文(例如,超过 128K token)时是有效的。然而,由于在运行时需要估计稀疏块索引,它们会带来额外的开销。虽然这一开销在上下文非常长时可以忽略不计。但是如果上下文在 32K to 128K 时就有问题,这些开销无法忽略,如下表,MInference 在 32k 上下文是消耗时间比 Dense 更长,而 FlexPrefill 仅实现了 1.4x 的加速
所以作者希望开发一种静态注意力模式,以有效加速各种上下文长度下的预填充阶段。为实现该目标,我们提出了一种基于梯度的全新方法,用于识别注意力图中的关键部分。
方法#
稀疏注意力#
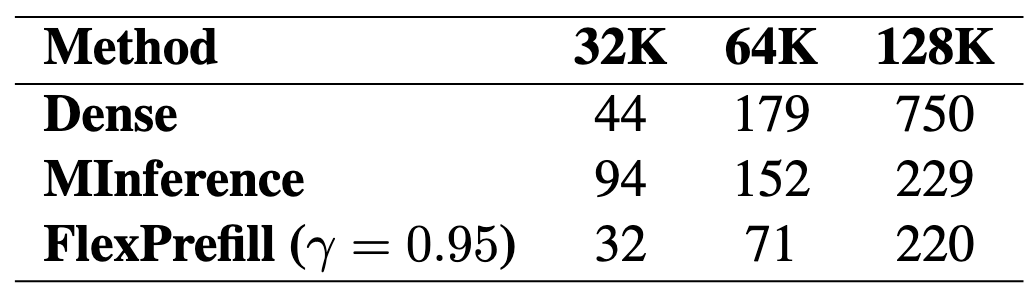
原版的注意力:
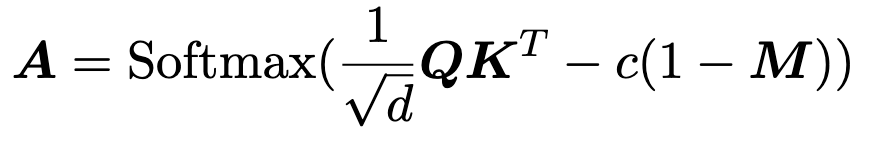
M 是一个因果 mask 矩阵,是一个 01 矩阵
QKV 的 shape 为(N, d),则 M 的 shape 为(N,N),c 是一个巨大的正常数以确保前面计算的数据可以被 Mask 掉
稀疏注意力则是通过找出一个稀疏 mask M‘来加速计算,M‘ mask 掉的数据比 M 多,所以计算少,所以快
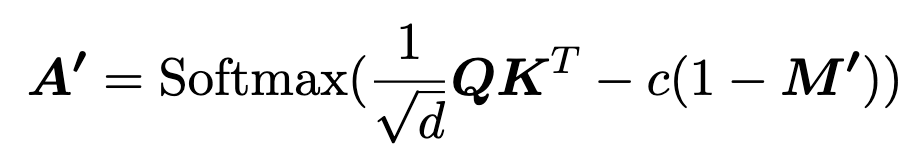
并确保 |A-A’| 不会太大,以保证性能
现有的稀疏注意力方法分为两类:静态稀疏性和动态稀疏性。在静态稀疏性中,稀疏掩码 M ′ 是固定的,不依赖于输入。例如,StreamingLLM 表明,大多数注意力分数集中在前几个 sink token 以及滑动窗口中的邻近 token 上(Xiao 等,2023)。这导致了下图绿色的 mask(只计算绿色),但是长上下文中性能下降显著
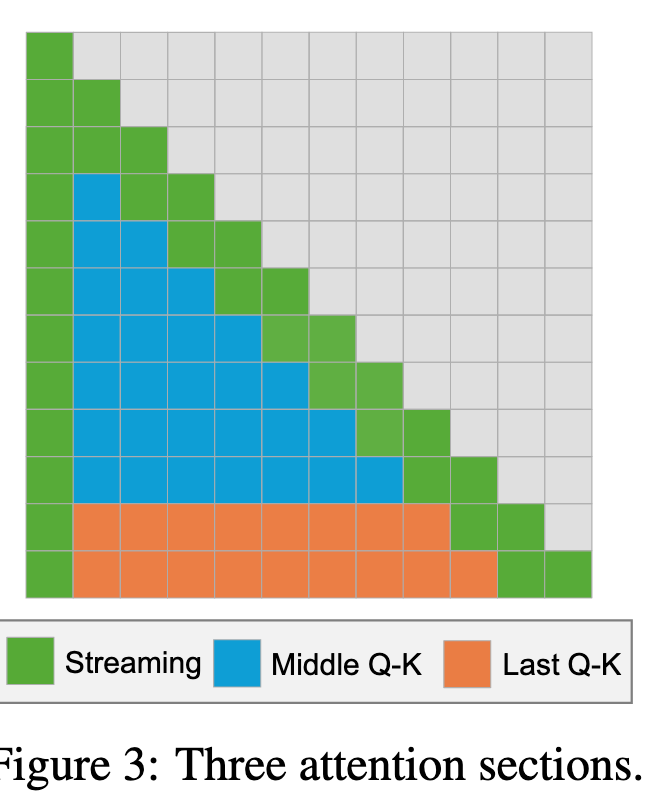
而动态稀疏注意力就是基于 QK 估算 M‘,往往有较高性能且长上下文中优势显著,但是对于中短上下文则不能提高较高的加速效果、甚至反而不如稠密注意力快
对于注意力的分类#
作者为了分析 Attention,将注意力分为下面三类:
- 流式部分:包含注意力下沉的(attention sink)和滑动窗口(sliding window);
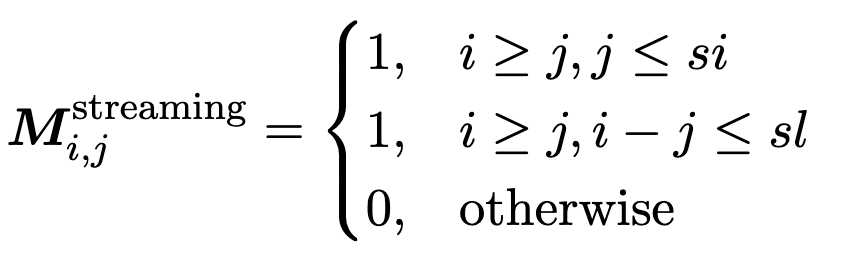
其中 si 表示 sink token 的数量,sl 表示滑动窗口的大小。
- 最后一个 Q-K 部分:涵盖 Q 的最后一部分与 K 之间的交互,不包括 Streaming 部分;
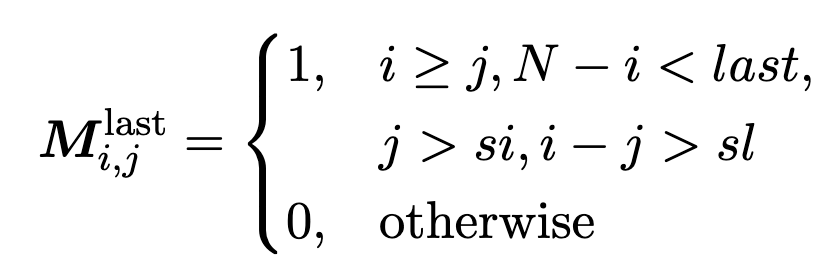
其中 last ≥ 1 指定了对应于最后一节的行数
- 中间 Q-K 部分:由 Q 和 K 中间部分之间剩余的交互组成。
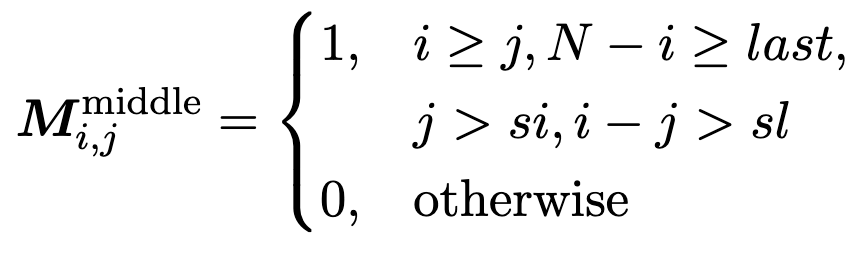
对注意力的分析#
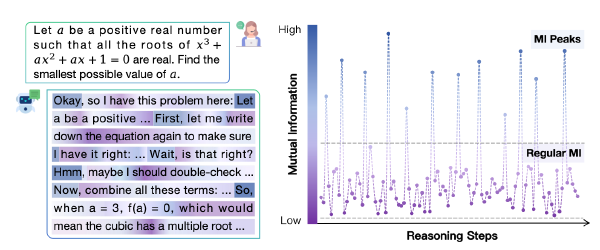
作者发现 M_middle 和 M_last 所保留的两个部分的注意力得分是相近的,尽管两者都明显低于在 M_streaming 中观察到的平均得分。为了更精确地衡量这些部分的相对重要性,作者引入了一种新的基于梯度的探测技术。
作者设定了一个探测变量 \(\theta\),形状为 层数 x 输入的 Token 数 x 输入的 Token 数,最开始所有元素都设置为 1,然后修改每层原有的注意力如下:
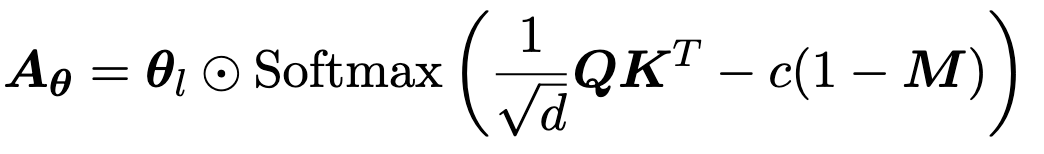
然后取出 ground truth 对应的 token 的 logits(如果 ground truth 有多个 token,则计算 ground truth 的第一个 token),并计算
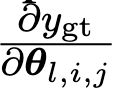
以探测哪些层的哪些 Attention 对于 ground truth 的 token 的影响最大
作者随机生成了 100 个样本,并设置 sink token 的数量(sink)为 64,滑动窗口大小(sl)为 128,并且最后注意力段的长度(last)也设置为 128。每个输入序列大约包含 2000 个 token。以计算每个区域的 attention 的重要性
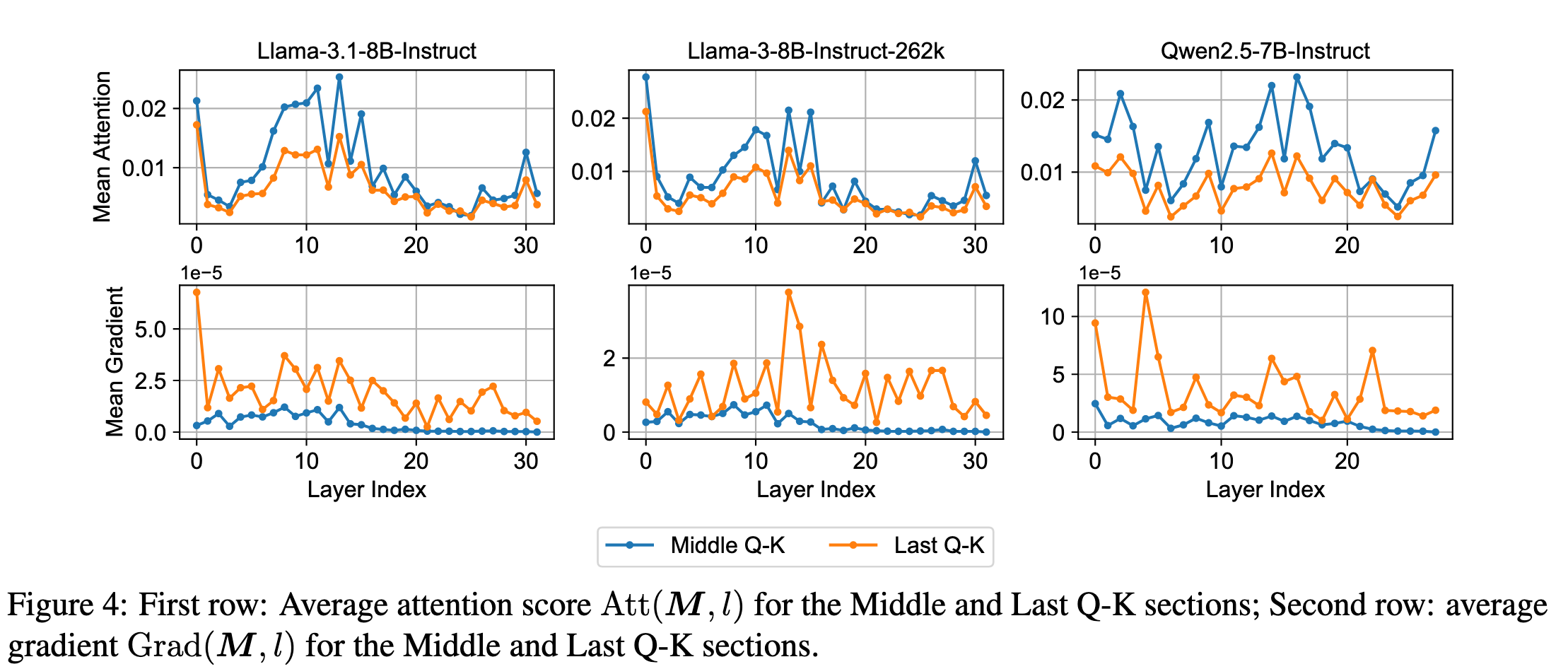
观察图像可知,尽管 Middle Q-K 在平均注意力分数上比 Last Q-K 更高,但是 ground truth 对于 Last Q-K 更敏感(因为平均梯度大),且 Middle 的梯度在早期层比较高,在中后期层就逐渐降低。
因此作者提出假设,可以在后期层中跳过 Middle QK 的计算,仅计算一个直角三角形的 Attention 的就可以
这种方法还可以同时在浅层中应用其他稀疏注意力算法进一步加速计算
作者提到,三角注意力最早由(Li 等,2024a)提出,但是 Li 对于所有层都施加了三角注意力,最后性能显著下降
实验#
模型:Llama-3.1-8B-Instruct(128K 上下文)、Llama-3-8B-Instruct-262K、Qwen2.5-7B-Instruct(128K)
baseline:
- 静态稀疏注意力:Streaming(一种 A 形的 Mask, 设置超参数 si = 8 and sl = 512)、Triangle 注意力(si = 8, sl = 512, and last = 128)、StremingMix,(对于层数 l ≤ Ltri_start 的层使用密集 Attention,而对于更深的层则使用流 Streaming)、DuoAttention(给每个 Head 设置一个 Mask 矩阵,但是在 Qwen 上训练不收敛,所以未汇报 DuoAttention+Qwen)
- 动态稀疏注意力:MInference 和 FlexPrefill(γ = 0.90 and γ = 0.95.)
超参数:为 Llama-3-18B-Instruct 和 Llama-3-8B-Instruct-262K 设置 Ltri_start = 16,而为 Qwen2.5-7B-Instruct 设置 Ltri_start = 20。作者的方法中的 Triangle 注意力的超参数与 baseline 中一致
Acc:
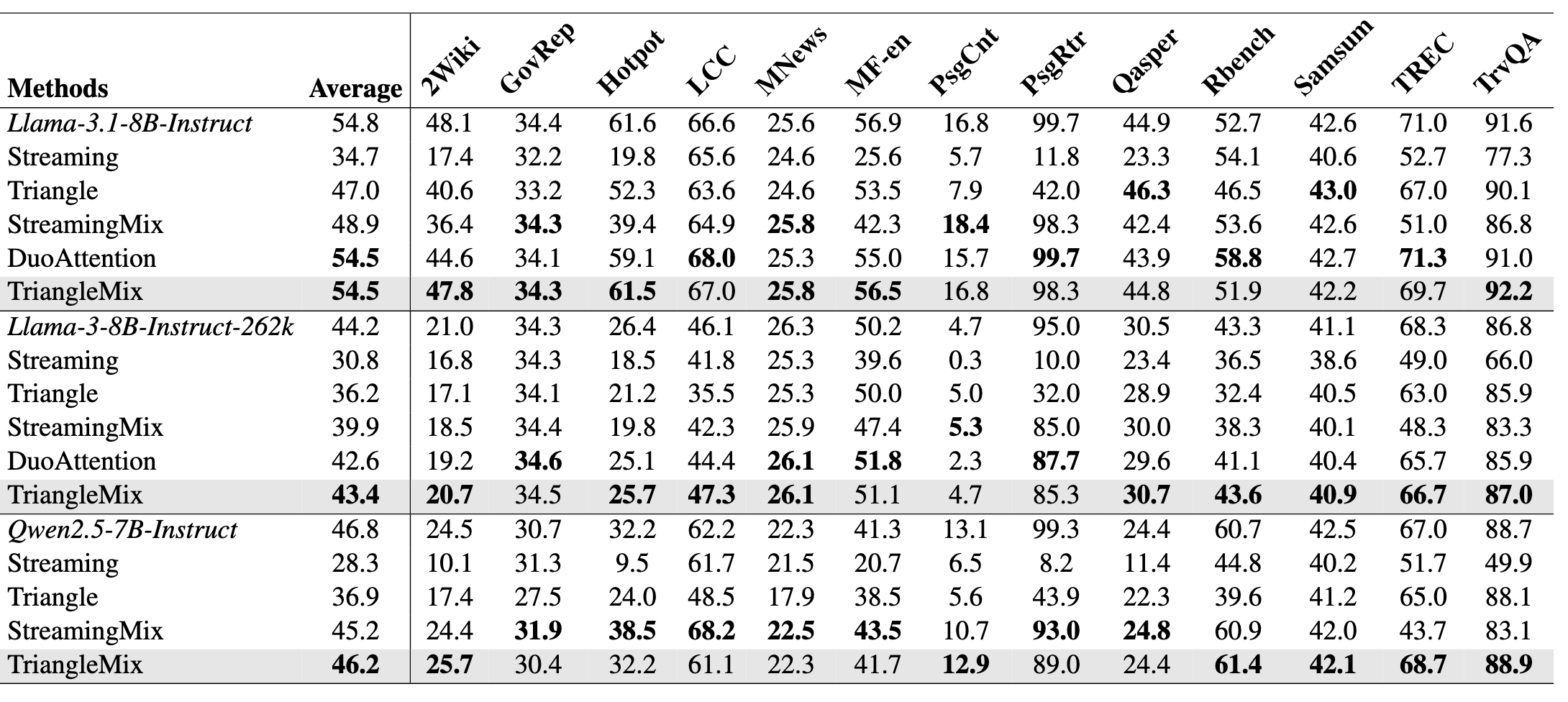
首 Token 时间: